
Cookies: η συμβατότητα των ιστοσελίδων με τον Kανονισμό GDPR και την Oδηγία e-Privacy
Γράφει η Καλλιρρόη Γραμμένου*
Οι επισκέπτες ιστοσελίδων βρίσκονται συχνά αντιμέτωποι με δυσνόητες, πυκνογραμμένες πολιτικές απορρήτου και ρυθμίσεις cookies.
Οι περισσότεροι χρήστες δεν έχουν τις τεχνικές γνώσεις να αξιολογήσουν εάν μία ιστοσελίδα συμμορφώνεται προς το ισχύον κανονιστικό πλαίσιο και εάν έχουν πραγματική ή κατ’ επίφαση επιλογή ως προς την τοποθέτηση cookies και την παρακολούθηση της διαδικτυακής συμπεριφοράς και των προτιμήσεών τους.
Τα Cookies είναι μικρά αρχεία κειμένου που αποθηκεύονται στη συσκευή του επισκέπτη μίας ιστοσελίδας. Πολλά από αυτά χρησιμοποιούνται για τη βελτίωση της χρηστικότητας ή της λειτουργικότητας ιστοσελίδων/ εφαρμογών.
Η θέση σε ισχύ του GDPR (Γενικού Κανονισμού για την Προστασία Δεδομένων (ΓΚΠΔ) περιπλέκει ακόμα περισσότερο το τοπίο και δημιουργεί συχνά απορίες και σημεία σύγχυσης.
Η Γαλλική αρχή προστασίας δεδομένων (CNIL) και η Ισπανική Αρχή, με τις νέες κατευθυντήριες γραμμές που εξέδωσαν και το δικαστήριο της ΕΕ, με την σημαντική απόφαση Planet 49 GmbH (υπόθεση C-673/17) παρέχουν χρήσιμες διευκρινίσεις ως προς τις απαιτήσεις συγκατάθεσης των χρηστών για την αποθήκευση cookies στον εξοπλισμό τους.
Παρακάτω επιχειρούμε να εξηγήσουμε με απλό τρόπο τη σύζευξη του κανονισμού GDPR και της οδηγίας ePrivacy αλλά και να δώσουμε κάποιες ενδείξεις στους χρήστες σχετικά με την κατανόηση και την ορθότητα των πολιτικών cookies που χρησιμοποιούν οι πάροχοι ιστοσελίδων.
Οδηγία ePrivacy και GDPR
Η εγκατάσταση και η χρήση «cookies» ρυθμίζεται από την παράγραφο 5 του άρθρου 4 του ν. 3471/2006 (ο οποίος μετέφερε στην ελληνική έννομη τάξη την Οδηγία ePrivacy – 2002/58/ΕΚ (οδηγία για την προστασία ιδιωτικής ζωής στις ηλεκτρονικές επικοινωνίες, γνωστή ως “cookies directive”).
Η βασική αρχή είναι ότι η εγκατάσταση και χρήση cookies επιτρέπεται μόνο με τη συγκατάθεση του χρήστη.
Υπάρχει μία λανθασμένη αντίληψη ότι όλες οι ρυθμίσεις απορρήτου, συμπεριλαμβανομένων των cookies, ανάγονται μόνο στον GDPR. Το δικαστήριο της ΕΕ στην απόφαση Planet 49 αναφέρεται επίσης στην οδηγία ePrivacy 2002/58.
Σκοπός της οδηγίας είναι η προστασία της ιδιωτικής σφαίρας των χρηστών, ανεξαρτήτως εάν συλλέγονται ή όχι προσωπικά δεδομένα μέσω τεχνολογιών ηλεκτρονικής επικοινωνίας.
Είναι σημαντικό να κάνουμε την εξής διάκριση:
- Η οδηγία ePrivacy (cookies directive) ρυθμίζει τον δίαυλο επικοινωνίας (ηλεκτρονική επικοινωνία). Ο κανόνας σχετικά με τη λήψη συγκατάθεσης για την τοποθέτηση cookies εφαρμόζεται ανεξαρτήτως εάν γίνεται επεξεργασία προσωπικών δεδομένων ή όχι.
- Ο ΓΚΠΔ (GDPR) ρυθμίζει τις νομικές βάσεις για τη νομιμότητα της επεξεργασίας των δεδομένων προσωπικού χαρακτήρα και ορίζει την έννοια της συγκατάθεσης. Ο Κανονισμός ορίζει ότι η συγκατάθεση δεν μπορεί να είναι ελεύθερη εάν για την παροχή υπηρεσίας ζητείται συγκατάθεση που δεν είναι αναγκαία για τον συγκεκριμένο σκοπό.
Ως πρακτικό παράδειγμα θα μπορούσαμε να αναφέρουμε την περίπτωση ιστοσελίδας η οποία ζητά συγκατάθεση του επισκέπτη για τη χρήση cookies, ενημερώνοντάς τον ότι με τη συγκατάθεσή του αυτή συμφωνεί επίσης στη χρήση των στοιχείων του για επιπλέον σκοπούς, πλην της ζητηθείσας υπηρεσίας (bundled consent).
Ο GDPR ορίζει με σαφήνεια την έννοια της έγκυρης συγκατάθεσης στο άρθρο 7. Επιπλέον, στην αιτιολογική σκέψη 32 του GDPR, αναφέρεται ότι « Η συγκατάθεση θα πρέπει να παρέχεται με σαφή θετική ενέργεια η οποία να συνιστά ελεύθερη, συγκεκριμένη, ρητή και εν πλήρει επιγνώσει ένδειξη της συμφωνίας του υποκειμένου των δεδομένων υπέρ των δεδομένων που τον αφορούν. […] η σιωπή, τα προσυμπληρωμένα τετραγωνίδια ή η αδράνεια δεν θα πρέπει να εκλαμβάνονται ως συγκατάθεση.»
Το τέλος του soft opt-in
Μέχρι σήμερα, το τοπίο σχετικά με τη χρήση των cookies και τις ρυθμίσεις απορρήτου των ιστοσελίδων (sites) ήταν νεφελώδες και διόλου ξεκάθαρο. Αυτό οφειλόταν στις διαφορές ως προς τη μεταφορά της οδηγίας ePrivacy στο εσωτερικό δίκαιο κάθε χώρας της ΕΕ αλλά και στην ανοχή που επεδείκνυαν κάποιες αρχές προστασίας δεδομένων σε χώρες όπως η Γαλλία, το Ηνωμένο Βασίλειο και η Γερμανία στη σιωπηρή συγκατάθεση (το επονομαζόμενο “soft opt-in”).
