
Μπορούν οι διωκτικές αρχές να έχουν νόμιμη πρόσβαση στο περιεχόμενο των συνομιλιών μου στα social media;
Του Ευάγγελου Φαρμακίδη*
Η ανάπτυξη της τεχνολογίας και η εξάπλωση του Διαδικτύου δημιούργησαν πολλά οφέλη για την οικονομία και την κοινωνία. Σήμερα σε έναν μεγάλο βαθμό η οικονομική ανάπτυξη και η κοινωνική ευημερία βασίζονται στις νέες τεχνολογίες και σε καινοτόμες υπηρεσίες, όπως είναι τα μέσα κοινωνικής δικτύωσης και επικοινωνίας. Ταυτόχρονα όμως, ολοένα και περισσότεροι δράστες σοβαρών ή και λιγότερο σοβαρών εγκληματικών πράξεων, εγκληματικές ομάδες, αλλά και τρομοκρατικές οργανώσεις κάνουν χρήση των πλεονεκτημάτων που προσφέρουν οι νέες τεχνολογίες, προκειμένου να διευκολύνουν την τέλεση των πράξεων τους.
Όταν συμβαίνει αυτό οι διωκτικές αρχές πρέπει να έχουν τη δυνατότητα πρόσβασης στο περιεχόμενο της επικοινωνίας συγκεκριμένων ανθρώπων. Η άρση του απορρήτου της επικοινωνίας, που πραγματοποιείται μέσω των εθνικών «παραδοσιακών» παρόχων υπηρεσιών, όπως για παράδειγμα οι εταιρίες σταθερής και κινητής τηλεφωνίας, με σκοπό την εξιχνίαση εγκλημάτων, είναι μια συχνή και συνήθης πρακτική.
Τι συμβαίνει όμως με τις over-the-top (OTT) υπηρεσίες και εφαρμογές [1];
Ο διεθνής χαρακτήρας του Διαδικτύου επιτρέπει σε μια εταιρία παροχής υπηρεσιών να παρέχει τις υπηρεσίες της οπουδήποτε στον κόσμο και σε πολλά κράτη ταυτόχρονα, χωρίς όμως να έχει απαραίτητα εταιρική παρουσία, προσωπικό ή εγκαταστάσεις [π.χ. διακομιστές (servers) κ.α.] στα κράτη αυτά. Επιπλέον, τα δεδομένα που παράγονται από τη χρήση της υπηρεσίας δύναται να αποθηκεύονται σε οποιοδήποτε μέρος του κόσμου, καθιστώντας ιδιαίτερα δύσκολη έως αδύνατη την πρόσβαση από τις διωκτικές αρχές άλλων κρατών σε αυτά.
Μόνο το έτος 2016 στάλθηκαν από τις Ευρωπαϊκές διωκτικές αρχές 120.000 αιτήματα δικαστικής συνεργασίας στους αμερικανικούς κολοσσούς Apple, Facebook, Google, Microsoft και Twitter.
Επί του παρόντος δύο τρόποι υπάρχουν προκειμένου οι διωκτικές αρχές να έχουν πρόσβαση σε αυτά:
-η πρώτη οδός είναι η οδός της δικαστικής συνεργασίας μεταξύ των κρατών που βασίζεται σε διμερείς ή πολυμερείς συμφωνίες [2], όπου οι διωκτικές αρχές ενός κράτους ζητούν από τις αντίστοιχες αρχές του κράτους, όπου βρίσκονται τα δεδομένα, τη λήψη και τη γνωστοποίηση αυτών.
Η οδός αυτή έχει αποδειχθεί εξαιρετικά χρονοβόρα με αποτέλεσμα πολλές φορές, μέχρι να εξεταστεί το επίμαχο αίτημα, τα ζητούμενα δεδομένα να έχουν μεταφερθεί σε άλλο κράτος ή ακόμα και να έχουν διαγραφεί. Έτσι, στην πρώτη περίπτωση, απαιτείται ένα νέο αίτημα δικαστικής συνεργασίας στις δικαστικές αρχές του κράτους, όπου έχουν ήδη μεταφερθεί τα δεδομένα κ.ο.κ., καταλήγοντας συχνά σε μια ατέρμονη διαδικασία. Εξάλλου, δεν έχουν συμβληθεί όλα τα κράτη με τέτοιου είδους συμφωνίες. Συνεπώς, αν τα δεδομένα βρίσκονται σε ένα μη συμβαλλόμενο κράτος, είναι εξ αρχής αδύνατη η πρόσβαση σε αυτά.
– δεύτερη οδός αφορά την απευθείας επικοινωνία των διωκτικών αρχών με τις ίδιες τις εταιρίες παροχής υπηρεσιών (π.χ. Apple, Facebook, Google, Microsoft, Twitter κ.α.) και τη γνωστοποίηση από τις τελευταίες των ζητουμένων δεδομένων.
Η οδός αυτή είναι σαφέστατα γρηγορότερη, συχνά όμως όχι αρκετά γρήγορη, λόγω του ιδιαίτερα ευμετάβλητου χαρακτήρα των ψηφιακών δεδομένων. Επιπλέον, βασικό μειονέκτημα αποτελεί το γεγονός ότι η γνωστοποίηση είναι συνήθως προαιρετική και βασίζεται στην διακριτική ευχέρεια της εκάστοτε εταιρίας και στην εσωτερική πολιτική που αυτή ακολουθεί, ενώ απαγορεύεται η γνωστοποίηση δεδομένων περιεχομένου (ηχητικά και γραπτά μηνύματα, εικόνες, βίντεο κ.α.). Ακόμα και όταν οι εταιρίες απαντούν στα αιτήματα αυτά, είναι σε θέση να παρέχουν στις αρχές μόνο δεδομένα συνδρομητή και μεταδεδομένα της ηλεκτρονικής επικοινωνίας, [3] όπως το όνομα, η διεύθυνση IP, η γεωγραφική θέση, το είδος της συσκευής, η διάρκεια σύνδεσης, η ώρα αποστολής ενός μηνύματος ή πραγματοποίησης μιας κλήσης, ενώ τα δεδομένα που αφορούν το περιεχόμενο προστατεύονται αυστηρότερα από τον Νόμο.
Η δεύτερη οδός, της απευθείας επικοινωνίας με τις εταιρίες, χωρίς τη μεσολάβηση των διωκτικών αρχών των ΗΠΑ, έχει επικρατήσει όσον αφορά τα αιτήματα των Ευρωπαϊκών αρχών προς τις ΗΠΑ.
Είναι χαρακτηριστικό ότι μόνο το έτος 2016 στάλθηκαν από τις Ευρωπαϊκές διωκτικές αρχές 120.000 αιτήματα δικαστικής συνεργασίας στους αμερικανικούς κολοσσούς Apple, Facebook, Google, Microsoft και Twitter.
Σήμερα, η εξέταση των αιτημάτων αυτών διαρκεί περίπου 10 μήνες και, όπως προαναφέρθηκε, η απάντηση είναι προαιρετική, βασίζεται δηλαδή στην διακριτική ευχέρεια της εκάστοτε εταιρίας και στην εσωτερική πολιτική που ακολουθεί, ενώ καλύπτει μόνο τα δεδομένα που δεν αφορούν το περιεχόμενο, δεν καταλαμβάνει δηλαδή το περιεχόμενο των συνομιλιών, γραπτών ή προφορικών.
Οι εταιρίες αυτές, που εδρεύουν στις ΗΠΑ, διέπονται από το νομοθετικό πλαίσιο των ΗΠΑ και συγκεκριμένα από τον νόμο περί Ηλεκτρονικών Επικοινωνιών και Προστασίας της Ιδιωτικής Ζωής του 1986 (Electronic Communications and Privacy Act 1986 — ECPA).
Με αφορμή την υπόθεση United States v. Microsoft Corp [3] επήλθε μια πολύ σημαντική νομοθετική μεταρρύθμιση στον αμερικανικό νόμο για τα Αποθηκευμένα Δεδομένα Επικοινωνιών (Stored Communications Act – SCA) [4].
Στις 23 Μαρτίου 2018 εκδόθηκε από το Κογκρέσο των Ηνωμένων Πολιτειών της Αμερικής ο νόμος Clarifying Lawful Use of Overseas Data (CLOUD) Act, για την αποσαφήνιση της νόμιμης χρήσης δεδομένων στο εξωτερικό. Ο στόχος ήταν διπλός, αφενός η αποσαφήνιση της πρόσβασης των αμερικανικών αρχών επιβολής του Νόμου σε δεδομένα που βρίσκονται στο εξωτερικό και αφετέρου η δημιουργία ενός μηχανισμού για τις αλλοδαπές κυβερνήσεις, ώστε να έχουν πρόσβαση σε δεδομένα που είναι αποθηκευμένα στις ΗΠΑ.
Πιο συγκεκριμένα, ο νέος νόμος CLOUD Act προβλέπει την υποχρέωση των εταιριών, που έχουν την έδρα τους στις ΗΠΑ, να συμμορφώνονται με εντολές αρχών των ΗΠΑ για γνωστοποίηση τόσο “δεδομένων περιεχομένου”, όσο και “δεδομένων που δεν αφορούν το περιεχόμενο”, ανεξάρτητα από τον τόπο αποθήκευσης των δεδομένων αυτών, συμπεριλαμβανομένης της Ευρωπαϊκής Ένωσης.
Παρότι όμως ο νόμος CLOUD Act παρέχει πλέον στις αμερικανικές διωκτικές αρχές τη δυνατότητα να ζητούν και να λαμβάνουν δεδομένα κάθε είδους, άρα και το περιεχόμενο των συνομιλιών, από εταιρίες που έχουν την έδρα τους στις ΗΠΑ, ακόμα και αν τα δεδομένα βρίσκονται αποθηκευμένα σε άλλα κράτη, όπως για παράδειγμα στην Ευρωπαϊκή Ένωση, το Ευρωπαϊκό νομοθετικό πλέγμα για την προστασία των δεδομένων προσωπικού χαρακτήρα και ειδικότερα ο Γενικός Κανονισμός Προστασίας Δεδομένων (General Data Protection Regulation – GDPR) [4] [5] δρα προστατευτικά για τους Ευρωπαίους πολίτες, απαγορεύοντας στις εταιρίες να γνωστοποιούν προσωπικά δεδομένα Ευρωπαίων πολιτών σε αρχές επιβολής του Νόμου άλλων κρατών, χωρίς την προηγούμενη ύπαρξη διμερούς ή πολυμερούς διεθνούς συμφωνίας, όπως για παράδειγμα σύμβαση αμοιβαίας δικαστικής συνδρομής.
Ταυτόχρονα, ο νέος νόμος εξουσιοδοτεί την εκτελεστική εξουσία των ΗΠΑ να συνάπτει συμφωνίες με ξένες κυβερνήσεις, όπως για παράδειγμα τις κυβερνήσεις των Κρατών-Μελών της Ευρωπαϊκής Ένωσης, σύμφωνα με τις οποίες οι ξένες κυβερνήσεις μπορούν να αποκτήσουν ταχεία πρόσβαση στα δεδομένα, που διατηρούνται εντός της επικράτειας των ΗΠΑ.
Μια τέτοια συμφωνία διαπραγματεύονται επί του παρόντος η Ευρωπαϊκή Ένωση και οι ΗΠΑ. Την 6η Ιουνίου 2019 το Συμβούλιο της Ευρωπαϊκής Ένωσης εξέδωσε δύο αποφάσεις, σύμφωνα με τις οποίες εξουσιοδοτεί την Ευρωπαϊκή Επιτροπή να διαπραγματευθεί εκ μέρους της ΕΕ συμφωνία με τις ΗΠΑ σχετικά με τη διασυνοριακή πρόσβαση σε ηλεκτρονικά αποδεικτικά στοιχεία στο πλαίσιο της δικαστικής συνεργασίας σε ποινικές υποθέσεις, όπως επίσης να διαπραγματευθεί και το Δεύτερο Πρόσθετο Πρωτόκολλο της Σύμβασης της Βουδαπέστης [5]. Οι συμφωνίες αυτές θα καθορίσουν τις προϋποθέσεις για την πρόσβαση των διωκτικών αρχών τρίτων χωρών στα δεδομένα των Ευρωπαίων Πολιτών σε ποινικές διαδικασίες στο μέλλον.
Σε Ευρωπαϊκό επίπεδο, η Ευρωπαϊκή Επιτροπή ενέκρινε στις 17 Απριλίου 2018 δύο νομοθετικές προτάσεις: την Πρόταση Κανονισμού σχετικά με την ευρωπαϊκή εντολή υποβολής και την ευρωπαϊκή εντολή διατήρησης ηλεκτρονικών αποδεικτικών στοιχείων σε ποινικές υποθέσεις [6] και την Πρόταση Οδηγίας σχετικά με τη θέσπιση εναρμονισμένων κανόνων για τον ορισμό νόμιμων εκπροσώπων με σκοπό τη συγκέντρωση αποδεικτικών στοιχείων στο πλαίσιο ποινικών διαδικασιών, η οποία συμπληρώνει τον παραπάνω Κανονισμό. Σκοπός των νομοθετικών αυτών προτάσεων είναι να εξασφαλιστεί η ταχύτατη διασυνοριακή πρόσβαση των Ευρωπαϊκών διωκτικών αρχών στα ηλεκτρονικά αποδεικτικά στοιχεία σε ποινικές υποθέσεις, ακόμα και όταν αυτά βρίσκονται αποθηκευμένα εκτός της Ευρωπαϊκής Ένωσης.
Το πλαίσιο αυτό θα εξασφαλίσει την έγκαιρη πρόσβαση σε ηλεκτρονικά αποδεικτικά στοιχεία συντομεύοντας σε 10 ημέρες το χρονικό διάστημα για την παροχή των ζητούμενων δεδομένων, διαδικασία που επί του παρόντος διαρκεί κατά μέσο όρο 10 μήνες. Σήμερα, τόσο η Πρόταση Κανονισμού όσο και η Πρόταση Οδηγίας εκκρεμούν στο στάδιο της πρώτης ανάγνωσης, σύμφωνα με τη συνήθη νομοθετική διαδικασία.
Η πρόσβαση των αρχών αναμένεται να γίνει υποχρεωτική για τις εταιρίες εφόσον αυτές παρέχουν τις υπηρεσίες τους εντός της ΕΕ.
Συμπερασματικά, επί του παρόντος, οι αμερικανικές διωκτικές αρχές δεν μπορούν να αποκτήσουν νόμιμα πρόσβαση στο περιεχόμενο των συνομιλιών μας σε υπηρεσίες, όπως το Facebook και το WhatsApp, παρά μόνο μέσω ειδικής συμφωνίας αμοιβαίας δικαστικής συνδρομής, όπως αυτή που διαπραγματεύονται τώρα ΕΕ και ΗΠΑ.
Από την άλλη, οι ευρωπαϊκές αρχές, μετά τη θέσπιση του νόμου CLOUD Act μπορούν να αποκτήσουν πρόσβαση στο περιεχόμενο των συνομιλιών απευθείας από εταιρία που εδρεύει στις ΗΠΑ προαιρετικά, μόνο όταν η εταιρία κρίνει ότι συντρέχει κίνδυνος θανάτου ή σοβαρής βλάβης της υγείας του Υποκειμένου των δεδομένων.
Η πρόσβαση των αρχών, ακόμα και στα δεδομένα περιεχομένου, αναμένεται να γίνει υποχρεωτική για τις εταιρίες, εφόσον αυτές παρέχουν τις υπηρεσίες τους εντός της ΕΕ, μετά την ψήφιση και την έναρξη ισχύος του Κανονισμού για τα ηλεκτρονικά αποδεικτικά στοιχεία σε ποινικές υποθέσεις και τέλος, διαμέσου συμφωνίας αμοιβαίας δικαστικής συνδρομής, όπως αυτή που διαπραγματεύονται τώρα ΕΕ και ΗΠΑ ή του υπό διαπραγμάτευση Δευτέρου Πρόσθετου Πρωτοκόλλου της Σύμβασης της Βουδαπέστης για το Κυβερνοέγκλημα.
*Ο Ευάγγελος Φαρμακίδης είναι τακτικό μέλος της Homo Digitalis, ασκούμενος δικηγόρος, τελειόφοιτος του ΔΠΜΣ «Δίκαιο και Πληροφορική» του Τμήματος Εφαρμοσμένης Πληροφορικής, ΠαΜακ και της Νομικής Σχολής, ΔΠΘ, μεταπτυχιακός φοιτητής Ποινικού Δικαίου και Εγκληματολογικών Επιστημών στη Νομική Σχολή, ΔΠΘ, κάτοχος Διπλώματος στην Κοινωνική Οικονομία και Κοινωνική Επιχειρηματικότητα και Διαπιστευμένος Διαμεσολαβητής του Υπουργείου Δικαιοσύνης.
Παραπομπές:
[1] Ως over-the-top (OTT) χαρακτηρίζεται κάθε υπηρεσία ή εφαρμογή που παρέχεται μέσω Διαδικτύου, παρακάμπτοντας την παραδοσιακή διανομή (π.χ. μέσω καλωδίου ή δορυφόρου). Τέτοιου είδους υπηρεσίες σχετίζονται συνήθως με το ψηφιακό περιεχόμενο και τις επικοινωνίες. Χαρακτηριστικά παραδείγματα αποτελούν η Netflix, η Amazon Prime, η Hulu κ.α., οι οποίες αντικαθιστούν την “παραδοσιακή” καλωδιακή ή δορυφορική τηλεόραση και η Skype, η WhatsApp, η Viber κ.α., οι οποίες αντικαθιστούν την “παραδοσιακή” επικοινωνία μέσω καλωδίου σταθερής τηλέφωνίας ή κεραιών κινητής τηλεφωνίας.
[2] Για παράδειγμα, η Συμφωνία σχετικά με την αμοιβαία δικαστική συνδρομή μεταξύ της Ευρωπαϊκής Ένωσης και των Ηνωμένων Πολιτειών της Αμερικής, η οποία υπογράφηκε στις 25 Ιουνίου 2003 και τέθηκε σε ισχύ την 1η Φεβρουαρίου 2010.
[3] Τον Δεκέμβριο του 2013, αμερικανικές ομοσπονδιακές αρχές επιβολής του Νόμου ζήτησαν από αμερικανικό επαρχιακό δικαστήριο της Νέας Υόρκης την έκδοση ενός εντάλματος, σύμφωνα με την παράγραφο 2703 του νόμου για τα Αποθηκευμένα Δεδομένα Επικοινωνιών (Stored Communications Act – SCA), με το οποίο θα υποχρεωνόταν η Microsoft να παρέχει όλα τα μηνύματα ηλεκτρονικού ταχυδρομείου, καθώς και άλλες πληροφορίες που αφορούσαν έναν συγκεκριμένο λογαριασμό πελάτη που τηρούσε η ίδια και υπήρχαν βάσιμες υποψίες ότι χρησιμοποιήθηκε για διακίνηση ναρκωτικών ουσιών. Το ένταλμα εκδόθηκε, αλλά μετά την επίδοσή του διαπιστώθηκε ότι τα ζητούμενα δεδομένα ήταν αποθηκευμένα σε διακομιστή της Microsoft στην Ιρλανδία. Η Microsoft αμφισβήτησε το ένταλμα με την αιτιολογία ότι ένα ένταλμα που εκδίδεται σύμφωνα με τον νόμο για Αποθηκευμένα Δεδομένα Επικοινωνιών (Stored Communications Act – SCA) δεν μπορεί να υποχρεώσει Αμερικανικές εταιρίες να υποβάλουν δεδομένα που βρίσκονται αποθηκευμένα σε διακομιστές εκτός της επικράτειας των ΗΠΑ. Η εταιρία προσέφυγε στο Περιφερειακό Δικαστήριο της Νέας Υόρκης, όπου ηττήθηκε σε πρώτο βαθμό, με την απόφαση να αποφαίνεται ότι η φύση του εντάλματος που εκδίδεται σύμφωνα με τον νόμο για Αποθηκευμένα Δεδομένα Επικοινωνιών (Stored Communications Act – SCA) δεν υπόκειται σε τοπικούς περιορισμούς. Η Microsoft άσκησε έφεση κατά της παραπάνω απόφασης και δικαιώθηκε από το αρμόδιο Εφετείο της Νέας Υόρκης, το οποίο επιλήφθηκε της υπόθεσης και ακύρωσε το επίμαχο ένταλμα. Αξίζει να σημειωθεί ότι σε παρόμοιες περιπτώσεις το ίδιο Εφετείο είχε διατάξει άλλες εταιρίες (π.χ. Google) να συμμορφωθούν με τα εντάλματα, εφόσον μπορούσαν να έχουν πρόσβαση στα ζητούμενα δεδομένα από την επικράτεια των ΗΠΑ, ανεξάρτητα από την τοποθεσία αποθήκευσης των δεδομένων. Το Υπουργείο Δικαιοσύνης των ΗΠΑ προσέφυγε κατά της απόφασης του Εφετείου της Νέας Υόρκης στο Ανώτατο Δικαστήριο, το οποίο συμφώνησε να εξετάσει την υπόθεση τον Οκτώβριο του 2017. Πριν από την έκδοση της σχετικής απόφασης του Ανωτάτου Δικαστηρίου επενέβη ο Νομοθέτης με την θέσπιση του νόμου Clarifying Lawful Overseas Use of Data Act (CLOUD Act), επιλύοντας οριστικά δια της νομοθετικής οδού το θέμα που είχε ανακύψει.
[4] Ο νόμος για τα Αποθηκευμένα Δεδομένα Επικοινωνιών (Stored Communications Act – SCA) αποτελεί μέρος του νόμου περί Ηλεκτρονικών Επικοινωνιών και Προστασίας της Ιδιωτικής Ζωής του 1986 (Electronic Communications and Privacy Act 1986 — ECPA).
[5] Σύμβαση της Βουδαπέστης του Συμβουλίου της Ευρώπης για το έγκλημα στον κυβερνοχώρο (CETS αριθ. 185), η οποία υπογράφηκε στη Βουδαπέστη στις 23.11.2001, ενσωματώθηκε στην ελληνική έννομη τάξη μαζί με το Πρώτο Πρόσθετο Πρωτόκολλό της με τεράστια καθυστέρηση με τον ν. 4411/2016 (ΦΕΚ Α’ 142/3-8-2016) και αποτελεί τη βασικότερη πηγή δικαίου για το ηλεκτρονικό έγκλημα διεθνώς. Σήμερα τα συμβαλλόμενα μέρη της Σύμβασης ανέρχονται σε 62, συμπεριλαμβανομένων 26 Kρατών-Mελών της ΕΕ.
[6] Για περισσότερες πληροφορίες σχετικά με την Πρόταση Κανονισμού βλέπε το πρόσφατο, ιδιαίτερα κατατοπιστικό, εύληπτο και περιεκτικό άρθρο του συναδέλφου και μέλους της Homo Digitalis Κωνσταντίνου Ζουμπουλάκη με τίτλο “Η πρόσβαση των αρχών στα ηλεκτρονικά αποδεικτικά στοιχεία: Τι συμβαίνει με τα προσωπικά μας δεδομένα;” που δημοσιεύθηκε στην ιστοσελίδα της Homo Digitalis στον παρακάτω σύνδεσμο http://homodigitalis.gr/posts/3928

Συνέντευξη με τον Υπεύθυνο Διακυβερνητικών Σχέσεων της Symantec, Ηλία Χάντζο
Ο τίτλος του εντυπωσιάζει: “ Senior Director Government Affairs EMEA and APJ, Global CIP and Privacy Advisor” για λογαριασμό της Symantec, ηγέτιδας εταιρείας στο χώρο της κυβερνοασφάλειας.
Με άλλα λόγια, ο Ηλίας Χάντζος είναι ο άνθρωπος που αναλαμβάνει τις διακυβερνητικές σχέσεις της Symantec σχεδόν με όλα τα κράτη της υφηλίου (πλην Αμερικής) για ζητήματα κυβερνοασφάλειας και προστασίας της ιδιωτικότητας. Η Symantec είναι μία από τις μεγαλύτερες εταιρείες λογισμικού κυβερνοασφάλειας διεθνώς, με εκατοντάδες εκατομμύρια χρήστες.
Ποιός δε γνωρίζει άλλωστε το λογισμικό “Norton Internet Security”, το No 1 προϊόν της Symantec για την προστασία καταναλωτών;
Η γνωριμία μας έγινε στο πλαίσιο του Data Privacy & Protection Conference, όπου με μία ζωηρή και εναργή παρουσίαση ανέπτυξε το θέμα της γνωστοποίησης των περιστατικών παραβίασης ασφαλείας και κέρδισε τις εντυπώσεις των συμμετεχόντων. Του ζητήσαμε να μας μιλήσει για τις εξελίξεις στο χώρο και για το ρόλο των MKO. Παρά το βεβαρημένο πρόγραμμά του αποδέχτηκε με ενθουσιασμό την πρόσκλησή μας. Τον ευχαριστούμε θερμά για την πολύ ενδιαφέρουσα συζήτηση.
Στην Ελλάδα έχουν μεγαλώσει γενιές ολόκληρες στη λογική του «δικαιωματισμού» και του πολιτικώς ορθού. Η κρίση που βιώνουμε είναι και οικονομική και κρίση αξιών.
– HD: H ψήφιση του GDPR και της NIS καθιστά την Ευρώπη πρωτοπόρο στη δημιουργία ενός ολοκληρωμένου κανονιστικού περιβάλλοντος για την κυβερνοασφάλεια και την προστασία της ιδιωτικότητας. Ποιά θα είναι τα επόμενα βήματα;
HX: Αρχικά, βασικό βήμα αποτελεί η πλήρης εφαρμογή του GDPR. Κι αυτό θα γίνει με την υιοθέτηση επιμέρους κανόνων, όπως οι κατευθυντήριες οδηγίες του Ευρωπαϊκού Συμβουλίου για την προστασία των δεδομένων (EDPB), με την επιβολή προστίμων που θα λειτουργήσουν αποτρεπτικά στη μη συμμόρφωση των οργανισμών, με την επίλυση των ζητημάτων σχετικά με τη διαβίβαση των δεδομένων, ειδικά προς την Αμερική. Το τελευταίο μέχρι σήμερα αποτελεί αγκάθι για τα συμφέροντα των μεγάλων ιδιωτικών εταιρειών. Έπειτα, θα ακολουθήσουν αποφάσεις επάρκειας με άλλες χώρες, όπως η Κορέα, που θα δημιουργήσουν ένα μεγάλο χώρο ασφαλών ροών δεδομένων και, φυσικά, οι τελικές αποφάσεις γύρω από τον Κανονισμό του e-Privacy.
– HD: Μου δίνετε πολύ καλή αφορμή να σας ρωτήσω για τις προσπάθειες και τα τεράστια κεφάλαια που ακούγεται ότι δαπανούν σε επίπεδο lobbying τεχνολογικοί κολοσσοί, όπως η Apple και η Google, ώστε να εξασφαλίσουν μια πιο ευνοϊκή γι’ αυτούς διαμόρφωση του e-Privacy.
HX: Φυσικό δεν είναι οι εταιρείες να ενδιαφέρονται για νομοθετήματα που εν τέλει αφορούν και ρυθμίζουν άμεσα και τις ίδιες; Τα συμφέροντα της βιομηχανίας δεν είναι ενιαία, αλλά διαφορετικά και αντιτιθέμενα.
Αν, για παράδειγμα, ένα κανονιστικό πλαίσιο είναι ευνοϊκό για την εταιρεία Α, το ίδιο πλαίσιο θα είναι λιγότερο ευνοϊκό για την εταιρεία Β που δραστηριοποιείται σε παραπλήσιο αλλά διαφορετικό τομέα. Το ίδιο συμβαίνει και με τον e-Privacy.
«Πλακώνονται» οι εταιρείες μεταξύ τους επειδή τα συμφέροντά τους δεν είναι ενιαία. Στην Ελλάδα δεν υπάρχει συνείδηση ούτε πλήρη εικόνα του επιχειρηματικού συμφέροντος λόγω δαιμονοποίησης του κέρδους και της επιχειρηματικότητας που προκύπτει από ιδεολογικές αγκυλώσεις του παρελθόντος. Δεν πρέπει να αντιμετωπίζουμε την βιομηχανία με την ενιαία μορφή της καρικατούρας του κακού καπιταλιστή, αλλά ρεαλιστικά μέσα από το πλέγμα των περίπλοκων σχέσεων και συμφερόντων που υπάρχουν. Μόνο έτσι θα νομοθετήσουν σωστά τα όργανα. Ας δώσουμε ένα παράδειγμα που όλοι στην Ελλάδα θα καταλάβουν εύκολα. Η νομοθεσία για την ύπαρξη διπλών δεξαμενών σε ποντοπόρα τάνκερ υποτίθεται ότι προστατεύει το περιβάλλον σε περίπτωση διαρροής πετρελαίου. Μια τέτοια νομοθεσία υποστηρίζεται από τις περιβαντολλογικές ΜΚΟ και τα ναυπηγία (κατ’ εξοχήν ρυπογόνο βιομηχανία…. Βλέπετε ήδη το παράδοξο;) γιατί σημαίνει καινούργιες παραγγελίες. Θα την στηρίξουν τα παραθαλάσσια κράτη της ΕΕ δεν συμφέρει όμως την Ελλάδα (που έχει την μεγαλύτερη ακτογραμμή και μεγάλο τουρισμό) που έχει κατ’ εξοχήν ποντοπόρο ναυτιλία καθώς ανεβάζει το κόστος της ενώ δεν έχει έσοδα από τα ναυπηγία της (γιατί πλέον σχεδόν δεν υφίστανται).
Βλέπετε πόσες αντιθέσεις σε ένα παράδειγμα και ακόμη δεν μιλήσαμε για τις τοπικές κοινωνίες που έχουν υποστεί θαλάσσια μόλυνση και τη βιομηχανία τουρισμού.
– HD: Αναφερθήκατε προηγουμένως στην επιβολή προστίμων. Πρόσφατα είδαμε να επιβάλλονται πολύ υψηλά πρόστιμα σε εταιρείες όπως η Google, η Marriot, η British Airways, γεγονός που καταδεικνύει ότι ουδείς άτρωτος στο χώρο της κυβερνοασφάλειας και της προστασίας της ιδιωτικότητας. Εάν, λοιπόν, η απόλυτη προστασία και ασφαλής επεξεργασία των προσωπικών δεδομένων είναι αδύνατη ακόμα και οργανισμούς τέτοιου επιπέδου, τότε ποιο είναι το διακύβευμα; Γιατί γίνονται όλα αυτά;
HX: Τα πρόστιμα στις εταιρείες που αναφέρατε επιβλήθηκαν για διαφορετικούς λόγους. Στην περίπτωση της Google, αφορούσε τη νομιμότητα της επεξεργασίας των δεδομένων και συγκεκριμένα της συλλογής τους, ενώ στις περιπτώσεις της Marriot και της British Airways το πρόστιμο επεβλήθη λόγω ελλιπών μέτρων προστασίας των δεδομένων. Δεν υπάρχει απόλυτη ασφάλεια σε τίποτα στην ζωή, προφανώς ούτε και στην τεχνολογία. Πράγματι όμως οι αρχές έκριναν ότι οι εταιρείες αυτές θα έπρεπε να έχουν προστατέψει τα δεδομένα πολύ καλύτερα. Ωστόσο, φάνηκε ότι αυτό δεν έγινε και για αυτό επιβλήθηκαν τα πρόστιμα, που δείχνουν ότι η προστασία της ιδιωτικότητας είναι πολύ ψηλά στην ατζέντα.
– HD: Και στην Ελλάδα γιατί δεν είναι το ίδιο ψηλά;
HX: Πολλοί παράγοντες ευθύνονται. Οι ελληνικές επιχειρήσεις έως τώρα επένδυαν στα απολύτως απαραίτητα. Σε καθεστώς οικονομικής κρίσης κάνεις ό,τι μπορείς για να διατηρήσεις την εύρυθμη λειτουργία. Τα πρόσφατα πρόστιμα καλούν τις ελληνικές επιχειρήσεις που θέλουν να πουλούν στο εξωτερικό να απαντήσουν σε ένα ερώτημα που θα τους κάνουν όλοι οι αλλοδαποί πελάτες τους: «Μπορείς να προστατέψεις τα δεδομένα μου αποτελεσματικά;» Καταλαβαίνω ότι η μικρομεσαία επιχείρηση βλέπει την ασφάλεια μόνο ως κόστος. Σαν την ασφάλιση του αυτοκινήτου που μπορεί να μη χρησιμοποιήσεις ποτέ.
Ωστόσο, η ασφάλεια μπορεί να γίνει ανταγωνιστικό πλεονέκτημα. Ακόμα και αν έχουμε μείνει πίσω, η μικρομεσαία επιχείρηση είναι ανάγκη να τρέξει και να βελτιώσει την ποιότητα των προϊόντων και υπηρεσιών της. Η ποιότητα θα σε κάνει ανταγωνιστικό. Καταλαβαίνω ότι αυτή η ποιότητα θα σου αυξήσει το κόστος, αλλά στην Ευρώπη είσαι. Πρέπει να παίξεις!
– HD: Πώς βλέπετε το ρόλο των ΜΚΟ σε αυτό τον τομέα; Tί θα λέγατε σε μια οργάνωση, όπως η Homo Digitalis, ώστε η δράση της να γίνει πιο αποτελεσματική;
HX: Nα μην είστε μόνο δικαιωματιστές. Στην Ελλάδα έχουν μεγαλώσει γενιές ολόκληρες στη λογική του «δικαιωματισμού» και του πολιτικώς ορθού. Η κρίση που βιώνουμε είναι και οικονομική και κρίση αξιών. Αυτό φυσικά δεν σημαίνει ότι δεν πρέπει να αγωνιζόμαστε για τα δικαιώματα. Θα πρέπει, όμως, με κάθε νέο αίτημα που κάνουμε να γνωρίζουμε τί κερδίζουμε και τι χάνουμε. Ποιές θα είναι οι συνέπειες των επιλογών μας. Όχι απλά να ζητάμε τυφλά γιατί μπορούμε.
Είναι το λεγόμενο «ευκαιριακό κόστος». Δηλαδή, να ξέρεις όσο είναι δυνατόν ποιές είναι οι άλλες επιλογές, τις οποίες απέρριψες, προκειμένου να έχεις αυτή που τελικά επέλεξες. Δεν γίνεται, για παράδειγμα με βάσει το υπάρχον επιχειρηματικό μοντέλο, να θέλεις δωρεάν ίντερνετ χωρίς να αποδέχεσαι την ύπαρξη διαφημίσεων (σημειωτέων ούτε εμένα μου αρέσουν).
Δεν θέλεις διαφημίσεις; Κανένα πρόβλημα, είσαι διατεθειμένος να πληρώσεις για την υπηρεσία που λαμβάνεις ή για να εξασφαλίσεις το μερίδιο ιδιωτικότητας που θέλεις; Δεν είναι αρκετό να ζητάς. Έχεις και υποχρεώσεις. Δυστυχώς, είμαστε θύματα της τάσης «θέλω το Χ πάση θυσία», χωρίς όμως να έχουμε σκεφτεί τι χάνουμε ή τι αποδεχόμαστε. Είναι στοιχείο ωριμότητας και αντίστασης στο λαϊκισμό το να καταφέρουμε να διακρίνουμε τον εύκολο δικαιωματισμό από αυτό που πραγματικά μας συμφέρει. Αυτή είναι η μεγαλύτερη πρόκληση κατά την γνώμη μου για όλες τις ΜΚΟ.

Το πρώτο πρόστιμο στην Ελλάδα με βάση τον GDPR
Η απόφαση 26/2019 της Αρχής Προστασίας Δεδομένων Προσωπικού Χαρακτήρα κατά της εταιρείας PwC BS Α.Ε.