Τι σημαίνει αυτό στην πράξη;
Όταν ο χρήστης επισκέπτεται μία ιστοσελίδα για πρώτη φορά, στο επάνω ή στο κάτω μέρος της ιστοσελίδας υπάρχει ένα cookie banner. Κλείνοντας το ή συνεχίζοντας την επίσκεψη στην ιστοσελίδα (χωρίς καμία περαιτέρω δήλωση), συνάγεται ότι ο χρήστης συναινεί σιωπηρά, άρα αποδέχεται την χρήση των cookies. Πολλές ιστοσελίδες εξακολουθούν να χρησιμοποιούν αυτό το σύστημα.
Παράδειγμα: Cookie banner σε site με το ακόλουθο περιεχόμενο: «Με τη συνέχιση της πλοήγησης αποδέχεστε τη χρήση των cookies».

Η Γαλλική αρχή CNIL ανακοίνωσε ότι αυτή η πρακτική δεν είναι πλέον συμβατή με τον κανονισμό GDPR διότι η σιωπηρή συγκατάθεση δεν είναι έγκυρη.
Εντούτοις, η CNIL όρισε μεταβατική περίοδο 12 μηνών ώστε οι πάροχοι ιστοσελίδων να προσαρμόσουν κατάλληλα τις ρυθμίσεις cookies.
Αυτό οφείλεται επίσης στο ότι ο κανονισμός ePrivacy δεν έχει τεθεί ακόμα σε ισχύ και παραμένουν σημαντικές αποκλίσεις ως προς την εφαρμογή της οδηγίας ePrivacy στο δίκαιο κάθε κράτους μέλους της ΕΕ. Με τη θέση σε ισχύ του κανονισμού ePrivacy, θα ισχύει ένα ενιαίο καθεστώς για όλα τα κράτη μέλη της ΕΕ, επομένως οι πάροχοι ιστοσελίδων θα πρέπει να υπαχθούν σε ομοιογενές καθεστώς συμμόρφωσης ως προς την χρήση cookies. Η γαλλική αρχή αποφάσισε να μην περιμένει τη θέση σε ισχύ του επερχόμενου κανονισμού ePrivacy προκειμένου να επιβάλλει τη συμμόρφωση των παρόχων ιστοσελίδων με ενιαία πρότυπα ρυθμίσεων απορρήτου.
Τι πρέπει να ελέγχουν οι χρήστες προκειμένου να καταλάβουν αν μία ιστοσελίδα εφαρμόζει σωστά τη νομοθεσία για τα cookies;
Σύμφωνα με τις τελευταίες νομολογιακές εξελίξεις και τις κατευθυντήριες γραμμές διαφόρων Αρχών προστασίας δεδομένων προσωπικού χαρακτήρα (με πιο πρόσφατες της οδηγίες της Ισπανικής Αρχής), οι επισκέπτες ιστοσελίδων πρέπει να λάβουν υπόψη τους τα εξής προκειμένου να αποφύγουν την τοποθέτηση ανεπιθύμητων cookies και να προσαρμόσουν τις παραμέτρους απορρήτου όπως επιθυμούν:
-Δεν απαιτείται προηγούμενη συγκατάθεση του χρήστη μόνο για τα λειτουργικά cookies (functional cookies) που είναι απολύτως απαραίτητα για τη λειτουργία της ιστοσελίδας, για την εκτέλεση ηλεκτρονικής επικοινωνίας ή για την παροχή υπηρεσίας της κοινωνίας της πληροφορίας. Χωρίς τη χρήση λειτουργικών cookies είναι αδύνατη η περιήγηση του επισκέπτη στην ιστοσελίδα.
-Για τα υπόλοιπα είδη cookies (πλην των λεγόμενων functional cookies) απαιτείται ενημέρωση του χρήστη και παροχή δυνατότητας να συγκατατεθεί ρητά, με ρητή και θετική ενέργεια (επιλέγοντας ο ίδιος το αντίστοιχο τετραγωνίδιο) ή να αρνηθεί την τοποθέτηση των cookies στον υπολογιστή του (παροχή επιλογών ανά κατηγορία cookies και όχι για όλα αδιακρίτως).
-Η ιστοσελίδα θα πρέπει να παρέχει ενημέρωση στον χρήστη όχι μόνο σχετικά με τα cookies που τοποθετεί στον υπολογιστή του χρήστη (“First Party” Cookie) αλλά και σχετικά με τα cookies από Τρίτα Μέρη (third-party cookies) κυρίως για τους σκοπούς συμπεριφορικής διαφήμισης (Online behavioural advertising – OBA). Κάθε ιστοσελίδα που χρησιμοποιεί συμπεριφορική διαφήμιση οφείλει να παρέχει πληροφορίες σχετικά με την συλλογή και την χρήση δεδομένων, τις οποίες οι χρήστες πρέπει να είναι σε θέση να εντοπίσουν με ευχέρεια.
Σύμφωνα με τις οδηγίες της Ισπανικής Αρχής, πληροφορίες σχετικά με cookies από Τρίτα Μέρη μπορούν να παρέχονται με αναπτυσσόμενη λίστα (drop-down) ή με αναδυόμενο κείμενο (pop-up).
-Οι επισκέπτες ιστοσελίδας πρέπει να παρέχουν τη συγκατάθεσή τους στην τοποθέτηση cookies κατά τρόπο ρητό και σαφή, δηλαδή με δήλωση ή με σαφή θετική ενέργεια (π.χ. με συμπλήρωση τετραγωνιδίου). Κατά συνέπεια, τυχόν προσυμπληρωμένα τετραγωνίδια δεν συνεπάγονται ότι ο χρήστης συναινεί νομίμως στην επεξεργασία, διότι η συγκατάθεσή του δεν είναι ελεύθερη ούτε ρητή (Απόφαση Δικαστηρίου ΕΕ, Planet49 GmbH, σκέψεις 62, 63).
Συνεπώς, προεπιλεγμένο τετραγωνίδιο το οποίο οι χρήστες πρέπει να απο-επιλέξουν προκειμένου να αρνηθούν να δώσουν τη συγκατάθεσή τους δεν είναι συμβατό προς τον κανονισμό GDPR ούτε προς την οδηγία ePrivacy.
-Η πολιτική cookies πρέπει να παρουσιάζεται ευκρινώς και με απλή γλώσσα στην ιστοσελίδα. Η πολιτική πρέπει να περιγράφει με εύληπτο τρόπο τις διαθέσιμες ρυθμίσεις απορρήτου, καθώς και να παρέχει στον χρήστη τη δυνατότητα επιλογής των ρυθμίσεων απορρήτου ανά σκοπό, χωρίς προεπιλεγμένες από τον πάροχο ρυθμίσεις (αρχή της διαφάνειας).