Γράφει ο Νικόλας Γανιάρης*
Α) Η κρίση της Αρχής Προστασίας Δεδομένων Προσωπικού Χαρακτήρα
Με την υπ’ αριθμ. 26/2019 απόφαση η Αρχή Προστασίας Δεδομένων Προσωπικού Χαρακτήρα (ΑΠΔΠΧ) επέβαλε για πρώτη φορά πρόστιμο εφαρμόζοντας το Γενικό Κανονισμό για την Προστασία των Δεδομένων (ΓΚΠΔ).
Η απόφαση δημοσιεύτηκε στις 30 Ιουλίου 2019.
O υπεύθυνος επεξεργασίας προσωπικών δεδομένων, δηλαδή η εταιρεία PwC BS, ζήτησε εγγράφως από τους εργαζομένους τη συγκατάθεσή τους για την επεξεργασία των προσωπικών τους δεδομένων.
Συγκεκριμένα, η εταιρεία ζήτησε τη συγκατάθεση των εργαζομένων για την επεξεργασία: α) όσων δεδομένων συνδέονταν άμεσα με τη σχέση απασχόλησης και την οργάνωση της εταιρείας και β) των δεδομένων που αποθηκεύονταν στα μέσα ηλεκτρονικής επικοινωνίας που παρείχε η εταιρεία στους εργαζομένους της.
Η εταιρεία επεδίωκε με την επεξεργασία αυτών των δεδομένων την εκπλήρωση των εξής σκοπών επεξεργασίας: α) της εκτέλεσης της σύμβασης εργασίας που είχε συνάψει με τους εργαζομένους, β) της εκπλήρωσης των υποχρεώσεων της εταιρείας που απορρέουν από την ασφαλιστική, φορολογική, εργασιακή, τελωνειακή, ευρωπαϊκή και λοιπή νομοθεσία και γ) της διασφάλισης των εννόμων συμφερόντων της εταιρείας.
Το βασικό σφάλμα της εταιρείας ήταν ότι θεμελίωσε την επεξεργασία των δεδομένων των εργαζομένων στη νόμιμη βάση της συγκατάθεσης (άρθρο 6 παρ. 1 στοιχ. α΄ ΓΚΠΔ).
Η επιλογή αυτή ήταν ακατάλληλη και παραπλανητική.
Ακατάλληλη, διότι σπανίως νοείται ελεύθερη συγκατάθεση στο πλαίσιο της σχέσης απασχόλησης, εφόσον αυτή χαρακτηρίζεται από ανισορροπία δυνάμεων ανάμεσα στον εργοδότη και τον εργαζόμενο.
Ο εργαζόμενος δηλαδή δεν μπορεί να παρέχει ελεύθερα τη συγκατάθεσή του στον εργοδότη του, καθώς γνωρίζει ότι αν δεν το κάνει αυτό ενδέχεται να έχει επιπτώσεις στην εργασία του.
Παραπλανητική, γιατί δημιούργησε στους εργαζομένους την εσφαλμένη εντύπωση ότι μπορούν να διακόψουν την επεξεργασία των προσωπικών δεδομένων ανακαλώντας τη συγκατάθεσή τους.
Περαιτέρω, η ΑΠΔΠΧ απέρριψε τον ισχυρισμό της εταιρείας ότι η συγκατάθεση των εργαζομένων αποτελούσε συμπληρωματική νομική βάση επεξεργασίας μαζί με τη νόμιμη βάση της εκτέλεσης σύμβασης εργασίας (άρθρο 6 παρ. 1 στοιχ. β΄ ΓΚΠΔ).
Η ΑΠΔΠΧ απεφάνθη ότι η αμφιταλάντευση του υπευθύνου επεξεργασίας ανάμεσα στις δύο νόμιμες βάσεις, δηλαδή ανάμεσα στη συγκατάθεση των εργαζομένων και στην εκτέλεση της σύμβασης εργασίας, καταδεικνύει την αμφιβολία του για τη νομιμότητα της επεξεργασίας.
Ο υπεύθυνος επεξεργασίας θα έπρεπε να άρει την αμφιβολία αυτή πριν από την έναρξη της επεξεργασίας.
Το δεύτερο σφάλμα της εταιρείας ήταν το γεγονός ότι ζήτησε από τους εργαζομένους να αποδεχτούν ότι τα υπό επεξεργασία δεδομένα συνδέονται με τις ανάγκες της σχέσης απασχόλησης και της οργάνωσης της εταιρείας.
Στην πραγματικότητα η ίδια η εταιρεία έπρεπε να διακρίνει τα συναφή με τους σκοπούς επεξεργασίας δεδομένα των εργαζομένων.
Υπ’ αυτό το σκεπτικό, η ΑΠΔΠΧ προέβη σε επιβολή διορθωτικών μέτρων και προστίμου 150.000 ευρώ στην εταιρεία PwC BS για την παραβίαση των κανόνων του ΓΚΠΔ.
Β) Συμπεράσματα
Η απόφαση 26/2019 της ΑΠΔΠΧ είναι σημαντική για τρεις λόγους.
Πρώτον, με την απόφαση διευκρινίζεται η έννοια της συγκατάθεσης. Η ΑΠΔΠΧ απεφάνθη ότι σπανίως μπορεί η συγκατάθεση που δίνεται στο πλαίσιο της εργασιακής σχέσης να είναι ελεύθερη.
Συνεπώς, οι επεξεργασίες των δεδομένων των εργαζομένων θα πρέπει να θεμελιώνονται στις ορθές νόμιμες βάσεις (λ.χ. στην εκτέλεση της σύμβασης εργασίας), ώστε να μη δημιουργείται στους εργαζομένους η εντύπωση ότι μπορούν να διακόψουν την επεξεργασία των δεδομένων τους ανακαλώντας τη συγκατάθεσή τους.
Επίσης, στην απόφαση παρατίθεται ένα πρακτικό εργαλείο για την επιλογή της ορθής νόμιμης βάσης.
Πρόκειται για τη δοκιμασία της ανάκλησης, σύμφωνα με την οποία εάν μόλις ανακληθεί η συγκατάθεση από το υποκείμενο των δεδομένων η επεξεργασία μπορεί να συνεχιστεί με άλλη νόμιμη βάση, τότε δημιουργούνται αμφιβολίες για τη θεμελίωση της επεξεργασίας στη νόμιμη βάση της συγκατάθεσης επί της αρχής.
Επιπλέον, στην απόφαση διευκρινίζεται ότι η συγκατάθεση έχει την ίδια βαρύτητα με τις υπόλοιπες νόμιμες βάσεις του ΓΚΠΔ.
Δεύτερον, με την απόφαση τονίζεται ότι δεν υπάρχουν νόμιμες βάσεις που να λειτουργούν ως «πανάκεια» για κάθε επεξεργασία προσωπικών δεδομένων.
Η κρίση της ΑΠΔΠΧ καθιστά σαφές ότι ούτε η νόμιμη βάση της συγκατάθεσης (άρθρο 6 παρ. 1 στοιχ. α΄ ΓΚΠΔ) ούτε η νόμιμη βάση της εκτέλεσης σύμβασης (άρθρο 6 παρ. 1 στοιχ. β΄ ΓΚΠΔ) «ταιριάζουν» σε κάθε επεξεργασία.
Ο υπεύθυνος επεξεργασίας δεν «ξεμπερδεύει» με μια αναφορά ότι η επεξεργασία βασίζεται στη συγκατάθεση του υποκειμένου ή στην εκτέλεση της σύμβασης.
Θα πρέπει να καταβάλλεται προσπάθεια από τον υπεύθυνο επεξεργασίας για την επιλογή της ορθής κάθε φορά νόμιμης βάσης επεξεργασίας.
Η άρση οποιασδήποτε σχετικής αμφιβολίας βαραίνει αποκλειστικά τον ίδιο τον υπεύθυνο επεξεργασίας.
Τρίτον, για πρώτη φορά τίθενται σε εφαρμογή τα κριτήρια επιμέτρησης του διοικητικού προστίμου που προβλέπονται στο άρθρο 83 ΓΚΠΔ.
Η ΑΠΔΠΧ κατά την επιβολή του προστίμου έλαβε υπόψη τα εξής στοιχεία:
α) το ότι η εταιρεία παραβίασε βασικές αρχές του ΓΚΠΔ, δηλαδή τις αρχές της νομιμότητας, αντικειμενικότητας και διαφάνειας της επεξεργασίας προσωπικών δεδομένων,
β) ότι η εταιρεία παραβίασε και την αρχή της λογοδοσίας, αφού δεν παρουσίασε εσωτερική τεκμηρίωση για την επιλογή της νόμιμης βάσης της συγκατάθεσης και μετακύλησε το βάρος της συμμόρφωσης με τον ΓΚΠΔ στους εργαζομένους,
γ) ότι η επιλογή των ορθών νομίμων βάσεων επεξεργασίας δεν παρουσίαζε δυσχέρεια στη συγκεκριμένη περίπτωση,
δ) ότι δεν επήλθε υλική ζημία στους εργαζομένους ή οικονομικό όφελος στην εταιρεία από την παράνομη επεξεργασία που έλαβε χώρα,
ε) ότι η παράνομη επεξεργασία οφειλόταν σε αμέλεια του υπευθύνου επεξεργασίας και
στ) την πρόθεση του υπευθύνου επεξεργασίας να συνεργαστεί με την ΑΠΔΠΧ στο χρονικό διάστημα μετά την ακρόαση.
Γ) Αποτίμηση
Η απόφαση 26/2019 της ΑΠΔΠΧ αναμένεται να επηρεάσει την επεξεργασία δεδομένων προσωπικού χαρακτήρα, ιδίως στο πλαίσιο των εργασιακών σχέσεων.
Είναι η πρώτη απόφαση της ΑΠΔΠΧ μετά την έναρξη ισχύος του ΓΚΠΔ που καταπιάνεται με μία από τις πιο σημαντικές έννοιες του δικαίου των προσωπικών δεδομένων: Την έννοια της συγκατάθεσης.
Επιπλέον, η απόφαση μπορεί να αποτελέσει σημείο αναφοράς για τους υπευθύνους επεξεργασίας, γιατί διευκολύνει την επιλογή της σωστής κάθε φορά νόμιμης βάσης.
Στα θετικά επίσης συγκαταλέγεται το γεγονός ότι η ΑΠΔΠΧ ανέλυσε τη δοκιμασία της συγκατάθεσης, η οποία μπορεί να αποτελέσει πρακτικό οδηγό για τους υπευθύνους επεξεργασίας.
Σημειωτέον, ότι η απόφαση της ΑΠΔΠΧ δεν αντιμετωπίστηκε με εχθρότητα από την PwC BS.
Σε ανακοίνωσή της η εταιρεία ανάφερε ότι θα μελετήσει την απόφαση και θα πορευθεί σε κλίμα συνεργασίας με την ΑΠΔΠΧ.
Η απόφαση 26/2019 της ΑΠΔΠΧ είναι πιθανό να οδηγήσει τους υπευθύνους επεξεργασίας σε αναθεώρηση των νομίμων βάσεων επεξεργασίας των δεδομένων που αφορούν τους εργαζομένους και να προκαλέσει αναστάτωση στα νομικά τους τμήματα.
Ωστόσο, ανοίγει τον δρόμο για μεγαλύτερη διαφάνεια και σαφήνεια κατά την επεξεργασία των δεδομένων των εργαζομένων.
* Ο Νικόλας Γανιάρης είναι δικηγόρος και υποψήφιος διδάκτωρ του Εθνικού και Καποδιστριακού Πανεπιστημίου Αθηνών.

Έχω μια φίλη που πάντα αργεί
Του Κωνσταντίνου Κακαβούλη
Έχω μια φίλη, κολλητή, που πάντα αργεί. Όχι όμως επειδή ετοιμάζεται με τις ώρες μπροστά στον καθρέφτη. Απλώς ξεχνιέται. Συνήθως μπαίνει για μπάνιο την ώρα που είμαι κάτω από το σπίτι της και την περιμένω να κατέβει.
Σπάνια φτάνει στην ώρα της στα ραντεβού της -ακόμη και αν είναι επαγγελματικά. Το πρόβλημα είναι ότι η φίλη μου αγχώνεται πολύ όταν καθυστερεί. Προσπαθώντας να αποφύγει τα αρνητικά σχόλια, επειδή καθυστέρησε για ακόμα μία φορά, εμφανίζεται συχνά πολύ λιγότερο περιποιημένη από όσο θα ήθελε.
Έχει έρθει με φρεσκολουσμένα και αχτένιστα μαλλιά σε γάμο για να προλάβει το μυστήριο, έστω και στο τέλος του.
Δυστυχώς, η Ελλάδα αντιμετωπίζει συχνά το ίδιο πρόβλημα με τη φίλη μου. Αργεί. Και όταν αργεί, αγχώνεται. Και όταν αγχώνεται, η εμφάνισή της δεν είναι πάντα η καλύτερη.
Στις 27 Απριλίου 2016 ψηφίστηκαν από την Ευρωπαϊκή Ένωση δύο σημαντικά νομοθετήματα για την προστασία προσωπικών δεδομένων: ο Κανονισμός 2016/679 (ευρέως γνωστός ως GDPR) και η Οδηγία 2016/680.
Η Ευρωπαϊκή Ένωση, αναγνωρίζοντας ότι η ενσωμάτωση και εφαρμογή των δύο νομοθετημάτων, απαιτεί χρόνο και προσπάθεια, έδωσε δύο χρόνια προθεσμία στα Κράτη Μέλη για να τα ενσωματώσουν στις εσωτερικές τους έννομες τάξεις και να ξεκινήσει η εφαρμογή τους.
Τα δύο νομοθετήματα ενισχύουν σημαντικά την προστασία των δικαιωμάτων των πολιτών της Ένωσης, ενώ αυξάνουν τις υποχρεώσεις των ιδιωτικών και δημόσιων φορέων.
Η χώρα μας, παρά το μεγάλο χρονικό περιθώριο, δεν κατάφερε να ανταποκριθεί στις υποχρεώσεις της. Σχηματίστηκε μία νομοπαρασκευαστική επιτροπή, η οποία παρέδωσε ένα προσχέδιο νόμου.
Το προσχέδιο αυτό τέθηκε προς δημόσια διαβούλευση το Μάρτιο του 2018, δηλαδή δύο μήνες πριν τη λήξη της προθεσμίας. Το σχέδιο νόμου δεν έφτασε ποτέ στη Βουλή προς ψήφιση. Ακολούθησε η παραίτηση της προέδρου και ενός μέλους της νομοπαρασκευαστικής επιτροπής, καθώς και η είσοδος νέων μελών σε αυτή.
Τελικά, η δεύτερη νομοπαρασκευαστική επιτροπή παρέδωσε νέο σχέδιο νόμου στον Υπουργό Δικαιοσύνης στο τέλος Φεβρουαρίου 2019 και ενώ η προθεσμία από την Ευρωπαϊκή Ένωση είχε ήδη παρέλθει. Το δεύτερο αυτό σχέδιο νόμου δεν εμφανίστηκε ούτε προς δημόσια διαβούλευση ούτε προς ψήφιση στη Βουλή.
Στις 25 Ιουλίου 2019, η Ευρωπαϊκή Επιτροπή απόφάσισε να παραπέμψει την Ελλάδα και την Ισπανία στο Δικαστήριο της Ευρωπαϊκής Ένωσης λόγω της 15μηνης καθυστέρησης των δύο κρατών στην ενσωμάτωση της Οδηγίας 2016/680 στις εσωτερικές τους έννομες τάξεις.
Μάλιστα, το επαπειλούμενο πρόστιμο για τη χώρα μας δεν είναι διόλου ευκαταφρόνητο: αγγίζει τα 2,5 εκατομμύρια ευρώ.
Μπροστά στον κίνδυνο της καταδίκης από το Δικαστήριο και του προστίμου, η νέα κυβέρνηση έθεσε στις 12 Αυγούστου προς δημόσια διαβούλευση ένα σχέδιο νόμου για την προστασία προσωπικών δεδομένων. Ως ημερομηνία λήξης της διαβούλευσης ορίστηκε η 20η Αυγούστου 2019.
Συνεπώς, δόθηκε ένα διάστημα 4 εργάσιμων ημερών εν μέσω δεκαπενταύγουστου (!) σε όλους τους πολίτες και τους ενδιαφερόμενους φορείς να καταθέσουν τις προτάσεις τους.
Ο συγκεκριμένος χειρισμός υποτιμά το θεσμό της δημόσιας διαβούλευσης και τη συμμετοχή των πολιτών στη νομοθετική διαδικασία, κρατώντας τον πολίτη μακριά από τη συμμετοχή στα κοινά. Η προθεσμία παρατάθηκε τελικά κατά μία ακόμη ημέρα, γεγονός το οποίο καθόλου δε βελτιώνει την κατάσταση.
Το μεγαλύτερο πρόβλημα είναι ότι το προτεινόμενο σχέδιο νόμου παρουσιάζει σημαντικές αστοχίες. Το σχέδιο νόμου προτείνει διαφοροποίηση προστίμων για τον ιδιωτικό και το δημόσιο τομέα. Ο GDPR δίνει πράγματι αυτήν την ευχέρεια (άρθρο 83 παρ. 7), καθώς υπάρχουν κράτη μέλη, στα οποία εκ του Συντάγματός τους δεν επιτρέπεται η επιβολή προστίμων και εν γένει κυρώσεων στις δημόσιες αρχές.
Ωστόσο, η Ελλάδα δεν εμπίπτει σε αυτή την κατηγορία κρατών. Μάλιστα, στο σχέδιο νόμου δεν τεκμηριώνεται η διαφοροποίηση ως προς την επιβολή διοικητικών προστίμων σε δημόσιους φορείς και σε ιδιώτες, ενώ η διαφοροποίηση δεν αναφέρεται σε δημόσιες αρχές, αλλά στον ευρύτατο κύκλο του δημοσίου τομέα.
Πρέπει να σημειωθεί ότι το ΣτΕ έκρινε πρόσφατα συνταγματική την επιβολή προστίμου από την Αρχή Προστασίας Δεδομένων Προσωπικού Χαρακτήρα (ΑΠΔΠΧ) στην Γενική Γραμματεία Πληροφοριακών Συστημάτων, δηλαδή σε ένα κατεξοχήν δημόσιο φορέα. Εξάλλου, η ΑΠΔΠΧ διαθέτει συγκεκριμένα κριτήρια (GDPR άρθρο 83) για να προσδιορίσει το ύψος του διοικητικού προστίμου.
Φαντάζει πραγματικά παράλογη η προσπάθεια θεσμοθέτησης διαφορετικών κριτηρίων για τα πρόστιμα στον ιδιωτικό και στο δημόσιο τομέα, από τη στιγμή μάλιστα που ο δεύτερος διαχειρίζεται πολύ μεγαλύτερους και αρκετά πιο ευαίσθητους όγκους προσωπικών δεδομένων.
Επίσης, το σχέδιο νόμου αφαιρεί τη δυνατότητα που παρέχει ο GDPR στα υποκείμενα των δεδομένων να αναθέτουν την εκπροσώπησή τους σε μη κερδοσκοπικούς φορείς σχετικά με προσφυγές κατά αποφάσεων της ΑΠΔΠΧ και προσφυγής στα δικαστήρια.
Με τον τρόπο αυτό, το ελληνικό σχέδιο νόμου όχι μόνο μειώνει σημαντικά το επίπεδο προστασίας των δικαιωμάτων των πολιτών, αλλά έρχεται και σε αντίθεση με την ευρωπαϊκή νομοθεσία (GDPR άρθρο 80, παρ. 1), την οποία -υποτίθεται ότι- ενσωματώνει.
Σε άλλο σημείο το σχέδιο νόμου δίνει «ανακριτικές εξουσίες» στον εργοδότη, ο οποίος αποκτά το δικαίωμα να διενεργεί έρευνες για την αποκάλυψη ποινικών αδικημάτων σε προσωπικά δεδομένα των εργαζομένων του (π.χ. υπολογιστές, κινητά τηλέφωνα, κλπ), κρίνοντας ο ίδιος και όχι κάποιο ανακριτικό όργανο(!) αν υπάρχουν ενδείξεις και αποδεικτικά στοιχεία.
Η ρύθμιση αυτή έρχεται σε καταφανή αντίθεση με τη νομολογία του Ευρωπαϊκού Δικαστηρίου Δικαιωμάτων του Ανθρώπου (υποθέσεις Barbulescu, Kopke, κ.ά.) και δεν μπορεί να γίνει κατανοητό με ποιο τρόπο η χώρα μας δε θα καταδικαστεί από το εν λόγω Δικαστήριο σε περίπτωση που εφαρμοστεί αυτή η διάταξη.
Οι παραπάνω αστοχίες είναι ενδεικτικά κάποιες από τις πολλές που παρουσιάζει το προτεινόμενο σχέδιο νόμου. Η Homo Digitalis έχει επισημάνει πολύ περισσότερες, οι οποίες βρίσκονται αναρτημένες ως σχόλια στο προτεινόμενο σχέδιο νόμου, όπως τέθηκε σε διαβούλευση. Μπορείτε να τις δείτε όλες συγκεντρωμένες εδώ.
Παρά τα περισσότερα από 240 σχόλια και προτάσεις που κατατέθηκαν στο πλαίσιο της δημόσιας διαβούλευσης, το σχέδιο νόμου κατατέθηκε στη Βουλή στις 22 Αυγούστου, δηλαδή μόλις μία ημέρα μετά τη λήξη της διαβούλευσης.
Τα σχόλια που έγιναν δε φαίνονται να λήφθηκαν σχεδόν καθόλου υπόψη, καθώς το σχέδιο νόμου που κατατέθηκε παρουσιάζει ελάχιστες διαφορές από το σχέδιο που δόθηκε προς διαβούλευση.
Είναι προφανές ότι η παραπομπή της χώρας μας στο Δικαστήριο της Ευρωπαϊκής Ένωσης, προκάλεσε την αντίδραση του έλληνα νομοθέτη, ο οποίος κινήθηκε σχετικά γρήγορα για να καλύψει τη σημαντική του καθυστέρηση. Όμως, με την κίνηση αυτή, δεν πρόκειται να αποφύγει την καταδίκη από το Δικαστήριο.
Όπως δεν πρόκειται και η φίλη μου να αποφύγει την γκρίνια των φίλων της κάθε φορά που αργεί μιάμιση ώρα στα ραντεβού της. Ίσως θα ήταν πιο σκόπιμο να μάθουν τόσο η φίλη μου όσο και η Ελλάδα ότι από τη στιγμή που άργησες, δεν πειράζει να αργήσεις λίγο ακόμα.
Αρκεί να παρουσιαστείς όπως πρέπει. Και όχι με τζιν σορτσάκι και βρεγμένα μαλλιά σε δεξίωση…

ΤΟ ΠΑΖΛ
Γράφει ο Διονύσης Γάκης*
Διανύουμε τις πρώτες εβδομάδες του Αυγούστου, ενός μήνα που είναι συνδεδεμένος με την ψυχική και σωματική ανάταση. Επομένως, αυτή τη φορά επιλέγουμε να φιλοξενήσουμε ένα διαφορετικό άρθρο, το οποίο έχει λογοτεχνικό περιεχόμενο, για να συντροφεύσει τους αναγνώστες μας σε αυτές τις στιγμές χαλάρωσης. Απολαύστε το.
«Η πίστη είναι κάτι δόλιο και υποκειμενικό». Ήταν η φράση που τον έκανε να συνέλθει από το μούδιασμα που είχε πιάσει να απλώνεται σε όλο του το πρόσωπο, με πηγή το δεξί του μάγουλο που είχε ξεκουράσει για μερικά λεπτά μέσα στην χούφτα του. Η φράση άνηκε σε έναν ποιμένα (;) κάποιου βραζιλιάνικου δόγματος νέο-χριστιανισμού.
Ήταν αδύνατο και άσκοπο να ανακαλέσει στη μνήμη του την αλληλουχία αναζητήσεων που τον οδήγησαν στην ενδιαφέρουσα αυτή συνέντευξη του Γιομάτας Νιγκέιρο, ιδρυτή του ποιμνίου και τοπικού παράγοντα, ευαισθητοποιημένου σχετικά με την ανάγκη πιστοποίησης-ευλογίας, από την εκκλησία του, του διάσημου τσαγιού της βραζιλιάνικης επαρχίας Πίντο Παρένσε, σε κάθε συσκευασία παρασκευής του προϊόντος.
Ανακίνησε τον καφέ του και έσπρωξε με το δεξί του χέρι χαρτιά γεμάτα με πρόχειρες σημειώσεις, κίνηση που σήμαινε πως ήταν έτοιμος να πιάσει δουλειά. Ήταν διαυγής και συγκεντρωμένος. Άλλωστε για αυτό πληρωνόταν τόσο καλά σε σχέση με τους συνομηλίκους του. Δικηγόρος, μάλλον καλύτερα νομικός.
Πάντα είχε αυτοπεποίθηση, όχι τόσο σε σχέση με την γνώση που κατείχε, αλλά με την ικανότητά του να έχει άμεσα πρόσβαση σε αυτήν. Γρήγορος, μεθοδικός, αποτελεσματικός. Αυτοί οι χαρακτηρισμοί του έδωσαν αυτήν την θέση και αυτή η θέση του έδωσε αυτήν την υπόθεση. Αν κάποιος μπορούσε να χειριστεί τις βάσεις νομικών δεδομένων με τέτοια ακρίβεια που να μην αφήνει περιθώριο λάθους ήταν αυτός. Έπρεπε να απαντήσει γρήγορα. Μέχρι το τέλος του ωραρίου, μέχρι το τέλος της μέρας.
Δεν ήταν τόσο δύσκολο όσο φαινόταν στην αρχή. Έκανε ό,τι έκανε πάντα, τίποτε διαφορετικό. Όπως λειτουργούσε εκμεταλλευόμενος κάθε δυνατή πληροφορία που ήδη είχε και καθεμία που μπορούσε να βρει εύκολα. Ένιωθε το κεφάλι του να βράζει και τα μάτια του στεγνά, ήταν πολλές οι ώρες που χτυπούσε με μανία τα πλήκτρα. Δεν είχε αυτό που ήθελε στη λευκή σελίδα, ούτε στους πίνακες. Δεν είχε αυτό που ήθελε. Έβαλε το μυαλό του σε εγρήγορση. Έσφιγγε τους μύες του κεφαλιού του λες και αυτό θα πίεζε το μυαλό του να δουλέψει πιο γρήγορα. Ζεστάθηκε από την προσπάθεια, από την πίεση και ίδρωσε.
Μετά από τόση ώρα συνειδητοποίησε ότι είχε γυρίσει στην αρχή, καμία πρόοδος. Οι κινήσεις του είχαν αρχίσει να γίνονται ακατανόητες. Ξεκινούσε να γράφει προτάσεις χωρίς να έχει στο νου πως θα τις τελειώσει, απλά με την ελπίδα πως γράφοντας θα του ερχόταν κάποια ιδέα, λες και κάποια λέξη θα αποκάλυπτε ποια θα της ταίριαζε να την ακολουθήσει επόμενη στο κείμενό του. Ήταν οργισμένος γιατί δεν είχε απάντηση. Χρησιμοποίησε όποια μέθοδο ήξερε, κάθε βάση δεδομένων και κάθε λογισμικό, κάθε συμβουλή και κάθε ένστικτο.
Είχε τόση ώρα να γράψει κάτι που η οθόνη έσβησε και πάνω της έβλεπε το είδωλό του. Το κοίταζε επίμονα για να δει αν στο πρόσωπό του κυριαρχούσε ο θυμός ή η απογοήτευση. Άρχισε να ζεσταίνεται πολύ και να νιώθει αγχωμένος, σα να τον πιάνει παραλήρημα. Έσφιξε τους καρπούς του στις λαβές της καρέκλας για να νιώσει τα χέρια του και να μην χάσει τις αισθήσεις του.
Τότε, σήκωσε το κεφάλι και το είδωλό του φαινόταν ανήμπορο και φοβισμένο, όμως δεν έμοιαζε πλέον με δικό του αντικατοπτρισμό, αλλά με κάτι αυτόνομο. Η οθόνη δεν ήταν μαύρη, τα χρώματα του περιβάλλοντος του γραφείου έδιναν στην εικόνα την γνώριμη όψη του. Τινάχτηκε ταραγμένος από την θέση του όμως το είδωλό του παρέμεινε στη θέση του. Γύρισε αργά το κεφάλι του φοβισμένος για να δει που βρίσκεται.
Βρισκόταν σε μια ολοσκότεινη αίθουσα με μια τραπεζαρία ακριβώς στο κέντρο της. Στην τραπεζαρία έπεφτε ένα πηχτό κίτρινο φώς, από τέσσερις μεγάλες λάμπες γραφείου που βρίσκονταν από μία σε κάθε ορίζοντα, πάνω σε σωρούς από χαρτιά ανακατεμένα, ενώ μερικά από αυτά πήγαιναν και έρχονταν στα χέρια κάποιων μορφών που φαίνονταν να κάθονται γύρω της. Παρατήρησε τις μορφές σμίγοντας τα φρύδια του και συγκεντρώνοντας το βλέμμα του. Όσο πιο πολύ τις παρατηρούσε τόσο πιο ευδιάκριτες γίνονταν.
Ήταν επτά μορφές καθισμένες σε καρέκλες σε μια οβάλ διάταξη γύρω από την τραπεζαρία. Κάποιες φορούσαν κοστούμι και κάποιες είχαν βγάλει το σακάκι και το είχαν περάσει στην πλάτη της καρέκλας τους δουλεύοντας με τα μανίκια σηκωμένα. Έγραφαν και σημείωναν κάτι ο ένας στο χαρτί του άλλου και καμιά φορά γελούσαν. Πλησίασε αρκετά μα εκείνες δεν μπορούσαν να τον προσέξουν. Έπειτα παίρνοντας θάρρος και αφού τις είχε παρατηρήσει αρκετά ώστε να είναι σίγουρος πως επρόκειτο για επτά σοβαρούς άνδρες – μάλλον επιχειρηματίες και συμβούλους, αν και ο ρόλος του καθενός δεν ήταν εύκολα αναγνώσιμος με βάση την στάση του σώματός τους – προσπάθησε επίμονα και μάταια για αρκετή ώρα να τους κάνει να τον δουν.
Τώρα είχε πάει ακριβώς από πάνω τους και κοίταζε τα χαρτιά τους. Δεν καταλάβαινε τίποτα. Έκανε να πιάσει ένα με το χέρι και το έφερε κάτω από την πιο κοντινή του λάμπα για να διαβάσει τι έλεγε. Ήταν μια αδιάκοπη σειρά από ψηφία 0 και 1. Το δυαδικό σύστημα. Δεν καταλάβαινε τίποτα. Έπαιρνε διαρκώς νέα χαρτιά μιας και δεν τον καταλάβαιναν και έφτασε να τους παίρνει ακόμα και αυτά που κρατούσαν στα χέρια τους.
Βρήκε μερικά στα κινέζικα, άλλα στα αραβικά, κάποια στα ισπανικά και στα αγγλικά. Από όσα μπορούσε να καταλάβει από το αγγλικό κείμενο το περιεχόμενο αφορούσε στο ερώτημα που έψαχνε όλη μέρα. Έψαχνε τα χαρτιά συνεχώς και έβρισκε όλο και πιο πολλά στοιχεία που τον έκαναν να αναθαρρήσει. Μετά από μερικά λεπτά βρήκε αυτό που ήθελε. Ήταν προφανές από την αρχή, ήταν εκεί μπροστά στα μάτια του, ένα γυαλιστερό φύλλο χαρτί στα δεξί χέρι του άνδρα με το σακάκι που καθόταν στην κεφαλή της τραπεζαρίας, του μόνου που δεν είχε κάποιον άλλον απέναντί του. Πήρε το χαρτί και άρχισε να το διαβάζει βιαστικά για να μάθει όσο το δυνατόν πιο γρήγορα.
Δεν πρόλαβε όμως. Οι άντρες σηκώθηκαν απότομα, μάζεψαν όλα τα χαρτιά, μαζί κι αυτό που είχε στο χέρι, δύο από αυτούς άνοιξαν τις κουρτίνες και μπήκε φως παντού στο δωμάτιο, ενώ αυτοί έφυγαν βιαστικά. Γύρισε το βλέμμα του και η τραπεζαρία είχε εξαφανιστεί, το δωμάτιο ήταν πλέον φωτεινό και του έβγαζε μια ζεστασιά, το γνώριζε αυτό το δωμάτιο. Ήταν το παιδικό του δωμάτιο, τα παιχνίδια και οι ζωγραφιές στους τοίχους ήταν όλα εδώ όπως τα θυμόταν.
Για κάποιον ακατανόητο λόγο δεν του φάνηκε περίεργο που είδε τους γονείς του σκυφτούς στα γόνατά τους να συμπληρώνουν ένα παζλ. Ούτε ακόμη όταν είδε την τρίχρονη εκδοχή του εαυτού του σε ένα παιδικό πάρκο να θέλει να βγει από αυτό για να παίξει με το πάζλ. Το παιδί είχε στο πάρκο όσα παιχνίδια ήταν κατάλληλα για αυτό, για την ηλικία του. Δεν ήθελε να παίξει άλλο μ’ αυτά, τα είχε βαρεθεί, τα είχε χιλιοπαίξει και τα ήξερε απ’ έξω κι ανακατωτά. Ήθελε το πάζλ και έβαζε όλες του τις δυνάμεις να βρει τρόπο να βγει από εκεί. Έκανε ασυναίσθητα μερικά βήματα και στάθηκε πάνω από τους γονείς του. Όπως και πριν με τους κυρίους, έτσι και τώρα κανείς δεν αντιλαμβανόταν την παρουσία του.
Το πάζλ δεν ήθελε παρά μερικά κομμάτια στις γωνίες για να ολοκληρωθεί και η εικόνα που είχε σχηματιστεί τον έκανε να νιώσει ότι ήταν σίγουρος από πριν γι’ αυτό που θα έβλεπε. Ήταν ίδια με το κομμάτι χαρτί που του είχαν πάρει από το χέρι. Ήταν η απάντησή του. Ήταν η δουλειά του.
Άνοιξε τα μάτια του και κοίταξε το είδωλό του στην μαύρη οθόνη του υπολογιστή. Του φάνηκε πως τον είδε να κοιμάται.
*Ο Διονύσης Γάκης είναι δικηγόρος Αθηνών. Σπούδασε στην Κομοτηνή και είναι απόφοιτος του τμήματος Νομικής του Δημοκρίτειου Πανεπιστημίου Θράκης. Επίσης, είναι τελειόφοιτος του Μεταπτυχιακού Προγράμματος Σπουδών στο Δίκαιο Ανταγνωνισμού και Εταιριών του Δημοκρίτειου Πανεπιστημίου Θράκης. Ζει και εργάζεται στην Αθήνα. Βρίσκει στη νομική επιστήμη τη βάση για την κατανόηση της κίνησης της οικονομίας.

Διατήρηση Μεταδεδομένων Ηλεκτρονικών Επικοινωνιών: Το ευρωπαϊκό φάντασμα που θέλει να πάρει ξανά σάρκα και οστά
Γράφει ο Λευτέρης Χελιουδάκης
Στις 22 Ιουλίου η EDRi, μαζί με άλλες 29 οργανώσεις της κοινωνίας των πολιτών από διάφορα κράτη μέλη της Ευρωπαϊκής Ένωσης, συμπεριλαμβανομένης της Homo Digitalis, απηύθυνε ανοιχτή επιστολή προς την εκλεγμένη Πρόεδρο της Ευρωπαϊκής Επιτροπής, Ursula von der Leyen, και τον Πρώτο Αντιπρόεδρο της Ευρωπαϊκής Επιτροπής, Frans Timmermans.