-Οι πληροφορίες τις οποίες ο πάροχος υπηρεσιών πρέπει να παρέχει στον επισκέπτη της ιστοσελίδας περιλαμβάνουν τη διάρκεια λειτουργίας των cookies καθώς και το εάν τρίτοι πάροχοι μπορούν να έχουν πρόσβαση στα cookies (Απόφαση Δικαστηρίου ΕΕ, υπόθεση Planet49 GmbH).
Άλλα στοιχεία που πρέπει να προσέχουν οι χρήστες
Α) Λήψη ξεχωριστής συγκατάθεσης ανά σκοπό επεξεργασίας
Ο χρήστης πρέπει να ελέγχει εάν το αίτημα για λήψη συγκατάθεσης είναι χωριστό ανά σκοπό επεξεργασίας.
Παράδειγμα: ιστοσελίδα ζητά από τον χρήστη να επιλέξει τετραγωνίδιο για να κατεβάσει μία εφαρμογή στο κινητό ή στον υπολογιστή του και ταυτόχρονα τον ενημερώνει ότι με τη συγκατάθεση αυτή συμφωνεί επίσης σε περαιτέρω χρήση των στοιχείων του για διαφημιστικούς σκοπούς. Εν προκειμένω, η συγκατάθεση δεν είναι ελεύθερη, ούτε συγκεκριμένη, διαβαθμισμένη και ελεύθερα ανακλητή. Στη συγκεκριμένη περίπτωση, η συγκατάθεση δίνεται για περισσότερους σκοπούς επεξεργασίας οι οποίοι δεν είναι διακριτοί και η άρνηση του χρήστη να δεχτεί την περαιτέρω επεξεργασία για σκοπούς marketing, τον αποκλείει από την πρόσβαση στην εφαρμογή (bundled consent).
Επομένως οι χρήστες πρέπει να αντιλαμβάνονται ότι μία λήψη συγκατάθεσης πρέπει να αντιστοιχεί σε έναν ευδιάκριτο σκοπό.
Β) Cookie walls
Το Δικαστήριο της ΕΕ στην πρόσφατη απόφαση Planet49 δεν ανέλυσε τη συμβατότητα των cookie walls προς τον κανονισμό GDPR. Ωστόσο, η Ολλανδική αρχή προστασίας δεδομένων διευκρίνισε ότι τα cookie walls δεν είναι συμβατά με τον GDPR.
- Πώς λειτουργούν τα cookie walls;
Τα cookie walls αρνούνται στον επισκέπτη την πρόσβαση σε μία ιστοσελίδα, εάν εκείνος δεν συγκατατεθεί στην εγκατάσταση λογισμικού παρακολούθησης (tracking) ή άλλων ψηφιακών μεθόδων για στοχευμένη διαφήμιση.
Σε αυτή την περίπτωση, οι επισκέπτες ιστοσελίδας εξαναγκάζονται να αποδεχτούν τη χρήση τους προκειμένου να έχουν πρόσβαση στο περιεχόμενό της. Συνεπώς, δεν υπάρχει ρητή και ελεύθερη συγκατάθεση κατά την έννοια του GDPR.
Γ) Soft opt-in
Όταν μία ιστοσελίδα ενημερώνει τον επισκέπτη ότι με την πλοήγησή του αποδέχεται τα cookies, δεν του δίνει τη δυνατότητα να λάβει γνώση και να δεχτεί ή να απορρίψει τη χρήση τους. Έτσι, δίνεται άδεια σε τρίτους παρόχους να εγκαταστήσουν cookies αλλά και να παρέχουν διαφημιστικό περιεχόμενο χωρίς κανέναν έλεγχο και συγκατάθεση από τον ίδιο τον χρήστη.
Η κούραση των χρηστών
Δεδομένου ότι δεν έχει τεθεί ακόμα σε ισχύ ο κανονισμός ePrivacy, δεν έχει αναληφθεί συντονισμένη δράση από όλες τις αρχές προστασίας δεδομένων. Η Αρχή Προστασίας Δεδομένων Προσωπικού Χαρακτήρα (“ΑΠΔΠΧ”), πραγματοποίησε στις αρχές του 2019 ελέγχους σε 65 ιστοσελίδες και διαπίστωσε χαμηλό επίπεδο συμμόρφωσης με τον κανονισμό.
Μένει να δούμε εάν οι υπόλοιπες αρχές προστασίας δεδομένων θα ακολουθήσουν το παράδειγμα της γαλλικής αρχής CNIL και θα παρέχουν κατευθυντήριες γραμμές οι οποίες θα συμβάλλουν στη συμμόρφωση των παρόχων ιστοσελίδων με τις απαιτήσεις του GDPR και της οδηγίας ePrivacy.
Οι χρήστες πρέπει επίσης να αντιληφθούν ότι η πρόσβαση σε πολιτικές απορρήτου που είναι γραμμένες με απλό και κατανοητό τρόπο έχει ως σκοπό το σεβασμό της αρχής της διαφάνειας ως προς τη χρήση των δεδομένων τους, καθώς και την εξατομίκευση των προτιμήσεων απορρήτου, ούτως ώστε να μην εκτίθενται σε συστηματική παρακολούθηση και ανεπιθύμητη διαφήμιση.
Οι μη εξοικειωμένοι χρήστες συχνά δυσανασχετούν με τον αριθμό των ενεργειών που απαιτούνται ώστε να παρέχουν συγκατάθεση και θεωρούν τη διαδικασία ανώφελη (consent fatigue). Είναι ωστόσο χρήσιμο να διαθέτουν τις απαραίτητες γνώσεις προκειμένου να αποφύγουν την εγκατάσταση cookies από τρίτους παρόχους και το να εκθέτουν τις προτιμήσεις τους προς διαφημιστική εκμετάλλευση, χωρίς κανέναν έλεγχο και λογοδοσία. Σε ιστοσελίδα η οποία έχει διαμορφώσει σωστά τις ρυθμίσεις για τα cookies, η διαδικασία αυτή δε διαρκεί πολύ και αρκούν μερικά κλικ από τον χρήστη.
Σε περίπτωση που ο χρήστης εντοπίσει ότι μία ιστοσελίδα δε συμμορφώνεται με το ρυθμιστικό πλαίσιο για τα cookies, μπορεί να προσφύγει στην αρμόδια αρχή προστασίας δεδομένων προσωπικού χαρακτήρα. Εάν πρόκειται για ελληνική ιστοσελίδα, μπορεί να προσφύγει στην ελληνική ΑΠΔΠΧ.