Με την επιστολή αυτή ζητάμε να διασφαλιστεί ότι η νομοθεσία περί διατήρησης μεταδεδομένων ηλεκτρονικών επικοινωνιών στα Κράτη Μέλη της ΕΕ θα ευθυγραμμιστεί επιτέλους με τη σχετική νομολογία του Δικαστηρίου της Ευρωπαϊκής Ένωσης (ΔΕΕ) και τις διατάξεις του Χάρτη Θεμελιωδών Δικαιωμάτων της ΕΕ.
Με τον όρο «μεταδεδομένα» ορίζονται τα δεδομένα κίνησης και θέσης και τα συναφή δεδομένα, τα οποία υποχρεούνται να διατηρούν οι πάροχοι ηλεκτρονικών επικοινωνιών ή δημοσίου δικτύου επικοινωνιών. Αυτά περιλαμβάνουν, μεταξύ άλλων, το ονοματεπώνυμο και τη διεύθυνση του συνδρομητή ή του εγγεγραμμένου χρήστη, τον αριθμό τηλεφώνου του καλούντος και τον αριθμό του καλουμένου, τη διεύθυνση IP για τις υπηρεσίες του διαδικτύου, τον τερματικό εξοπλισμού του συνδρομητή ή και χρήστη, την ημερομηνία και ώρα έναρξης/λήξης καθώς και τη διάρκεια της επικοινωνίας, τον όγκο των διαβιβασθέντων δεδομένων, πληροφορίες σχετικά με το πρωτόκολλο, τη μορφοποίηση και τη δρομολόγηση της επικοινωνίας, το δίκτυο από το οποίο προέρχεται ή στο οποίο καταλήγει η επικοινωνία, και τα δεδομένα που υποδεικνύουν τη γεωγραφική θέση του τερματικού εξοπλισμού του χρήστη μίας διαθέσιμης στο κοινό υπηρεσίας ηλεκτρονικών επικοινωνιών.
Τα δεδομένα αυτά παρέχουν τη δυνατότητα, μεταξύ άλλων, διαπίστωσης της ταυτότητας του προσώπου με το οποίο ο συνδρομητής ή ο εγγεγραμμένος χρήστης επικοινώνησε, του μέσου με το οποίο έγινε η επικοινωνία, καθώς και τη δυνατότητα προσδιορισμού του χρόνου της επικοινωνίας και της γεωγραφικής θέσης από την οποία έλαβε χώρα η επικοινωνία αυτή. Επιπλέον, τα δεδομένα αυτά παρέχουν τη δυνατότητα να διαπιστωθεί η συχνότητα των επικοινωνιών του συνδρομητή ή του εγγεγραμμένου χρήστη με συγκεκριμένα πρόσωπα σε δεδομένη χρονική περίοδο.
Με απλά λόγια τα μεταδεδομένα επιτρέπουν να διαπιστωθεί ποιος μίλησε με ποιον, μέσω ποιων συσκευών, πότε, για πόση διάρκεια, καθώς και πού κατά προσέγγιση βρίσκονταν αυτοί οι χρήστες κατά τη συνομιλία τους. Επομένως, τα μεταδεδομένα δεν αφορούν το περιεχόμενο της επικοινωνίας αλλά όλα τα άλλα συνοδευτικά στοιχεία αυτής.
Αιτία της επιστολής αυτής στάθηκε το έγγραφο που δημοσίευσε στις αρχές Ιουνίου το Συμβούλιο της ΕΕ. Σύμφωνα με αυτό, το Συμβούλιο συμπεραίνει πως η διατήρηση μεταδεδομένων ηλεκτρονικών επικοινωνιών αποτελεί ένα βασικό εργαλείο για την αποδοτική διερεύνηση εγκλημάτων, και καλεί την Ευρωπαϊκή Επιτροπή να διεξάγει έρευνα σχετικά με πιθανές λύσεις για την διατήρηση δεδομένων ηλεκτρονικών επικοινωνιών, συμπεριλαμβανομένης μίας μελλοντικής ενωσιακής νομοθετικής πρωτοβουλίας στον τομέα αυτό.
Με αφορμή την επιστολή αυτή, αξίζει να κάνουμε μια σύντομη αναδρομή σχετικά με την ευρωπαϊκή ιστορία της διατήρησης μεταδεδομένων ηλεκτρονικών επικοινωνιών, καθώς και να αναλογιστούμε την κατάσταση που επικρατεί σήμερα στην ΕΕ και στη χώρα μας.
Πίσω στο μακρινό 1997, η Ευρωπαϊκή Ένωση για πρώτη φορά επιχείρησε μέσω της Οδηγίας 97/66/EK περί επεξεργασίας προσωπικών δεδομένων στις τηλεπικοινωνίες (γνωστή και ως Οδηγία ISDN) να ρυθμίσει το συγκεκριμένο τομέα. Η Οδηγία συμπλήρωνε τις διατάξεις της Οδηγίας 95/46/ΕΚ (της μαμάς του GDPR) και παρείχε για πρώτη φορά σημαντικές λεπτομέρειες αναφορικά με την απαλοιφή των δεδομένων κίνησης και χρέωσης των συνδρομητών.
Ωστόσο, οι τεχνολογικές εξελίξεις στον τομέα των τηλεπικοινωνιών και του διαδικτύου οδήγησαν και στην τροποποίηση της Οδηγίας 97/66/EK.
Συγκεκριμένα, το 2002 η Οδηγία 2002/58/ΕΚ (ευρέως γνωστή ως ePrivacy Directive) ήρθε για να προσφέρει ένα ευρύτερο πλαίσιο προστασίας αναφορικά με ζητήματα που αφορούσαν την ιδιωτικότητα και τα προσωπικά δεδομένα κατά τη χρήση των τηλεπικοινωνιών. Μάλιστα το τότε Άρθρο 15 αυτής (πριν η Οδηγία τροποποιηθεί το 2009) έθεσε τις βάσεις για εθνικά νοµοθετικά µέτρα που θα προέβλεπαν τη φύλαξη μεταδεδοµένων ηλεκτρονικών επικοινωνιών για ορισµένο χρονικό διάστηµα προκειμένου να επιτευχθούν σκοποί σχετικοί με τη διαφύλαξη της εθνικής ασφάλειας, της εθνικής άµυνας, της δηµόσιας ασφάλειας, και την πρόληψη, διερεύνηση, διαπίστωση και δίωξη ποινικών αδικηµάτων.
Επιπλέον, όπως υπογραμμίζει και η οργάνωση της κοινωνίας των πολιτών «Statewatch», την περίοδο εκείνη υπήρξε άμεση επιρροή από τις Ηνωμένες Πολιτείες της Αμερικής. Συγκεκριμένα, τον Οκτώβριο του 2001, λίγο μετά τις τρομοκρατικές επιθέσεις στις Η.Π.Α., ο τότε Πρόεδρος των Η.Π.Α. κ. George Bush Jr είχε αποστείλει επιστολή στον τότε Πρόεδρο της Ευρωπαϊκής Επιτροπής κ. Romano Prodi με την οποία του κοινοποιούσε μια λίστα με προτεινόμενες δράσεις, τις οποίες η Ευρωπαϊκή Ένωση θα μπορούσε να υιοθετήσει προκειμένου να σταθεί αρωγός στις προσπάθειες των Η.Π.Α. για πάταξη της τρομοκρατίας.
Μία από αυτές τις προτεινόμενες δράσεις ήταν και η αναθεώρηση των τότε υφιστάμενων σχεδίων οδηγιών που προέβλεπαν την υποχρεωτική καταστροφή των μεταδεδομένων ηλεκτρονικών επικοινωνιών, προκειμένου να επιτρέπεται η διατήρησή τους για ένα εύλογο χρονικό διάστημα.
Τον Ιούνιο του 2004, λίγο μετά τις τρομοκρατικές βομβιστικές επιθέσεις του Μαρτίου του ίδιου έτους στη Μαδρίτη, το Συμβούλιο της ΕΕ με το Σχέδιο Δράσης της ΕΕ για την πάταξη της τρομοκρατίας (ενότητα 3.1.10) τάχθηκε επίσημα, για πρώτη φορά, υπέρ της πρότασης της Γαλλίας, Ιρλανδίας, Σουηδίας, και του Ην. Βασιλείου για μία νομοθετική πρωτοβουλία στον τομέα της διατήρησης μεταδεδομένων ηλεκτρονικών επικοινωνιών. Ως καταληκτική ημερομηνία για την υιοθέτηση του εν λόγω νομικού πλαισίου τέθηκε ο Ιούνιος του 2005.
Δυστυχώς, μία νέα τρομοκρατική βομβιστική επίθεση στο Λονδίνο έλαβε χώρα τον Ιούλιο του 2005. Το Συμβούλιο της ΕΕ με δελτίο τύπου του εκείνες τις ημέρες τόνισε τη σημασία της υιοθέτησης του νομικού πλαισίου για τη διατήρηση μεταδεδομένων ηλεκτρονικών επικοινωνιών σε επίπεδο ΕΕ. Δύο μήνες μετά, η Ευρωπαϊκή Επιτροπή κατέθεσε την πρόταση νομοθεσίας για μία ευρωπαϊκή οδηγία – αυτή τη φορά – στον τομέα της διατήρησης μεταδεδομένων ηλεκτρονικών επικοινωνιών. Τελικά, το Μάρτιο του 2006, υιοθετήθηκε η Οδηγία 2006/24/ΕΚ για την διατήρηση μεταδεδομένων ηλεκτρονικών επικοινωνιών.
Πολλά έχουν γραφτεί για εκείνη την περίοδο αναφορικά με την έλλειψη ενδελεχούς έρευνας από την πλευρά της ΕΕ σχετικά με την προστιθέμενη αξία της εν λόγω νομοθεσίας στον αγώνα για τη πάταξη της τρομοκρατίας και της εγκληματικότητας, καθώς και τις πιέσεις που έλαβαν χώρα σε ενωσιακό επίπεδο από εθνικούς φορείς. Πολλοί έφτασαν να χαρακτηρίσουν το συγκεκριμένο νομικό πλαίσιο ως ένα χαρακτηριστικό παράδειγμα «ξεπλύματος πολιτικής» (policy laundering = νομοθετικές πρωτοβουλίες, οι οποίες επειδή αδυνατούν να υιοθετηθούν αρχικά σε εθνικό επίπεδο, προωθούνται και υιοθετούνται τελικά σε δεύτερο χρόνο μέσω της νομοθετικής διαδικασίας της ΕΕ).
Στο παρόν άρθρο δεν θα εστιάσουμε σε αυτά τα ζητήματα, ωστόσο για όσους ενδιαφέρονται η Statewatch έχει δημοσιεύσει μία έρευνα με το πλήρες ιστορικό της περιόδου, η οποία περιέχει πληθώρα σχετικών πηγών.
Οι διατάξεις της Οδηγίας 2006/24/ΕΚ έθεταν σοβαρά ζητήματα αναφορικά με τα δικαιώματα και τις ελευθερίες των κατοίκων της ΕΕ.
Συγκεκριμένα, η διατήρηση των μεταδεδομένων των ηλεκτρονικών επικοινωνιών ήταν υποχρεωτική για κάθε κάτοικο της ΕΕ, χωρίς η συμπεριφορά του να συνδέεται, έστω και με τρόπο έμμεσο ή απομακρυσμένο, με κάποια σοβαρή παράβαση. Δεν υπήρχε δε καμία εξαίρεση ακόμη και σε πρόσωπα των οποίων οι επικοινωνίες καλύπτονταν, βάσει εθνικών κανόνων δικαίου, από το επαγγελματικό απόρρητο. Επιπλέον, η διάρκεια της διατήρησης κυμαινόταν μεταξύ 6 μηνών τουλάχιστον και 24 μηνών, κατά μέγιστο όριο, χωρίς να διευκρινίζεται ότι ο καθορισμός της διάρκειας διατήρησης πρέπει να στηρίζεται σε αντικειμενικά κριτήρια προκειμένου να διασφαλίζεται ότι η διατήρηση περιορίζεται στον απολύτως αναγκαίο βαθμό.
Ακόμη, οι διατάξεις της Οδηγίας δεν προέβλεπαν κανένα αντικειμενικό κριτήριο για τον καθορισμό του αριθμού των προσώπων στα οποία επιτρέπεται η πρόσβαση και η εν συνεχεία χρήση των διατηρούμενων μεταδεδομένων. Το κυριότερο είναι ότι η πρόσβαση στα διατηρούμενα δεδομένα από τις αρμόδιες εθνικές αρχές δεν εξαρτιόταν από προηγούμενο έλεγχο πραγματοποιούμενο είτε από δικαστήριο είτε από ανεξάρτητη διοικητική αρχή και κατόπιν απόφασης που θα περιόριζε την πρόσβαση στα μεταδεδομένα και την χρήση τους στον απολύτως αναγκαίο βαθμό, προκειμένου να επιτευχθεί ο επιδιωκόμενος σκοπός στο πλαίσιο των διαδικασιών για την πρόληψη, τη διαπίστωση ή την ποινική δίωξη σοβαρών εγκλημάτων. Ούτε βέβαια προβλεπόταν ότι τα κράτη μέλη είχαν τη συγκεκριμένη υποχρέωση να προβαίνουν σε τέτοιου είδους οριοθετήσεις.
Πρέπει να γίνει αντιληπτό ότι η διατήρηση των μεταδεδομένων των ηλεκτρονικών επικοινωνιών παρείχε τη δυνατότητα εξαγωγής ιδιαιτέρως ακριβών συμπερασμάτων σε σχέση με την ιδιωτική ζωή των προσώπων των οποίων τα δεδομένα είχαν διατηρηθεί, όπως είναι οι καθημερινές συνήθειες, οι μόνιμοι ή οι προσωρινοί τόποι διαμονής, οι καθημερινές και άλλες μετακινήσεις, οι ασκούμενες δραστηριότητες, οι κοινωνικές σχέσεις των προσώπων αυτών και τα κοινωνικά περιβάλλοντα στα οποία τα πρόσωπα αυτά συχνάζουν.
Έχοντας υπόψη τα ανωτέρω, η ιρλανδική οργάνωση της κοινωνίας των πολιτών Digital Rights Ireland, η οποία υπογράφει και την επιστολή στην αρχή του παρόντος άρθρου, αποφάσισε να αμφισβητήσει την συμβατότητα της Οδηγίας με τις διατάξεις του Χάρτη και κίνησε διαδικασίες σε εθνικό επίπεδο. Αποτέλεσμα αυτών ήταν τον Ιούνιο του 2012 το Ανώτατο Δικαστήριο της Ιρλανδίας να αποστείλει αίτηση για την έκδοση προδικαστικής απόφασης από το ΔΕΕ για μία σειρά προδικαστικών ερωτημάτων. Η αίτηση αυτή ενώθηκε αργότερα με αντίστοιχη αίτηση που απέστειλε τον Δεκέμβριο του ίδιου χρόνου στο ΔΕΕ το Συνταγματικό Δικαστήριο της Αυστρίας (υπόθεση Kärntner Landesregierung κ.λπ., αργότερα Seitlinger κ.πλ.).
Μετά από την συζήτηση των υποθέσεων τον Ιούλιο του 2013, η απόφαση για τις δύο αυτές συνεκδικαζόμενες αποφάσεις ήρθε τον Απρίλιο του 2014. Σε αυτή την απόφαση το ΔΕΕ αποφάνθηκε ότι η Οδηγία 2006/24/ΕΚ είναι ανίσχυρη, καθώς ο νομοθέτης της Ένωσης υπερέβη τα όρια που επιβάλλει η τήρηση της αρχής της αναλογικότητας υπό το πρίσμα των Άρθρων 7, 8 και 52, παράγραφος 1, του Χάρτη.
Σύμφωνα με το ΔΕΕ, οι διατάξεις της Οδηγίας θέσπιζαν ένα γενικό καθεστώς διατήρησης των δεδομένων σχετικά με επικοινωνίες το οποίο προσέβαλε τα δικαιώματα που κατοχυρώνονται στα Άρθρα 7 και 8 του Χάρτη της ΕΕ (προστασία ιδιωτικής και οικογενειακής ζωής, προστασία προσωπικών δεδομένων). Η Οδηγία συνεπαγόταν μια τεράστιας έκτασης και ιδιαιτέρως μεγάλης βαρύτητας επέμβαση σε αυτά τα θεμελιώδη δικαιώματα χωρίς η επέμβαση αυτή να οριοθετείται επακριβώς μέσω διατάξεων δυνάμενων να διασφαλίσουν ότι πράγματι περιορίζεται στον απολύτως αναγκαίο βαθμό.
Τέλος, οι διατάξεις της δεν επέβαλαν τη διατήρηση των εν λόγω δεδομένων εντός των εδαφικών ορίων της Ένωσης και, ως εκ τούτου, δεν μπορούσε να θεωρηθεί ότι διασφάλιζαν πλήρως τον έλεγχο από ανεξάρτητη αρχή, ο οποίος ρητώς απαιτείται από το Άρθρο 8 του Χάρτη, και ο οποίος συνιστά ουσιώδες στοιχείο του σεβασμού της προστασίας των προσώπων κατά την επεξεργασία δεδομένων προσωπικού χαρακτήρα.
Μετά τη κήρυξη της Οδηγίας 2006/24/ΕΚ ως ανίσχυρης από το ΔΕΕ, τα Κράτη Μέλη της ΕΕ εξακολουθούσαν να έχουν σε ισχύ τις εθνικές τους νομοθεσίες με τις οποίες είχαν μεταφέρει τις διατάξεις της Οδηγίας στην εθνική τους έννομη τάξη.
Έτσι π.χ. στην Ελλάδα ο Ν. 3917/2011 εξακολούθησε να βρίσκεται σε ισχύ. Με απόφαση του τότε Υπουργού Δικαιοσύνης, Διαφάνειας και Ανθρωπίνων Δικαιωμάτων, είχε συσταθεί Ειδική Νομοπαρασκευαστική Επιτροπή τον Ιούλιο του 2014 με αντικείμενο την κατάργηση/τροποποίηση της εν λόγω νομοθεσίας και την πρόταση περαιτέρω νομοθετικών ρυθμίσεων με την υποβολή σχεδίου νόμου, αιτιολογικής έκθεσης και έκθεσης αξιολόγησης συνεπειών των ρυθμίσεων.
Με μία σειρά νεότερων αποφάσεων των εκάστοτε Υπουργών Δικαιοσύνης Διαφάνειας και Ανθρωπίνων Δικαιωμάτων, η ημερομηνία περάτωσης των εργασιών της Νομοπαρασκευαστικής Επιτροπής παρατάθηκε έως και τον Σεπτέμβριο του 2018, δηλαδή περισσότερο από 4 χρόνια μετά τη σύσταση της επιτροπής!
Κατόπιν επιστολής μας προς το Υπουργείο Δικαιοσύνης, Διαφάνειας, και Ανθρωπίνων Δικαιωμάτων, λάβαμε άμεσα επίσημη απάντηση ότι η εν λόγω Νομοπαρασκευαστική Επιτροπή έχει πλέον αναστείλει τις εργασίες της και δεν έχει ολοκληρώσει έως σήμερα (περισσότερο από 5 έτη μετά τη σύστασή της) το έργο της, ήτοι την υποβολή στον Υπουργό σχεδίου νόμου, αιτιολογικής έκθεσης, και αίτησης αξιολόγησης συνεπειών ρυθμίσεων!
Αξίζει μάλιστα να σημειωθεί, ότι πριν τρία χρόνια, τον Αύγουστο του 2016, το Πρωτοδικείο Ρεθύμνου είχε υποβάλει αίτηση για έκδοση προδικαστικής αποφάσεως στο ΔΕΕ σχετικά με μία σειρά από προδικαστικά ερωτήματα που αφορούσαν το γεγονός ότι η εθνική μας νομοθεσία που ενσωμάτωσε την οδηγία 2006/24/ΕΚ εξακολουθούσε να ισχύει και να εφαρμόζεται από τα εγχώρια δικαστήρια. Ωστόσο, η υπόθεση εντέλει διαγράφηκε από το πρωτόκολλο του ΔΕΕ. Συγκεκριμένα, όπως προκύπτει από το σχετικό έγγραφο του ΔΕΕ, μετά την απόφαση που εξέδωσε το Δικαστήριο επί των συνεκδικασθεισών υποθέσεων C‑203/15 και C‑698/15, Tele2 Sverige και Watson κ.λπ., το Πρωτοδικείο Ρεθύμνου δεν διευκρίνισε μέχρι την ταχθείσα προθεσμία εάν, λαμβανομένης υπόψη της απόφασης αυτής, επιθυμούσε να εμμείνει στην αίτηση προδικαστικής αποφάσεως του. Επομένως, το ΔΕΕ συνήγε το συμπέρασμα ότι το Πρωτοδικείο Ρεθύμνου δεν επιθυμεί να εμμείνει στην αίτηση προδικαστικής αποφάσεως, μετά την απόφαση επί των ως άνω συνεκδικασθείσων υποθέσεων.
Η υπόθεση Tele2 Sverige και Watson κ.λπ αφορά τις εθνικές νομοθεσίες της Σουηδίας και του Ηνωμένου Βασιλείου σχετικά με τη διατήρηση μεταδεδομένων ηλεκτρονικών επικοινωνιών μετά τη κήρυξη της Οδηγίας 2006/24/ΕΚ ως ανίσχυρης, και ερμηνεύει το Άρθρο 15 της Οδηγίας 2002/58 (ePrivacy Diriective), όπως αυτή τροποποιήθηκε το 2009.
Το Δεκέμβριο του 2016, με την απόφαση του σε αυτή την υπόθεση, το ΔΕΕ ερμήνευσε το Άρθρο 15, υπό το πρίσμα των άρθρων 7, 8 και 11 καθώς και του άρθρου 52, παράγραφος 1, του Χάρτη. Κατέληξε στο συμπέρασμα ότι αντιβαίνει προς το Άρθρο 15 εθνική ρύθμιση η οποία, προς τον σκοπό καταπολέμησης του εγκλήματος, προβλέπει γενική και χωρίς διάκριση διατήρηση του συνόλου των δεδομένων κινήσεως και των δεδομένων θέσης όλων των συνδρομητών και των εγγεγραμμένων χρηστών όλων των μέσων ηλεκτρονικής επικοινωνίας .
Ωστόσο, το Άρθρο 15 δεν αντιτίθεται στη θέσπιση από κράτος μέλος ρυθμίσεως η οποία επιτρέπει, προληπτικώς, τη στοχευμένη διατήρηση των δεδομένων κινήσεως και των δεδομένων θέσης, προς τον σκοπό καταπολέμησης του σοβαρού εγκλήματος, υπό την προϋπόθεση ότι η διατήρηση των δεδομένων περιορίζεται σε ό,τι είναι απολύτως αναγκαίο όσον αφορά τις κατηγορίες διατηρούμενων δεδομένων, τα πρόσωπα των οποίων τα δεδομένα διατηρούνται καθώς και το διάστημα για το οποίο γίνεται δεκτό ότι πραγματοποιείται η διατήρηση.
Επίσης, όπως το ΔΕΕ υπογραμμίζει, η υποχρέωση που επιβάλλεται στους παρόχους υπηρεσιών ηλεκτρονικών επικοινωνιών να διατηρούν τα δεδομένα κινήσεως, προκειμένου οι αρμόδιες εθνικές αρχές να έχουν πρόσβαση σε αυτά, εφόσον παρίσταται ανάγκη, εγείρει ζητήματα που συνδέονται με τον σεβασμό όχι μόνον των άρθρων 7 και 8 του Χάρτη, αλλά και με τον σεβασμό της ελευθερίας της έκφρασης που κατοχυρώνεται στο άρθρο 11 του Χάρτη.
Ακόμα και αν η ρύθμιση αυτή δεν επιτρέπει τη διατήρηση του περιεχομένου της επικοινωνίας και, επομένως, δεν μπορεί να θίξει το βασικό περιεχόμενο των εν λόγω δικαιωμάτων, η διατήρηση των δεδομένων κινήσεως και των δεδομένων θέσεως θα μπορούσε εντούτοις να επηρεάσει τη χρήση των μέσων ηλεκτρονικής επικοινωνίας και, ως εκ τούτου, την άσκηση από τους χρήστες των εν λόγω μέσων της ελευθερίας έκφρασής τους.
Τέλος, το ΔΕΕ τόνισε ότι αντιβαίνει προς το Άρθρο 15 εθνική ρύθμιση η οποία καθορίζει τα σχετικά με την προστασία και την ασφάλεια των δεδομένων κινήσεως και των δεδομένων θέσης και, ιδίως, την πρόσβαση των αρμόδιων εθνικών αρχών στα διατηρούμενα δεδομένα, χωρίς να περιορίζει την εν λόγω πρόσβαση μόνο στις περιπτώσεις που συνδέονται με την καταπολέμηση του σοβαρού εγκλήματος, χωρίς να προβλέπει ότι η εν λόγω πρόσβαση υπόκειται στον προηγούμενο έλεγχο δικαστηρίου ή ανεξάρτητης διοικητικής αρχής και χωρίς να επιβάλλει τη διατήρηση των εν λόγω δεδομένων εντός των εδαφικών ορίων της Ένωσης.
Βέβαια, σημαντικό αναφορικά με τη διατήρηση μεταδεδομένων ηλεκτρονικών επικοινωνιών είναι και το σκεπτικό των αποφάσεων του ΔΕΕ σε άλλες υποθέσεις, όπως η υπόθεση C‑362/14 (Schrems) και η υπόθεση C-207/16 (Ministerio Fiscal), καθώς και το σκεπτικό του Ευρωπαϊκού Δικαστηρίου των Δικαιωμάτων του Ανθρώπου (ΕΔΔΑ) σε υποθέσεις όπως η Centrum för rättvisa κατά Σουηδίας και Βig Βrother Watch κ.λπ. κατά Ην. Βασιλείου, οι οποίες βέβαια πλέον έχουν παραπεμφθεί στο τμήμα μείζονος συνθέσεως του Δικαστηρίου. Φυσικά, παρελθοντικές αποφάσεις τόσο του ΔΕΕ όσο και του ΕΔΔΑ εξακολουθούν να έχουν βαρύνουσα σημασία για τα ζητήματα που ανακύπτουν.
Σε επίπεδο Ελληνικών Ανωτάτων Δικαστηρίων, ιδιαίτερα σημαντικές αποφάσεις αναφορικά με το απόρρητο των ηλεκτρονικών επικοινωνιών αποτελούν η με αριθμό 1593/2016 απόφαση του Συμβουλίου της Επικρατείας (Τμ. Δ΄- Επταμελές) και η με αριθμό 1/2017 απόφαση της Ολομέλειας του Αρείου Πάγου.
Σχετικά με τη διάσταση που υπάρχει στη νομολογία αυτών των Ανωτάτων Δικαστηρίων, αξίζει να παρακολουθήσει κανείς την εξαιρετική τοποθέτηση του Πάρεδρου του Συμβουλίου της Επικρατείας, κ. Νικολάου Κ. Μαρκόπουλου, στη Βουλή των Ελλήνων στο πλαίσιο της Ημερίδας που διοργάνωσε η Αρχή Διασφάλισης του Απορρήτου των Επικοινωνιών (ΑΔΑΕ) το Μάη του 2018 (30:00 επόμενα). Βέβαια, προτείνουμε την παρακολούθηση και των υπολοίπων τοποθετήσεων της ημερίδας που έχουν αναρτηθεί από το κανάλι της Βουλής.
Όργανα και Οργανισμοί της Ευρωπαϊκής Ένωσης συμμετέχουν τα τελευταία χρόνια σε συζητήσεις και συναντήσεις αναφορικά με την ισχύουσα νομοθεσία για την διατήρηση μεταδεδομένων ηλεκτρονικών επικοινωνιών σε επίπεδο κρατών μελών. Για παράδειγμα, η Επιτροπή, η Europol, και η Eurojust συμμετέχουν σε συναντήσεις που οργανώνει η Ομάδα Εργασίας του Συμβουλίου της ΕΕ για τη διατήρηση δεδομένων ηλεκτρονικών επικοινωνιών (Working Party on Telecommunications and Information Society / DAPIX (Friends of Presidency – Data Retention)). Με τη σειρά του το Συμβούλιο της ΕΕ δημοσίευσε στις αρχές Ιουνίου τα συμπεράσματά του επί του θέματος, καλώντας την Ευρωπαϊκή Επιτροπή σε μία σειρά από δράσεις.
Με τη σειρά μας, με τη κοινή ανοιχτή επιστολή που απευθύναμε προς την Ευρωπαϊκή Επιτροπή ζητάμε:
-Η Ευρωπαϊκή Επιτροπή να διεξάγει ενδελεχή έρευνα αναφορικά με την ισχύουσα νομοθεσία στον τομέα αυτό, συμπεριλαμβανομένης μίας συστηματικής αξιολόγησης του αντικτύπου στα δικαιώματα του ανθρώπου και μιας συγκριτικής ανάλυσης των περιπτώσεων κατά των οποίων η χρήση των εν λόγω διατάξεων έχει οδηγήσει στην διαλεύκανση σοβαρών εγκλημάτων,
-Η Ευρωπαϊκή Επιτροπή και το Συμβούλιο της ΕΕ να διασφαλίσουν ότι οι συζητήσεις για μία νέα ευρωπαϊκή νομοθετική πρωτοβουλία στον τομέα αυτό δεν θα επηρεάσουν τη γρήγορη υιοθέτηση της προτεινόμενης νομοθεσίας για την προστασία της ιδιωτικότητας στις ηλεκτρονικές επικοινωνίες (ePrivacy Regulation),
-H Ευρωπαϊκή Επιτροπή να αναθέσει στον Οργανισμό Θεμελιωδών Δικαιωμάτων της ΕΕ (FRA) την εκπόνηση λεπτομερούς μελέτης για την σχετική νομοθεσία των κρατών μελών και την συμβατότητα αυτής με τη νομολογία του ΔΕΕ και τις διατάξεις του Χάρτη, και
-Η Ευρωπαϊκή Επιτροπή να λάβει µέτρα κατά των κρατών µελών στα οποία ισχύει νομοθεσία που έρχεται σε αντίθεση με τη νομολογία του ΔΕΕ και τις διατάξεις του Χάρτη, µε την κίνηση διαδικασιών επί παραβάσει.
Η Ευρωπαϊκή Ένωση βασίζεται στις αρχές της ελευθερίας, της δημοκρατίας, του σεβασμού των ανθρωπίνων δικαιωμάτων και των θεμελιωδών ελευθεριών, ενώ τα κράτη μέλη της Ευρωπαϊκής Ένωσης πρέπει να έχουν ως κοινό χαρακτηριστικό την προσήλωση σε αυτές τις αρχές. Επομένως, η νομοθεσία στον τομέα της διατήρησης των δεδομένων ηλεκτρονικών επικοινωνιών θα πρέπει να βρίσκεται σε πλήρη εναρμόνιση με αυτές, σύμφωνα με τις κατευθυντήριες γραμμές που έχει ορίσει μέσα από τη νομολογία του το Δικαστήριο της Ευρωπαϊκής Ένωσης.

Τεχνολογίες Προστασίας της Ιδιωτικότητας στο Διαδίκτυο: Μύθοι και Πραγματικότητα
Γράφει ο Γιάννης Κωνσταντινίδης*
Αυτό το άρθρο εξετάζει επιφανειακά τρεις βασικές τεχνολογίες που χρησιμοποιούνται για την πρόσβαση σε υπηρεσίες του Διαδικτύου και αναδεικνύει τους μηχανισμούς που επιτρέπουν την περαιτέρω ενίσχυση της ιδιωτικότητας των χρηστών. Παράλληλα, αποσαφηνίζει μερικές λανθασμένες αντιλήψεις σχετικά με τη φύση και τη λειτουργία αυτών των τεχνολογιών και προτείνει τρόπους προφύλαξης από συνηθισμένες κακόβουλες ενέργειες.
HTTPS
Τα HTTP και HTTPS πρόκειται για δύο πρωτόκολλα που χρησιμοποιούνται στη δικτυακή επικοινωνία στο επίπεδο των εφαρμογών και είναι ιδιαίτερα γνωστά για την πρόσβαση σε υπηρεσίες του ιστού, κοινώς για την περιήγηση σε ιστοσελίδες, μέσα από κάποιον φυλλομετρητή ιστού (web browser).
Το HTTPS, σε αντίθεση με το HTTP, διαθέτει πρόσθετα χαρακτηριστικά ασφάλειας και αξιοποιεί το κρυπτογραφικό πρωτόκολλο TLS για την προστασία της εμπιστευτικότητας (confidentiality) και της ακεραιότητας (integrity) των δεδομένων που μεταδίδονται. Αυτό είναι ιδιαίτερα σημαντικό στην περίπτωση που αποστέλλονται «ευαίσθητες» πληροφορίες, όπως π.χ. κωδικοί πρόσβασης σε ιστοσελίδες.
Απεναντίας, στο πρωτόκολλο HTTP τα δεδομένα διαβιβάζονται σε μορφή απλού κειμένου (plain text) και επομένως είναι πάρα πολύ εύκολη η υποκλοπή ή/και η τροποποίηση τους από τρίτους.
Στο Διαδίκτυο, αρκετές φορές, γίνεται αναφορά αποκλειστικά στο πρωτόκολλο SSL. Ωστόσο, τo πρωτόκολλο SSL πλέον δε χρησιμοποιείται στην πράξη και έχει αντικατασταθεί από το TLS. Ένας από τους λόγους που εξακολουθεί να επικρατεί το ακρωνύμιο SSL είναι ενδεχομένως η εξαιρετικά δημοφιλής βιβλιοθήκη OpenSSL που υλοποιεί τα προαναφερόμενα πρωτόκολλα. Παρομοίως, πολύ συχνά υπάρχει αναφορά ως SSL/TLS σε υλοποιήσεις του πρωτοκόλλου TLS.
Δυστυχώς, το TLS δεν προσφέρει προστασία από επιθέσεις ανάλυσης της δικτυακής κίνησης (traffic analysis attacks). Ναι μεν τα δεδομένα μεταφέρονται κρυπτογραφημένα και παρέχεται έλεγχος της ακεραιότητας τους, αλλά κάποιος κακόβουλος χρήστης μπορεί να παρακολουθήσει τα δικτυακά πακέτα που μεταφέρονται και να αντλήσει βασικές πληροφορίες όπως για παράδειγμα τους ιστότοπους που επισκέπτεται το «θύμα» του.
Πιστοποιητικά
Το παρόν άρθρο δεν σκοπεύει να μελετήσει αναλυτικά τον τρόπο με τον οποίο λειτουργούν τα ψηφιακά πιστοποιητικά, ούτε και να εξηγήσει την εκκίνηση της διαδικασίας ασφαλούς σύνδεσης–που ονομάζεται χειραψία (handshake)–μεταξύ του χρήστη και της Διαδικτυακής υπηρεσίας.
Κάθε Διαδικτυακή υπηρεσία που επιθυμεί να υποστηρίξει ασφαλείς συνδέσεις, μέσω HTTPS και TLS, καλείται να εφαρμόσει και να εγκαταστήσει ένα πιστοποιητικό το οποίο εγκρίνεται από μια αρχή πιστοποίησης (certificate authority). Σκοπός είναι να ταυτοποιηθεί η Διαδικτυακή υπηρεσία και να εξασφαλιστεί ότι οι εκάστοτε χρήστες επικοινωνούν με την επιθυμητή υπηρεσία.
Οι φυλλομετρητές ιστού είναι εξαρχής προγραμματισμένοι να αναγνωρίζουν ψηφιακά πιστοποιητικά που εγκρίνονται από αξιόπιστες αρχές πιστοποίησης, ειδάλλως εμφανίζουν προειδοποιητικά μηνύματα και είναι στην αποκλειστική ευχέρεια του χρήστη να επιλέξει εάν θα ανταλλάξει πληροφορίες με την αντίστοιχη ιστοσελίδα.