Σημειώνεται ότι η Homo Digitalis, πιστή στις αξίες της, δε χρησιμοποιεί cookies ή άλλες τεχνολογίες στην ιστοσελίδα της προκειμένου να καταγράψει τη δραστηριότητά σας.
*Η Καλλιρρόη Γραμμένου, LL.M., CIPP/E, είναι δικηγόρος Αθηνών, απόφοιτος της Νομικής σχολής του Α.Π.Θ., με LL.M. στο δίκαιο της ΕΕ από τα πανεπιστήμια Λουξεμβούργου/Nancy II. Έχει διατελέσει DPO και νομικός σύμβουλος του εκτελεστικού οργανισμού της ΕΕ CHAFEA. Έχει εργαστεί ως δικηγόρος και σύμβουλος προστασίας προσωπικών δεδομένων στην Ελλάδα και στο Λουξεμβούργο.

Αποζημίωση για ηθική βλάβη σύμφωνα με τον ΓΚΠΔ: Μια νέα περίπτωση
Γράφει ο Γιώργος Αρσένης*
Ένα δικαστήριο στην Αυστρία καταδίκασε μια επιχείρηση σε πληρωμή αποζημίωσης 800,00 Ευρώ σε ένα υποκείμενο δεδομένων για λόγους ηθικής βλάβης, σύμφωνα με το άρθρο 82 του ΓΚΠΔ (GDPR). Η απόφαση δεν έχει τεθεί ακόμα σε ισχύ, λόγω του ότι άσκησαν έφεση και οι δυο πλευρές. Αλλά, σε περίπτωση που το εφετείο επιβεβαιώσει την απόφαση, τότε η επιχείρηση κινδυνεύει -θεωρητικά- να βρεθεί μπροστά σε μια μαζική αγωγή, στην οποία εμπλέκονται περί τα 2 εκατομμύρια υποκείμενα δεδομένων. Φυσικά, η περίπτωση ελκύει το ενδιαφέρον διότι η έκβαση της αναμένεται να αποτελέσει δικαστικό προηγούμενο, με αποτέλεσμα μελλοντικές περιπτώσεις να βασιστούν πάνω σε αυτό το παράδειγμα.
Ας δούμε όμως τα πράγματα από την αρχή, για να καταλάβουμε ποιες επιπτώσεις μπορεί να έχει αυτή η εφαρμογή του άρθρου 82 του ΓΚΠΔ στο δίκαιο άλλων κρατών-μελών της Ευρωπαϊκής Ένωσης.
Profiling
Το ότι ένα ταχυδρομείο συλλέγει και αποθηκεύει συγκεκριμένα προσωπικά δεδομένα πελατών του, δεν είναι κάτι καινούργιο. Μετά όμως από αίτηση ενός υποκειμένου δεδομένων, αποκαλύφθηκε πως το Ταχυδρομείο της Αυστρίας αξιολόγησε και αποθήκευσε δεδομένα που αφορούσαν τις πολιτικές προτιμήσεις περίπου δύο εκατομμυρίων πελατών του.
Η επιχείρηση χρησιμοποίησε στατιστικές μεθόδους όπως το profiling, με στόχο να υπολογίσει τον βαθμό προσκόλλησης ενός ατόμου σε κάποιο αυστριακό κόμμα, βάσει των πολιτικών του πεποιθήσεων (π.χ. μεγάλη πιθανότητα προσκόλλησης στο κόμμα Α; μικρή πιθανότητα προσκόλλησης στο κόμμα Β). Σύμφωνα με δημοσιεύματα, φαίνεται ότι κανένας από τους πελάτες δεν είχε πληροφορηθεί ή δώσει την συγκατάθεση του για αυτήν την επεξεργασία και ότι σε συγκεκριμένες περιπτώσεις οι πληροφορίες αυτές πωλήθηκαν σε τρίτους.
Η ηθική βλάβη έχει τιμή
Ο καθορισμός της αποζημίωσης βασίστηκε σε μια δικαστική μέθοδο, η οποία εφαρμόζεται στην Αυστρία. Σύμφωνα με αυτή, το δικαστήριο έλαβε υπόψη δύο βασικά στοιχεία: (1) το ότι οι πολιτικές απόψεις είναι ένα ιδιαίτερα ευαίσθητο είδος δεδομένων και (2) το ότι η επεξεργασία διεξήχθη εν αγνοία του υποκειμένου των δεδομένων.
Το τοπικό δικαστήριο του Feldkirch, στο ομόσπονδο κρατίδιο Voralberg της Αυστρίας, όπου εκδικάστηκε η υπόθεση σε πρώτο βαθμό, έκρινε ότι η ενόχληση που ένιωσε ο μηνυτής λόγω του profiling στο οποίο υποβλήθηκε χωρίς να δώσει την συγκατάθεση του, συνιστά μη υλική ζημιά, για αυτό και επιδίκασε στον ενάγοντα 800,00 Ευρώ, από τα 2.500,00 Ευρώ που είχε απαιτήσει αρχικά.
Το δικαστήριο αναγνώρισε ότι οι πολιτικές πεποιθήσεις καθιστούν ειδική κατηγορία δεδομένων προσωπικού χαρακτήρα σύμφωνα με το άρθρο 9 του ΓΚΠΔ. Όμως, θεώρησε επίσης, ότι κάθε περίπτωση αντιλαμβανόμενη ως δυσμενή μεταχείριση ή παραβίαση δεν μπορεί να δίνει έναυσμα για διεκδίκηση αποζημιώσεων για μη υλικές ζημιές. Ωστόσο, το δικαστήριο έκρινε ότι σε αυτήν την περίπτωση παραβιάστηκαν θεμελιώδη δικαιώματα του υποκειμένου των δεδομένων.
Ο καθορισμός της αποζημίωσης βασίστηκε σε μια δικαστική μέθοδο, η οποία εφαρμόζεται στην Αυστρία. Σύμφωνα με αυτή, το δικαστήριο έλαβε υπόψη δύο βασικά στοιχεία: (1) το ότι οι πολιτικές απόψεις είναι ένα ιδιαίτερα ευαίσθητο είδος δεδομένων και (2) το ότι η επεξεργασία διεξήχθη εν αγνοία του υποκειμένου των δεδομένων.
Και τώρα;
Η απόφαση δεν αποτελεί έκπληξη. Το άρθρο 82 § 1 του ΓΚΠΔ προβλέπει ξεκάθαρα πληρωμή αποζημιώσεων για μη υλικές ζημιές. Όμως, με τα 2,2 εκατομμύρια εμπλεκόμενα υποκείμενα δεδομένων σε αυτήν την επεξεργασία και με απλά μαθηματικά προκύπτει το ποσό των 1,7 δις ευρώ.