Τέλος, κάθε πιστοποιητικό διαθέτει ημερομηνία λήξης και πρέπει να ακολουθηθεί συγκεκριμένη διαδικασία (από τον ιδιοκτήτη του) για την ανανέωση του.
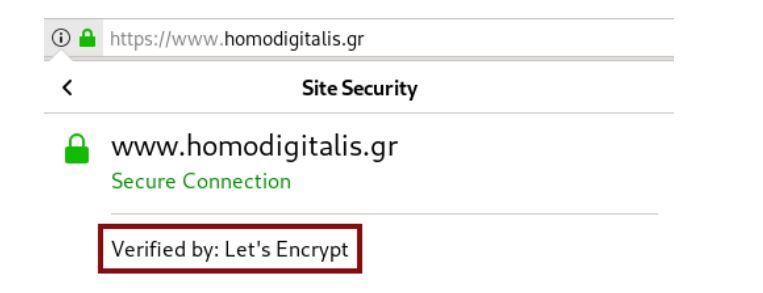
Στην μπάρα πλοήγησης του φυλλομετρητή ιστού όπου διακρίνεται το https://www.homodigitalis.gr, έχει πραγματοποιηθεί σύνδεση μέσω HTTPS (και ακολούθως TLS) στην ιστοσελίδα της Homo Digitalis και η αρχή πιστοποίησης Let’s Encrypt (επισημασμένη σε κόκκινο πλαίσιο) επιβεβαιώνει την ταυτότητα της Homo Digitalis.
Συχνές Παγίδες
Αρκετές προχωρημένες επιθέσεις «ψαρέματος» (phishing) που έχουν στόχο την υποκλοπή στοιχείων, όπως π.χ. λογαριασμών χρηστών και αριθμών πιστωτικών/χρεωστικών καρτών, χρησιμοποιούν πιστοποιητικά και υλοποιούν ιστοσελίδες πανομοιότυπες με τις πραγματικές ξεγελώντας με αυτόν τον τρόπο τα υποψήφια «θύματα» τους.
Συνήθως προηγείται η αποστολή ενημερωτικού μηνύματος μέσω ηλεκτρονικής αλληλογραφίας ή μέσω κοινωνικού δικτύου που προτρέπει τον χρήστη σε κάποια ενέργεια επισκεπτόμενος την (φαινομενικά πραγματική) ιστοσελίδα.
Στα παρακάτω στιγμιότυπα φαίνονται δύο τέτοιες καλοστημένες απόπειρες υποκλοπής. Ας δοθεί όμως προσοχή στους συνδέσμους (επισημασμένοι σε κόκκινα πλαίσια) – στο ένα στιγμιότυπο είναι π.χ. https://instagram.com-unsuspend.mx και όχι https://instagram.com όπως φυσιολογικά θα έπρεπε.
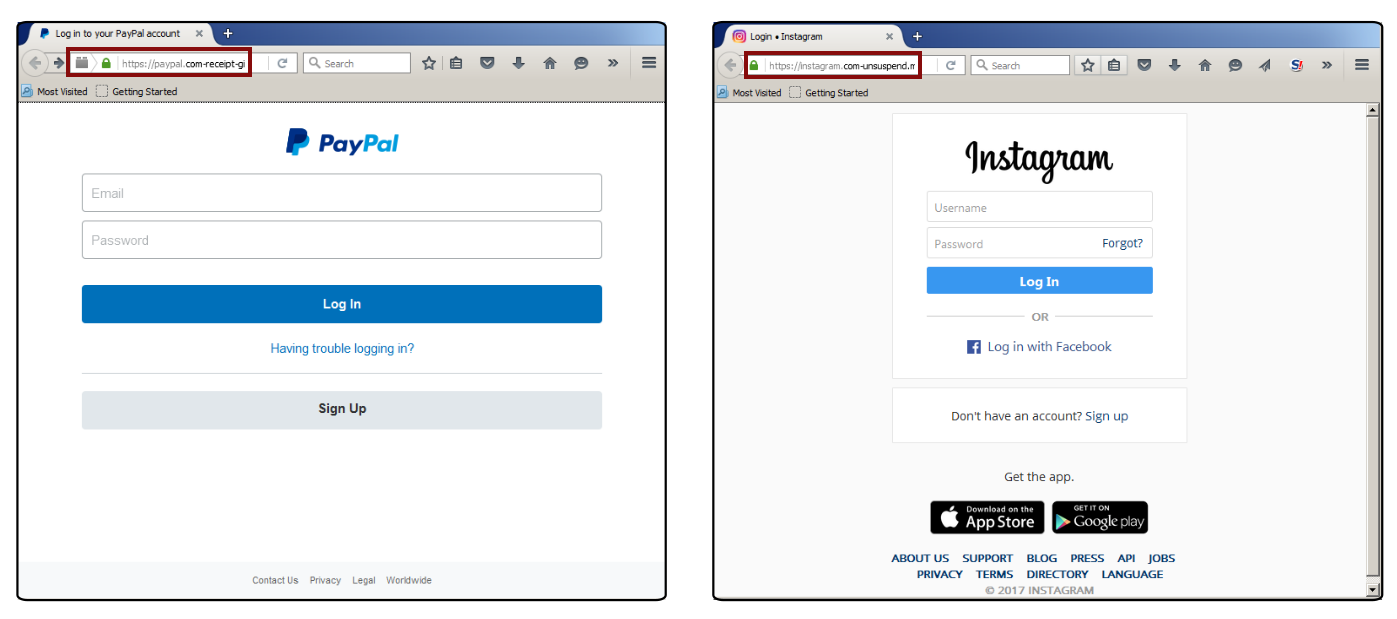 Στιγμιότυπα όπου φαίνονται ιστοσελίδες ψαρέματος πανομοιότυπες με τις πραγματικές, αλλά με κύρια διαφορά τους συνδέσμους που διαφέρουν από τους γνωστούς και πραγματικούς. Γίνεται χρήση πιστοποιητικών, ωστόσο αυτό δε σημαίνει ότι δε μπορούν να πραγματοποιηθούν κακόβουλες ενέργειες.
Στιγμιότυπα όπου φαίνονται ιστοσελίδες ψαρέματος πανομοιότυπες με τις πραγματικές, αλλά με κύρια διαφορά τους συνδέσμους που διαφέρουν από τους γνωστούς και πραγματικούς. Γίνεται χρήση πιστοποιητικών, ωστόσο αυτό δε σημαίνει ότι δε μπορούν να πραγματοποιηθούν κακόβουλες ενέργειες.
Πηγη: https://blogs.cisco.com/security/the-light-is-green-but-is-it-safe-to-go-abusing-users-faith-in-https
Πολύ μεγάλη προσοχή, λοιπόν, πρέπει να δίνεται στο σύνδεσμο (URL) που φαίνεται στη μπάρα διεύθυνσης (address bar) του φυλλομετρητή ιστού. Οι σύνδεσμοι προς phishing ιστοσελίδες τείνουν να μοιάζουν σε σημαντικό βαθμό με τους πραγματικούς συνδέσμους, αλλά παρόλα αυτά εμφανίζουν διαφορές.
Δηλαδή, υπάρχει ουσιώδης διαφορά μεταξύ https://www.homodigitalis.gr (πραγματικός σύνδεσμος) και https://www.h0modigitalis.gr (ψεύτικος σύνδεσμος).
Το γεγονός ότι το https://www.h0modigitalis.gr μπορεί να διαθέτει πιστοποιητικό και ότι ακολούθως ο φυλλομετρητής ιστού παρουσιάζει το περίφημο «πράσινο λουκέτο» δεν εξασφαλίζει ότι δεν πρόκειται για κακόβουλη ιστοσελίδα. Απλά υποδηλώνει, σύμφωνα με όσα ειπώθηκαν και παραπάνω στο άρθρο, ότι όντως υπάρχει σύνδεση με το https://www.h0modigitalis.gr και ότι η σύνδεση είναι κρυπτογραφημένη. Δεν προστατεύει, συνεπώς, τους χρήστες από εκλεπτυσμένες επιθέσεις phishing.
VPNs
Τα εικονικά ιδιωτικά δίκτυα (virtual private networks) μπορούν να χρησιμοποιηθούν ως ενδιάμεσοι κόμβοι μεταξύ του χρήστη και της εκάστοτε Διαδικτυακής υπηρεσίας. Αναλαμβάνουν ουσιαστικά την παραλαβή των δεδομένων από τον αποστολέα και την επαναπροώθηση τους στο δέκτη.
Μπορούν να χρησιμοποιηθούν στην απόκρυψη της δικτυακής κίνησης και με αυτόν τον τρόπο κάποιος κακόβουλος αναλυτής που παρακολουθεί τις επικοινωνίες, ή ακόμα και ο πάροχος υπηρεσιών Διαδικτύου (Internet service provider), δεν είναι σε θέση να γνωρίζει επακριβώς τη συμπεριφορά του χρήστη.
Υπάρχουν φυσικά, υπό προϋποθέσεις, μερικές εξαιρέσεις σε αυτό αν και προς το παρόν δεν πρόκειται να γίνει λεπτομερής αναφορά σε αυτές. Η χρήση VPNs ως ένα επιπρόσθετο μέτρο προστασίας είναι επομένως ιδανική για τη σύνδεση σε δίκτυα που δε θεωρούνται ασφαλή, όπως π.χ. σε κάποιο ανοικτό (open) ασύρματο σημείο πρόσβασης που μπορεί να παρακολουθείται. Επιπλέον, με τη σύνδεση σε VPNs μπορούν να παρακαμφθούν γεωγραφικοί ή άλλοι περιορισμοί που τακτικά ορίζονται από τις υπηρεσίες Διαδικτύου.
Όπως αναφέρθηκε προηγουμένως, οι συνδέσεις μέσω HTTPS προστατεύουν το περιεχόμενο των μηνυμάτων που μεταδίδονται αλλά μπορούν να «προδώσουν» κάποια βασικότερα στοιχεία συμπεριλαμβανομένων των ιστοτόπων που επισκέπτεται οποιοσδήποτε χρήστης. Σε συνδυασμό βέβαια με τη σύνδεση σε VPNs μπορεί να αποφευχθεί αυτό το ενδεχόμενο.
Με μια αναζήτηση στο Διαδίκτυο, μπορούν να βρεθούν πολλοί πάροχοι συνδρομητικών υπηρεσιών για πρόσβαση σε VPNs. Συνιστάται η λεπτομερής έρευνα και η προσεκτική επιλογή ενός παρόχου που διαθέτει καλή φήμη και αξιολογήσεις.
Διαφορετικά υπάρχει κίνδυνος οι πάροχοι να καταγράφουν (logging) τις δραστηριότητες των συνδρομητών τους σε ειδικά αρχεία, ή/και να βασίζονται σε παρωχημένες τεχνολογίες και πρωτόκολλα, ή/και να έχουν πραγματοποιήσει κακή υλοποίηση με αποτέλεσμα να εκτίθενται σημαντικά στοιχεία για τους συνδρομητές και τη συμπεριφορά τους. Εξαιρετικά σημαντικό επίσης είναι να χρησιμοποιούνται τα πρωτόκολλα IKEv2/IPSec ή OpenVPN τα οποία θεωρούνται αξιόπιστα.
DNS
Κάθε συσκευή που συνδέεται στο Διαδίκτυο αποκτά μία μοναδική διεύθυνση IP που είναι εύκολα κατανοητή και διαχειρίσιμη από τους ηλεκτρονικούς υπολογιστές αλλά ομολογουμένως απομνημονεύεται δυσκολότερα από τον άνθρωπο.
Μία τυπική IPv4 διεύθυνση έχει τη μορφή xxx.xxx.xxx.xxx και αναπαρίσταται με δεκαδικό συμβολισμό (decimal notation), ενώ μια νεότερου τύπου IPv6 διεύθυνση έχει τη μορφή xxxx:xxxx:xxxx:xxxx και αναπαρίσταται με δεκαεξαδικό συμβολισμό (hexadecimal notation).
Το σύστημα ονομάτων χώρου (domain name system) έχει ως σκοπό να αντιστοιχίζει ορισμένες από τις διευθύνσεις αυτές με ονόματα χώρου (domain names). Κάθε φορά που χρησιμοποιείται για παράδειγμα το ευκολομνημόνευτο όνομα χώρου homodigitalis.gr, αυτό μεταφράζεται απευθείας στη διεύθυνση IPv4 95.216.16.146.
Την αντιστοίχιση αυτή αναλαμβάνουν οι εξυπηρετητές DNS (DNS servers), οι οποίοι είναι κεντρικοί υπολογιστές που βρίσκονται σε κάθε μέρος του πλανήτη και ανήκουν τυπικά σε παρόχους υπηρεσιών και μεγάλους δημόσιους και ιδιωτικούς οργανισμούς.
Οι περισσότεροι από αυτούς τους εξυπηρετητές τείνουν να διατηρούν αρχεία καταγραφής (logs), δηλαδή έχουν τη δυνατότητα να σημειώνουν τα αιτήματα για συσχετίσεις μεταξύ διευθύνσεων και ονομάτων χώρων που πραγματοποιούν οι χρήστες.
Οι οικιακοί ηλεκτρονικοί υπολογιστές που συνδέονται στο Διαδίκτυο, μέσω των γνωστών παρόχων υπηρεσιών Διαδικτύου, συνήθως χρησιμοποιούν τους προεπιλεγμένους ανά τοποθεσία εξυπηρετητές DNS των παρόχων. Γενικά υπάρχει η δυνατότητα για αλλαγή των ρυθμίσεων στο επίπεδο του οικιακού διαποδιαμορφωτή/δρομολογητή (modem/router) που διαθέτει ο συνδρομητής, ή έστω στο επίπεδο του λειτουργικού συστήματος μέσω του προεγκατεστημένου λογισμικού διαχείρισης δικτύου (network management), ούτως ώστε να οριστούν εξυπηρετητές DNS διαφορετικοί από τους προκαθορισμένους.
Με μία σχετική αναζήτηση στο Διαδίκτυο μπορούν να βρεθούν διευθύνσεις γνωστών εξυπηρετητών DNS που υπόσχονται το σεβασμό της ιδιωτικότητας των χρηστών τους.
DNS Leaks
Πολλοί πάροχοι VPNs κατέχουν και λειτουργούν ιδιωτικούς εξυπηρετητές DNS για την προστασία της ιδιωτικότητας των συνδρομητών τους. Όμως, εάν έχουν καταχωρηθεί εσφαλμένες ρυθμίσεις για τη δικτύωση με το VPN ή/και σε κάποιες άλλες ειδικότερες περιπτώσεις, υπάρχει το ενδεχόμενο να χρησιμοποιηθούν οι προεπιλεγμένοι εξυπηρετητές DNS του παρόχου υπηρεσιών Διαδικτύου αντί για τους ιδιωτικούς εξυπηρετητές DNS του παρόχου VPN.
Άρα, με λίγα λόγια, ο πάροχος υπηρεσιών Διαδικτύου θα είναι δυνητικά σε θέση να γνωρίζει στοιχεία για τη συμπεριφορά του χρήστη παρόλο που γίνεται χρήση υπηρεσίας VPN. Αυτό το φαινόμενο ονομάζεται διαρροή DNS (DNS leak). Στο Διαδίκτυο υπάρχουν αρκετά εργαλεία για τον έλεγχο και τον εντοπισμό τέτοιων διαρροών.
Σκέψεις και Συμπεράσματα
Τα τελευταία τριάντα έτη έχουν προκύψει ραγδαίες εξελίξεις στο χώρο της πληροφορικής και των τηλεπικοινωνιών. Πλέον μεταφέρονται με άνεση τεράστιοι όγκοι προσωπικών δεδομένων από ένα σημείο του πλανήτη σε ένα άλλο, μέσα σε λίγα δευτερόλεπτα.
Μεγάλες εταιρείες και οργανισμοί διατηρούν κολοσσιαία σύνολα από ψηφιακά αρχεία που περιέχουν λεπτομέρειες για τις πολύπλευρες πτυχές του ιδιωτικού βίου εκατομμυρίων ανθρώπων.
Πέραν από τις τεχνολογίες που μπορούν να χρησιμοποιηθούν για την ενίσχυση της ιδιωτικότητας των χρηστών του Διαδικτύου, εξίσου σημαντική είναι η ευαισθητοποίηση (awareness) των ατόμων γύρω από τους κινδύνους που ελλοχεύουν από την αλόγιστη και ανήθικη συλλογή και επεξεργασία προσωπικών δεδομένων και η απαίτηση από τους οργανισμούς να χειρίζονται τα προσωπικά δεδομένα με σύνεση εφαρμόζοντας κατάλληλα τεχνικά και οργανωτικά μέτρα. Μόνο έτσι μπορούν να γίνονται σκέψεις για ένα πραγματικά ασφαλές Διαδίκτυο.
*Ο Γιάννης Κωνσταντινίδης είναι τελειόφοιτος φοιτητής στο Τμήμα Μηχανικών Πληροφοριακών και Επικοινωνιακών Συστημάτων του Πανεπιστημίου Αιγαίου. Συμμετέχει επί έτη σε πολλαπλά έργα ελεύθερου και ανοικτού λογισμικού και δίνει ομιλίες σχετικά με θέματα ιδιωτικότητας και προστασίας δεδομένων, πνευματικών δικαιωμάτων και ανοικτών τεχνολογιών.

Πώς θα ενισχυθεί η προστασία των δικαιωμάτων του παιδιού στο ψηφιακό περιβάλλον;
Γράφει η Αναστασία Καραγιάννη*
Πριν λίγες εβδομάδες κλείσαμε ένα χρόνο από τη θέση σε ισχύ του Γενικού Κανονισμού για την Προστασία των Προσωπικών Δεδομένων της Ευρωπαϊκής Ένωσης [1].