Το σίγουρο είναι, ότι σε περίπτωση που το εφετείο επιβεβαιώσει την απόφαση του πρωτοδικείου, θα υπάρξει πληθώρα παρόμοιων υποθέσεων προς εκδίκαση. Αυτός είναι και ο λόγος που ήδη πολλές επιχειρήσεις, και στην γειτονική Γερμανία, εξειδικεύονται σε διαδικασίες όπως αυτή.
Η ανεξάρτητη αρχή
Μετά την απόφαση του τοπικού δικαστηρίου του Feldkirch στις αρχές Οκτωβρίου, προς το τέλος του ίδιου μήνα και συγκεκριμένα στις 29.10.2019, η αυστριακή αρχή προστασίας δεδομένων (Österreichische Datenschutzbehörde), ανακοίνωσε ότι επέβαλε διοικητική κύρωση ύψους 18 εκατομμυρίων ευρώ στο Ταχυδρομείο της Αυστρίας.
Πέραν των πολιτικών πεποιθήσεων, η Αρχή Προστασίας της Αυστρίας εξακρίβωσε περισσότερες παραβιάσεις. Μέσα από περαιτέρω επεξεργασίες, προέκυπταν στοιχεία σχετικά με την συχνότητα αποστολής δεμάτων, ή την συχνότητα αλλαγής κατοικίας, τα οποία χρησιμοποιούνταν για διαφημιστική προσέγγιση μέσω direct-marketing. Το ταχυδρομείο της Αυστρίας, που κατά το ήμισυ ανήκει στο κράτος, δήλωσε ότι θα κινηθεί δικαστικά εναντίον του διοικητικού μέτρου και δικαιολόγησε τον σκοπό της επεξεργασίας ως θεμιτή ανάλυση αγοράς.
Η ιδιαιτερότητα της ετυμηγορίας
Η ετυμηγορία στο Feldkirch δείχνει ότι τα δικαστήρια μπορούν να καταβάλλουν πληρωμές για «αντιξοότητες» λόγω πραγματικών ή υποτιθέμενων παραβιάσεων δεδομένων. Ο προσφεύγων στην δικαιοσύνη δήλωσε απλά ότι ‘ένιωσε ενοχλημένος’ για το τι έγινε, χωρίς δηλαδή να επικαλεστεί μια ηθική βλάβη που προκλήθηκε μέσα από κάποιο αποτέλεσμα της επεξεργασίας, όπως δυσφήμιση, κατάχρηση πνευματικής ιδιοκτησίας, παρενόχληση μέσω τηλεφωνημάτων ή emails. Μπορείτε να βρείτε εδώ την Απόφαση.
Σε αντίθεση με την ανεξάρτητη αρχή, που επέβαλε την κύρωση για τις πολλαπλές παραβιάσεις διατάξεων του GDPR, το δικαστήριο εστίασε την απόφαση του στην ενόχληση που ένιωσε ο μηνυτής. Η ηθική ζημιά προκλήθηκε από το γεγονός ότι μια εταιρεία επεξεργάζεται δεδομένα κατά παράβαση των διατάξεων του GDPR.
* Ο Γιώργος Αρσένης είναι IT Consultant και DPO. Απόφοιτος του Τμήματος Ειδίκευσης Προγραμματιστών του Ε.Π.Λ. Βέροιας με πολυετή πείρα σε θέματα IT Systems Maintenance & Support, σε χώρες της Ευρώπης. Έχει εργαστεί σε οργανισμούς της Ε.Ε. και στον ιδιωτικό τομέα. Έχει εμπειρία με δίκτυα τηλεπικοινωνιών, δίκτυα CISCO, scientific modelling και συστήματα εικονικών μηχανών. Ελεύθερος επαγγελματίας, εξειδικεύεται στην Διαχείριση Συστημάτων Ασφάλειας Πληροφοριών και Προστασία Προσωπικών Δεδομένων
Ηλεκτρονικά προσβάσιμες πηγές:
- https://digital.freshfields.com/post/102fth1/can-i-claim-damages-for-hurt-feelings-under-gdpr-an-austrian-court-says-yes
- https://www.linkedin.com/pulse/landesgericht-feldkirch-kl%C3%A4ger-stehen-800-euro-f%C3%BCr-zu-tim-wybitul
- https://netzpolitik.org/2019/datenschutzgrundverordnung-18-millionen-euro-strafe-fuer-die-oesterreichische-post/
- https://www.addendum.org/datenhandel/schadenersatz/

Το Δικαίωμα Πρόσβασης
Γράφει η Μαρία – Αλεξάνδρα Παπουτσή *
Το δικαίωμα στην πρόσβαση αποτελεί – θα έλεγε κανείς – τον ακρογωνιαίο λίθο στην προστασία των προσωπικών δεδομένων και την κορωνίδα των δικαιωμάτων που αναγνωρίζονται από την ισχύουσα νομοθεσία στα υποκείμενα προσωπικών δεδομένων.
-Είναι κάποιο καινούριο δικαίωμα που θα πρέπει να γνωρίζω;
Το δικαίωμα στην πρόσβαση ενός υποκειμένου στα προσωπικά του δεδομένα κατοχυρώθηκε στην Ελλάδα ήδη από το 1997, συνεπώς δεν πρόκειται για κάποιο νέο δικαίωμα.
Ωστόσο, με την πρόσφατη αναθεώρηση του νομοθετικού πλαισίου για την προστασία προσωπικών δεδομένων, τόσο σε ευρωπαϊκό, όσο και σε εθνικό επίπεδο, η σημασία του δικαιώματος αυτού έχει επανέλθει στο προσκήνιο. Το δικαίωμα στην πρόσβαση αναγνωρίζεται σήμερα στο Άρθρο 15 του Γενικού Κανονισμού για την Προστασία Δεδομένων (γνωστότερος στα αγγλικά με το ακρωνύμιο «GDPR») και ορισμένοι περιορισμοί του εισήχθησαν με τον πρόσφατο Ν.4624/2019, ιδίως στα Άρθρα 29, 30 και 33.
-Τι είναι το δικαίωμα στην πρόσβαση;
Όταν μιλάμε για «δικαίωμα στην πρόσβαση», εννοούμε πρόσβαση στα προσωπικά σου δεδομένα. Πηγαίνοντας ένα βήμα πίσω, προσωπικά δεδομένα είναι οποιαδήποτε πληροφορία σε εξατομικεύει ή μπορεί να σε εξατομικεύσει, όπως για παράδειγμα η ηλεκτρονική σου διεύθυνση, η φωτογραφία σου, οι αγοραστικές σου συνήθειες.