Κάποιοι μπορούν να υποστηρίξουν ότι η υιοθέτηση του Κανονισμού συνέβαλε στην ουσιαστική προστασία των δικαιωμάτων του παιδιού στον ψηφιακό χώρο, καθώς με βάση τον Κανονισμό χρειάζεται η συγκατάθεση των γονέων τόσο για την συλλογή, αποθήκευση, επεξεργασία και διανομή των προσωπικών δεδομένων του παιδιού, όσο και για την συμμετοχή του στην κοινωνία της πληροφορίας.
Άλλοι, αντιθέτως, μπορούν να υποστηρίξουν ότι όντως ο Κανονισμός έθεσε κάποιες βάσεις για την παιδική προστασία στον ψηφιακό χώρο.
Ωστόσο, οι προκλήσεις είναι ακόμη πολλές και ο δρόμος προς την ουσιαστική κατοχύρωση και εφαρμογή των δικαιωμάτων του παιδιού στον ψηφιακό χώρο είναι μακρύς.
Κατά πρώτο λόγο, ένα από τα θεμελιώδη δικαιώματα του παιδιού που χρήζει προστασίας στο ψηφιακό περιβάλλον είναι το δικαίωμα συμμετοχής και το δικαίωμα να ακούγεται και να λαμβάνεται υπόψη η γνώμη του παιδιού κατά την λήψη των αποφάσεων. Τα παιδιά, μολονότι είναι ενεργά στο διαδίκτυο, και εν γένει στον ψηφιακό χώρο, δεν έχουν την δυνατότητα να συμμετέχουν κατά την λήψη των αποφάσεων. Με άλλα λόγια, δε δίνεται η δυνατότητα στο παιδί να εκφράσει την άποψή του, τις επιθυμίες του και τις εμπειρίες του προτού ληφθούν οι πολιτικές αποφάσεις που θα επηρεάσουν σημαντικά την ζωή του.
Για παράδειγμα, ο Οργανισμός Eurochild διοργανώνει σε ετήσια βάση ένα Συνέδριο στο οποίο συμμετέχουν παιδιά ηλικίας 11 έως 16 ετών, που εκπροσωπούν κάθε κράτος μέλος της Ευρωπαϊκής Ένωσης, και εκφράζουν την άποψή τους πάνω σε συγκεκριμένα ζητήματα που τίθενται προς συζήτηση.
Κατ’ αυτόν τον τρόπο, τα παιδιά αλληλεπιδρούν τόσο μεταξύ τους, όσο και με ειδικούς εμπειρογνώμονες και πολιτικούς, οι οποίοι αν και δεν συμμετέχουν στο συμβούλιο, λαμβάνουν υπόψη κατά την λήψη των αποφάσεων τις απόψεις που υποστηρίχθηκαν σε αυτό.
Ακόμη, η Unicef διοργανώνει συναντήσεις και σεμινάρια, στα οποία μπορούν να συμμετέχουν τα παιδιά και να αλληλεπιδρούν μεταξύ τους καθώς και με ειδικούς της Unicef. Το υλικό που προκύπτει από αυτές τις συναντήσεις χρησιμοποιείται από την Unicef κατά την διαδικασία λήψης πολιτικών αποφάσεων.
Η εφαρμογή του δικαιώματος συμμετοχής δεν συνεπάγεται απαραίτητα την κατοχύρωση μιας θέσης, μιας ‘καρέκλας’, κατά την πολιτική συνδιάσκεψη. Αντιθέτως, σημαίνει την ενίσχυση του ενεργητικού ρόλου του παιδιού σε ζητήματα που το αφορούν και, κατά συνέπεια, της ψηφιακής κοινωνικής του υπευθυνότητας σε μία δημοκρατική κοινωνία.
Η επιρροή της συμμετοχής των παιδιών στις πολιτικές αποφάσεις καθορίζει και τον βαθμό αποτελεσματικότητας της συμμετοχής. Οι υπεύθυνοι χάραξης πολιτικής δεν αρκεί να διαβουλεύονται με τα παιδιά, αλλά να είναι πράγματι διατεθειμένοι να αλληλεπιδράσουν μαζί τους και να ακούσουν πράγματι την γνώμη τους, λαμβάνοντάς την σοβαρά υπόψη.
«Ο γονέας ή ο ασκών την γονική μέριμνα θα πρέπει να ‘ακούει’ τις κοινωνικές και ψυχολογικές ανάγκες του παιδιού, ώστε να το εκπαιδεύει κατάλληλα.»
Με αυτόν τον τρόπο, η δημιουργία μιας κουλτούρας φιλικής και ανοιχτής για αλληλεπίδραση με το παιδί ενισχύει την μείωση του ψηφιακού αναλφαβητισμού. Πιο συγκεκριμένα, ο ψηφιακός αλφαβητισμός δεν είναι μόνο η εκμάθηση τεχνικών γνώσεων, αλλά και η σωστή χρήση αυτών των δεξιοτήτων. Ο γονέας ή ο ασκών την γονική μέριμνα θα πρέπει να ‘ακούει’ τις κοινωνικές και ψυχολογικές ανάγκες του παιδιού, ώστε να το εκπαιδεύει κατάλληλα. Για παράδειγμα, αν το παιδί χρησιμοποιεί μία εφαρμογή εκγύμνασης ή απώλειας βάρους, που χρειάζεται τα βιομετρικά του δεδομένα, θα πρέπει να ενημερώσει το παιδί για τους κινδύνους παραβίασης των προσωπικών του δεδομένων που χειρίζεται αυτή η εφαρμογή. Ο ψηφιακός αλφαβητισμός, λοιπόν, δεν είναι μόνο η πληροφόρηση, αλλά και η σωστή πληροφόρηση.
Πολλές φορές, εξαιτίας της περιορισμένης πρόσβασης στην πληροφορία, λόγω έλλειψης τεχνικού εξοπλισμού ή περιορισμένης πρόσβασης στο διαδίκτυο, εμφανίζονται συμπεριφορές διακριτικής μεταχείρισης στον ψηφιακό χώρο, όπως ρατσιστικές, ξενοφοβικές, ομοφοβικές και σεξιστικές εκδηλώσεις.
Για αυτόν τον λόγο, οι ίσες ευκαιρίες πρόσβασης στην ψηφιακή γνώση, η υλοποίηση προγραμμάτων κατάρτισης, καθώς και η αύξηση των πόρων προκειμένου όλα τα παιδιά, από κάθε μειονοτική ομάδα και ευαλωτότητα, να έχουν πρόσβαση στα απαραίτητα εργαλεία και εξοπλισμό, συμβάλλει στην ενίσχυση του ψηφιακού αλφαβητισμού.
Ωστόσο, θα πρέπει να υπογραμμισθεί ότι και οι ενήλικες, οι γονείς και οι ασκούντες την γονική μέριμνα, χρειάζονται επιμόρφωση και κατάρτιση για την εξοικείωσή τους με τον ψηφιακό χώρο και τις προκλήσεις που αυτός θέτει.
Μιλώντας για εξοικείωση και γονείς, φυσικά δε θα μπορούσαμε να μην αναφερθούμε στον ρόλο των γονέων και των ασκούντων την γονική μέριμνα. Συγκεκριμένα, είναι σημαντικό οι γονείς να ξεπεράσουν την ιδεολογία του ‘προστατευτισμού’, της υπερβολικής αντίδρασης και της μονοδιάστατης λήψης των αποφάσεων, προστατεύοντας στην ουσία το βέλτιστο συμφέρον του παιδιού, επιτελώντας δηλαδή τον κύριο ρόλο τους ως γονείς και ασκούντες την γονική μέριμνα.
Οι γονείς και οι ασκούντες την γονική μέριμνα καλούνται να καλύψουν τις σωματικές, ψυχικές, πνευματικές και κοινωνικές ανάγκες του παιδιού, ακούγοντας πραγματικά τις ανάγκες και επιθυμίες του.
Τα παιδιά έχουν μεγαλώσει, πλέον, στον ψηφιακό χώρο. Είναι πολίτες του διαδικτύου, και το ίδιο καλούνται να κάνουν και οι γονείς και οι ασκούντες την γονική μέριμνα.
Γι’ αυτόν τον λόγο, οι γονείς και οι ασκούντες την γονική μέριμνα θα πρέπει να προσαρμοστούν στο ψηφιακό περιβάλλον, να ενημερώνονται για τους κινδύνους που κρύβει ζητώντας την υποστήριξη του κράτους και της κοινωνίας των πολιτών.
«Οι γονείς και οι ασκούντες την γονική μέριμνα θα πρέπει να εξοικειώσουν τα παιδιά από μικρή ηλικία με την έννοια της ιδιωτικότητας και των προσωπικών δεδομένων και να ελέγχουν την αλόγιστη έκθεσή τους στα μέσα κοινωνικής δικτύωσης.»
Φυσικά, όσο επάγρυπνοι πρέπει να είναι οι γονείς ή οι ασκούντες την γονική μέριμνα με τους κινδύνους του διαδικτύου, τόσο προσεκτικοί πρέπει να είναι με τη δική τους ψηφιακή συμπεριφορά, όπως για παράδειγμα με τις φωτογραφίες και τις πληροφορίες των παιδιών που οι ίδιοι δημοσιεύουν στα μέσα κοινωνικής δικτύωσης και εν γένει στο διαδίκτυο. Αυτό σημαίνει επίσης ότι οι γονείς και οι ασκούντες την γονική μέριμνα θα πρέπει να εξοικειώσουν τα παιδιά από μικρή ηλικία με την έννοια της ιδιωτικότητας και των προσωπικών δεδομένων και να ελέγχουν την αλόγιστη έκθεσή τους στα μέσα κοινωνικής δικτύωσης. Μόνο με αυτόν τον τρόπο, το παιδί θα μπορέσει να βάλει όρια στο ψηφιακό περιβάλλον, να περιορίσει τις παραβιάσεις των δικαιωμάτων του και να τα προστατεύσει.
Συνοψίζοντας, τόσο τα κράτη όσο και o ιδιωτικός τομέας, οι εταιρίες μάρκετινγκ και διαφήμισης, θα πρέπει να θεωρούν τα παιδιά ως κατόχους δικαιωμάτων, να περιορίζουν τις πρακτικές χειραγώγησης και εκμετάλλευσης και τις παραβιάσεις της ιδιωτικής τους ζωής και των δικαιωμάτων τους.
Από την άλλη πλευρά, τα παιδιά θα πρέπει να ενημερωθούν και να κατανοήσουν τις τακτικές και παραπλανητικές μορφές του ψηφιακού μάρκετινγκ, ούτως ώστε να αναπτύξουν κριτική σκέψη και να προστατεύσουν τα δικαιώματά τους ως καταναλωτές.
Η αναγνώριση των παιδιών ως υποκειμένων ψηφιακών δικαιωμάτων καθορίζει σημαντικά την αναγνώριση και προστασία των δικαιωμάτων τους ως ψηφιακών εργαζομένων, ψηφιακών πολιτών, ψηφιακών μαθητών, ψηφιακών καταναλωτών, ψηφιακών ασθενών, ψηφιακών εναγόντων ή κατηγορουμένων.
Η ρύθμιση ενός κατάλληλου νομικού πλαισίου για τα ψηφιακά δικαιώματα των παιδιών είναι απαραίτητη για την ολιστική και ουσιαστική προστασία των δικαιωμάτων των παιδιών.
Ενημερωθείτε για τις δράσεις της Homo Digitalis στα σχολεία της Ευαγγελικής Σχολής Νέας Σμύρνης εδώ και στην Ελληνογαλλική Σχολή Πειραιά “Saint Paul”εδώ.
[1] Να σημειωθεί ότι ακόμη δεν έχει τεθεί προς ψήφιση το νομοσχέδιο εφαρμογής του Κανονισμού στην εθνική μας έννομη τάξη.
*Η Αναστασία Καραγιάννη είναι νομικός με εξειδίκευση στα ψηφιακά δικαιώματα των παιδιών. Είναι μέλος της Homo Digitalis και συνδημιουργός της ChildAct, η οποία έχει ως σκοπό την προστασία των ψηφιακών δικαιωμάτων των παιδιών. Στις 8 Νοεμβρίου 2018 εκπροσώπησε τη Homo Digitalis στη συνεδρίαση με θέμα ‘Facebook και άλλοι κοινωνικοί κίνδυνοι’, που έλαβε χώρα στο Ευρωπαϊκό Κοινοβούλιο.

O GDPR εφαρμόζεται για όλους
Γράφει ο Κωνσταντίνος Κακαβούλης
Στο τέλος Μαΐου, η Βελγική Αρχή Προστασίας Προσωπικών Δεδομένων (“L’Autorité de protection des données -APD”) επέβαλε για πρώτη φορά πρόστιμο για παραβίαση των διατάξεων του Γενικού Κανονισμού Προστασίας Δεδομένων (“GDPR”).
Πιθανότατα ήδη βαρεθήκατε και θέλετε να σταματήσετε να διαβάζετε αυτό το άρθρο. Αν ακούσετε και το ποσό του προστίμου, μάλλον θα σταματήσετε άμεσα: μόλις 2.000 ευρώ.
Και όμως, αυτή η απόφαση είναι πολύ ενδιαφέρουσα. Και αυτό γιατί η Βελγική Αρχή Προστασίας Προσωπικών Δεδομένων επέβαλε το πρόστιμο αυτό σε ένα δήμαρχο!
Ο δήμαρχος αυτός είχε στείλει 2 emails σε δύο κατοίκους της πόλης του σχετικά με την προεκλογική του εκστρατεία. Οι δύο πολίτες είχαν στείλει πρώτοι email στο δήμαρχο, στα οποία του ανέλυαν την ιδέα τους για ένα project στην πόλη τους. Ο δήμαρχος την ημέρα πριν τις τοπικές εκλογές απάντησε στα emails των δύο πολιτών στέλνοντάς τους το πολιτικό του πρόγραμμα.
Η Βελγική Αρχή έκρινε ότι η χρήση των διευθύνσεων emails των δύο πολιτών ήταν καταχρηστική και επέβαλε πρόστιμο.
«Οι δημόσιοι λειτουργοί είναι οι πρώτοι οι οποίοι πρέπει να συμμορφώνονται με το νόμο. Ένας δήμαρχος αναμένεται και οφείλει να γνωρίζει τη νομοθεσία και να συμμορφώνεται με αυτήν.»
Όπως σημείωσε ο Hielke Hijmans, πρόεδρος της Βελγικής Αρχής:«η χρήση προσωπικών δεδομένων από πολιτικούς για εκλογικούς σκοπούς είναι ένα σημαντικό θέμα για τους πολίτες. Οι δημόσιοι λειτουργοί είναι οι πρώτοι οι οποίοι πρέπει να συμμορφώνονται με το νόμο. Ένας δήμαρχος αναμένεται και οφείλει να γνωρίζει τη νομοθεσία και να συμμορφώνεται με αυτήν.»
Τα δεδομένα προσωπικού χαρακτήρα «συλλέγονται για καθορισμένους, ρητούς και νόμιμους σκοπούς και δεν υποβάλλονται σε περαιτέρω επεξεργασία κατά τρόπο ασύμβατο προς τους σκοπούς αυτούς» (άρθρο 5(β) GDPR).
Στη συγκεκριμένη περίπτωση, ο δήμαρχος είχε λάβει τις διευθύνσεις email των δύο πολιτών για ένα πολύ συγκεκριμένο σκοπό. Επέλεξε όμως να τις χρησιμοποιήσει για έναν εντελώς διαφορετικό σκοπό. Η συμπεριφορά του αυτή αποτελεί παραβίαση του GDPR. Μάλιστα, είναι ιδιαίτερα ενδιαφέρον το γεγονός οτι η Βελγική Αρχή εστίασε τη προσοχή της στις διατάξεις του GDPR και όχι στη εθνική νομοθεσία σχετικά με τις ηλεκτρονικές επικοινωνίες.
Τι μας έδειξε λοιπόν η Bελγική Αρχή με την απόφαση αυτή;
Ότι η προστασία προσωπικών δεδομένων είναι ευθύνη όλων!
Η υποχρέωση προστασίας και ορθής επεξεργασίας προσωπικών δεδομένων δε βαρύνει μόνο τις εταιρείες και τους οργανισμούς. Οι δημόσιοι λειτουργοί και οι έχοντες δημόσια αξιώματα υπέχουν επίσης σημαντικότατη ευθύνη. Οφείλουν να συνειδητοποιήσουν ότι προσωπικά δεδομένα τα οποία έχουν συλλέξει κατά την άσκηση δημόσιας εξουσίας, δεν μπορούν σε καμία περίπτωση να χρησιμοποιηθούν για προσωπικό όφελος.
Σαφώς, γνωρίζαμε ήδη από το πεδίο εφαρμογής του GDPR ότι και οι δημόσιοι λειτουργοί οφείλουν να συμμορφώνονται με τον Κανονισμό. Όμως, είναι η πρώτη φορά που μία εθνική Αρχή το εφαρμόζει στην πράξη.
Καθώς οι εθνικές εκλογές πλησιάζουν στη χώρα μας και έχοντας ακόμα νωπές μνήμες από προεκλογικά μηνύματα υποψηφίων στις αυτοδιοικητικές εκλογές και τις Ευρωεκλογές, αναμένουμε να δούμε αν οι υποψήφιοι αυτή τη φορά θα λάβουν υπόψη τα προσωπικά δεδομένα των πολιτών ως ένα αγαθό άξιο προστασίας.
Σε κάθε περίπτωση, αν νιώθετε ότι τα προσωπικά σας δεδομένα παραβιάζονται από υποψηφίους στις επικείμενες εκλογές, μπορείτε να υποβάλετε άμεσα και δωρεάν καταγγελία στην Ελληνική Αρχή Προστασίας Δεδομένων Προσωπικού Χαρακτήρα. Μάλιστα, η Ελληνική Αρχή πρόσφατα δημοσίευσε την απόφασή της για μία παρόμοια σχετικά υπόθεση, με την οποία υποβάλει το πρόστιμο των 2.000 ευρώ σε έναν υποψήφιο ευρωβουλευτή.