Το δικαίωμα πρόσβασης σου επιτρέπει να μάθεις, μεταξύ άλλων:
Α) ποια δεδομένα σου έχει ο οποιοσδήποτε οργανισμός.
«Οποιοσδήποτε» εννοούμε από τον οδοντίατρό σου, το γυμναστήριο της γειτονιάς στο οποίο έχεις συνδρομή, την αεροπορική εταιρία ή ταξιδιωτικό γραφείο που κλείνεις εισιτήρια, μέχρι και κολοσσούς των ψηφιακών μέσων όπως η Google, το Facebook, το Twitter.
B) πώς και γιατί χρησιμοποιεί τα δεδομένα σου.
Δηλαδή, μπορείς να μάθεις για ποιους σκοπούς και με ποιες μεθόδους επεξεργάζεται ο οργανισμός, η οντότητα αυτή, τα δεδομένα σου. Να μάθεις για παράδειγμα, εάν απλά τα χρησιμοποιεί για να σε βοηθήσει να βρεις αυτό που ψάχνεις, ή και για να δημιουργήσει το προφίλ σου με βάση τις αναζητήσεις σου και να σου προβάλει σχετικές διαφημίσεις.
Γ) σε ποιους τα στέλνει.
Αντικείμενο του δικαιώματος πρόσβασης είναι και η πληροφόρησή σου για το εάν ο οργανισμός στον οποίο έδωσες αρχικά τα προσωπικά σου δεδομένα, τα έχει μοιραστεί και με άλλους οργανισμούς και εάν ναι, ποιοι είναι αυτοί και για ποιους σκοπούς.
Δ) πόσο τα διατηρεί.
Ενημερώνεσαι για το εάν ο οργανισμός που έχει τα προσωπικά σου δεδομένα σκοπεύει να τα διατηρήσει για συγκεκριμένο χρονικό διάστημα και ποιο είναι αυτό το διάστημα.
Να θυμάσαι!
Το δικαίωμα στην πρόσβαση ασκείται δωρεάν.
Ο εκάστοτε οργανισμός οφείλει να σου απαντήσει και μάλιστα μέσα σε ένα μήνα από την άσκηση του δικαιώματος.
Μπορείς να ζητήσεις απλά να μάθεις πληροφορίες για τα δεδομένα σου ή και να ζητήσεις αντίγραφο αυτών.
Τα προσωπικά σου δεδομένα είναι καταρχήν «δικά σου» και όχι του κάθε οργανισμού στον οποίο τα έχεις κοινοποιήσει. Έχεις και μπορείς να ασκήσεις εξουσία πάνω στα δικά σου προσωπικά δεδομένα.
-Γιατί είναι σημαντικό το δικαίωμα στην πρόσβαση;
Θα πρέπει όλοι να γνωρίζουμε την ύπαρξη του δικαιώματος στην πρόσβαση, αλλά και πώς μπορούμε να το ασκήσουμε, καθώς αποτελεί το πρώτο βήμα στο να αποκτήσουμε (και πάλι!) τον έλεγχο των προσωπικών μας δεδομένων. Να μάθουμε τι γνωρίζουν για εμάς οι άλλοι και τι σκοπεύουν να κάνουν με αυτές τις πληροφορίες.
Επιπλέον, το δικαίωμα στην πρόσβαση διευκολύνει την άσκηση των υπόλοιπων δικαιωμάτων που μας αναγνωρίζονται από τη νομοθεσία για την προστασία προσωπικών δεδομένων, όπως το δικαίωμα διόρθωσης, το δικαίωμα διαγραφής, το δικαίωμα φορητότητας κλπ. Προκύπτει λογικά ότι θα πρέπει να γνωρίζεις ποια δεδομένα σου έχει κάποιος οργανισμός, ώστε μετά να αποφασίσεις π.χ. αν χρειάζεται διόρθωση ορισμένων λαθών, εάν επιθυμείς να διαγραφούν κάποια δεδομένα που δεν σε αντιπροσωπεύουν πια, ή εάν θέλεις να τα μεταφέρεις σε νέο πάροχο.
-Πώς μπορώ να ασκήσω το δικαίωμα αυτό;
Κάθε οργανισμός χρησιμοποιεί διαφορετικά μέσα με τα οποία μπορείς να ασκήσεις τα δικαιώματα προστασίας των προσωπικών σου δεδομένων, συμπεριλαμβανομένου του δικαιώματος πρόσβασης. Μπορείς να ζητήσεις πρόσβαση στα δεδομένα σου, επικοινωνώντας με τον αντίστοιχο οργανισμό μέσω ταχυδρομείου (ηλεκτρονικού ή απλού), μέσω κάποιας ειδικής φόρμας ή άλλου αντίστοιχου πεδίου που θα βρεις στην ιστοσελίδα του οργανισμού.
Γενικά, καλό είναι να αναζητήσεις για λέξεις κλειδιά όπως «Πολιτική Απορρήτου»/ «Privacy Policy», «ρυθμίσεις ασφάλειας», «ρυθμίσεις απορρήτου», «άσκηση δικαιωμάτων», «Υπεύθυνος Προστασίας Δεδομένων», «πρόσβαση στις πληροφορίες μου» κλπ., ώστε να βρεις τον κατάλληλο τρόπο να επικοινωνήσεις το αίτημα της πρόσβασης στα δεδομένα σου.
Οι περισσότερες μεγάλες εταιρίες ψηφιακών μέσων προσφέρουν αρκετά ανεπτυγμένα εργαλεία που διευκολύνουν πιο συστηματικά την πρόσβαση στα δεδομένα σου.
Παρακάτω θα βρεις σχετικά παραδείγματα εταιριών που διαχειρίζονται μεγάλο όγκο των προσωπικών σου δεδομένων, καθώς και οδηγίες βήμα-βήμα για το πώς να ασκήσεις το δικαίωμα πρόσβασής σου σε αυτές.
Το παράδειγμα του Facebook
Η πλατφόρμα του Facebook σου δίνει τη δυνατότητα να ασκήσεις το δικαίωμα πρόσβασης με δύο τρόπους.
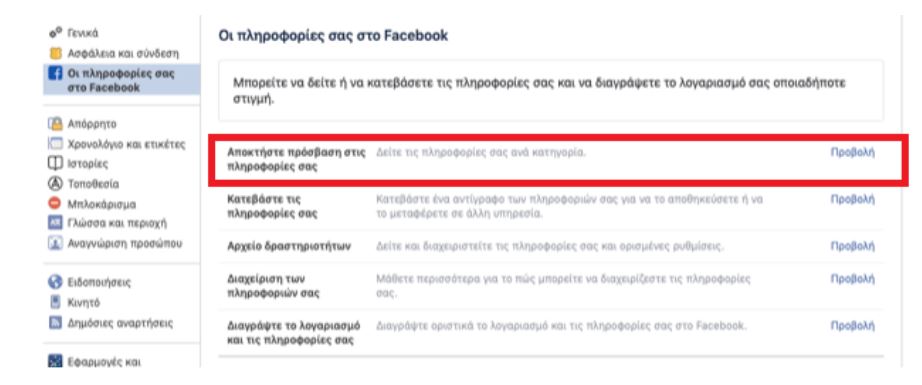
Απόκτησε πρόσβαση στις πληροφορίες σου
Ρυθμίσεις -> Οι πληροφορίες σας στο Facebook -> Αποκτήστε πρόσβαση στις πληροφορίες σας -> Προβολή
Με αυτόν τον τρόπο μπορείς να δεις τις πληροφορίες που είτε έχεις μοιραστεί ο ίδιος με το Facebook, είτε τις πληροφορίες που το Facebook έχει συλλέξει μέσα από τη δραστηριότητά σου (π.χ. ενδιαφέροντα, στοιχεία σύνδεσης, ιστορικό αναζήτησης κ.λπ.)
Το εργαλείο αυτό είναι χρήσιμο εάν θέλεις να δεις εύκολα και γρήγορα συγκεντρωμένη τη δραστηριότητά σου στην πλατφόρμα αυτή και στη συνέχεια –εάν το επιθυμείς- να ασκήσεις κάποιο άλλο από τα δικαιώματά σου. Για παράδειγμα, εάν επιθυμείς να διαγράψεις όλες τις δημοσιεύσεις σου από το 2016, μπορείς με το εργαλείο αυτό, αντί να ανατρέξεις στις δημοσιεύσεις του 2016 από το Χρονολόγιο σου, να κάνεις αναζήτηση το έτος που σε ενδιαφέρει και αφού εμφανιστούν συγκεντρωμένες όλες οι δημοσιεύσεις, να προχωρήσεις στη διαγραφή τους.
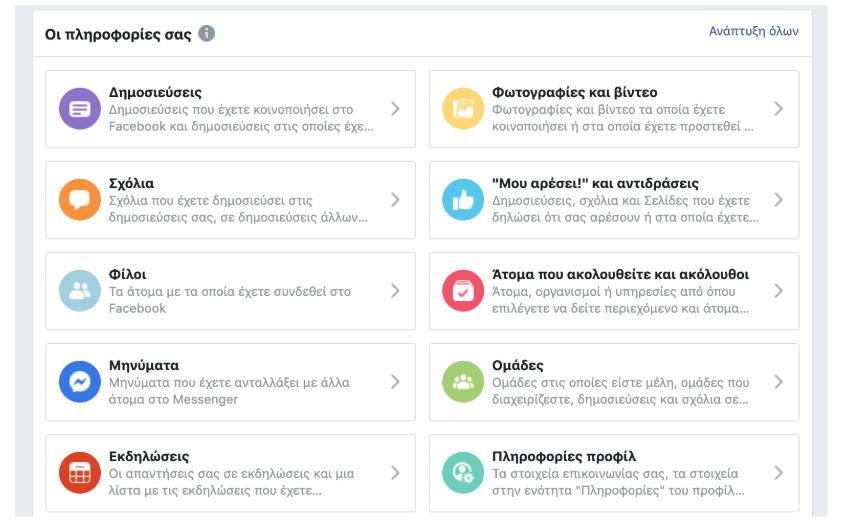
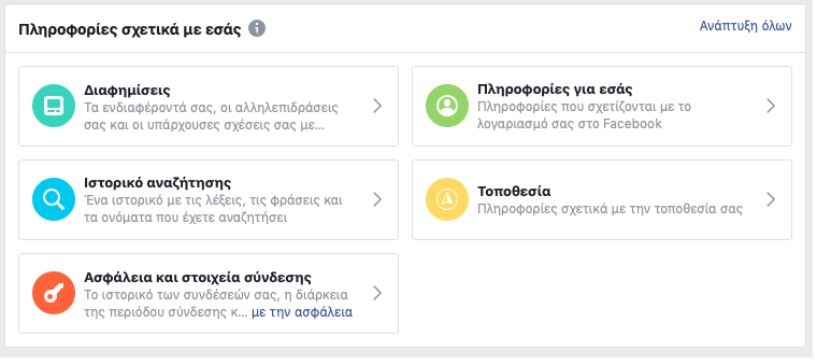
Επίσης, μην ξεχάσεις να αφιερώσεις λίγο χρόνο στο πεδίο «Πληροφορίες σχετικά με εσάς», που βρίσκεται ακριβώς από κάτω. Εκεί θα βρεις πληροφορίες σχετικά με τα ενδιαφέροντά σου και τις διαφημίσεις που σου προβάλει το Facebook, τρίτους οργανισμούς που έχουν μοιραστεί τα στοιχεία σου (email, κινητό τηλέφωνο) με τη Facebook προκειμένου να σου προβάλουν διαφημίσεις στην πλατφόρμα, καθώς και πληροφορίες σχετικά με την τοποθεσία και τις συνδέσεις σου.
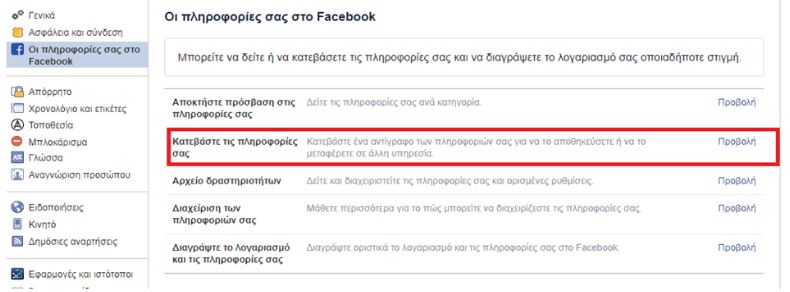
Ζήτησε αντίγραφο των προσωπικών δεδομένων σου
Επιπλέον, έχεις δικαίωμα να ζητήσεις από τη Facebook αντίγραφο των δεδομένων σου ακολουθώντας την παρακάτω διαδικασία:
Ρυθμίσεις -> Οι πληροφορίες σας στο Facebook -> Κατεβάστε τις πληροφορίες σας -> Προβολή
Στο αμέσως επόμενο στάδιο μπορείς να επιλέξεις εάν θέλεις το αρχείο να περιέχει όλα τα δεδομένα σου ή συγκεκριμένες κατηγορίες δεδομένων, τη μορφή του αρχείου μεταξύ HTML και JSON καθώς και την ποιότητα των δεδομένων. Αφού κάνεις κλικ στο πεδίο «Δημιουργία αρχείου», θα χρειαστεί να περιμένεις μέχρι να ολοκληρωθεί το αρχείο σου.
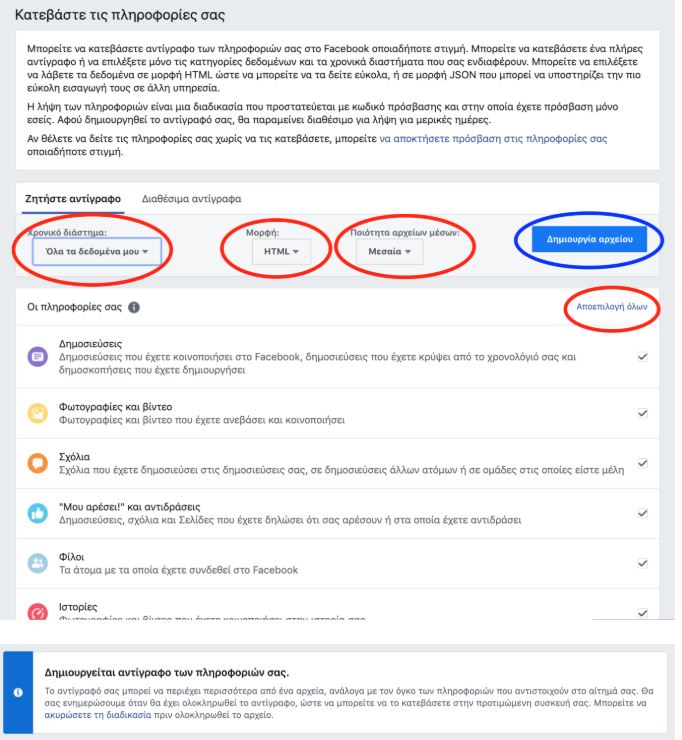
Όταν ολοκληρωθεί η δημιουργία του αρχείου, θα λάβεις σχετική ειδοποίηση στην πλατφόρμα του Facebook. Πατώντας στην ειδοποίηση αυτή, θα μεταφερθείς στη σελίδα όπου θα βρίσκεται διαθέσιμο το αρχείο σου για λήψη. Σαν τελευταίο βήμα πριν λάβεις το αρχείο σου, το Facebook θα σου ζητήσει να πληκτρολογήσεις τον κωδικό πρόσβασής σου, ώστε να επιβεβαιώσει ότι τη λήψη την ζητάς πράγματι εσύ, ο κάτοχος του λογαριασμού και ότι τα δεδομένα σου δεν θα καταλήξουν σε λάθος χέρια!
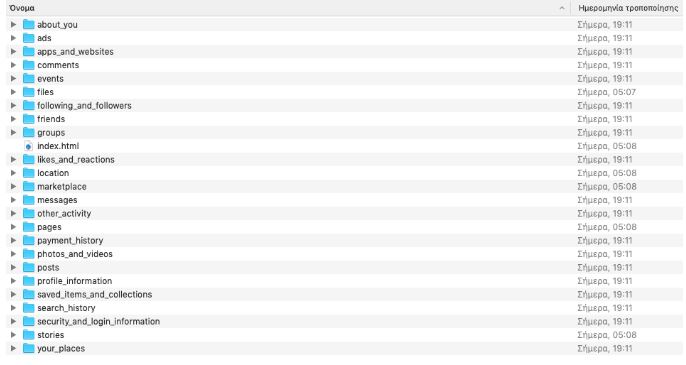
Στην περίπτωση που ζητήσεις από το Facebook όλα τα δεδομένα σου, σύμφωνα με την παραπάνω διαδικασία, θα σου σταλεί ένα αρχείο που θα περιλαμβάνει τους παρακάτω τύπους δεδομένων:
Το παράδειγμα της Google
Οι περισσότεροι από εμάς χρησιμοποιούμε υπηρεσίες της Google καθημερινά. Είτε χρησιμοποιείς τις πιο διαδεδομένες υπηρεσίες της Google όπως Google search, YouTube, Gmail, Google Maps είτε τις λιγότερο διαδεδομένες όπως Google Home, Google Pay, Google Flights, είναι αλήθεια ότι η εν λόγω εταιρεία επεξεργάζεται τεράστιο όγκο δεδομένων σου.
Πώς μπορείς λοιπόν να ασκήσεις το δικαίωμα πρόσβασης στην Google; Ομοίως όπως η Facebook, έτσι και η Google παρέχει δύο τρόπους άσκησης του δικαιώματος αυτού.
Επισκόπησε τη δραστηριότητά σου
Προκειμένου να επισκοπήσεις τη δραστηριότητά σου στα προϊόντα και υπηρεσίες της Google, ακολούθησε τα παρακάτω βήματα:
Είσοδος στον Google Λογαριασμό σας -> Δεδομένα και εξατομίκευση -> Δραστηριότητα και Χρονολόγιο
και
Είσοδος στον Google Λογαριασμό σας -> Δεδομένα και εξατομίκευση -> Τα στοιχεία που δημιουργείτε και οι ενέργειες σας
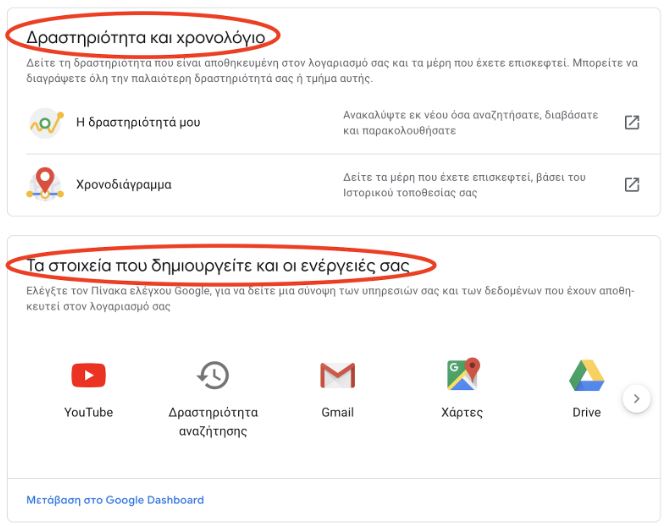
Αφότου μάθεις για τη δραστηριότητα σου, μπορείς να επιλέξεις τη διαγραφή προσωπικών δεδομένων που σχετίζονται με τη δραστηριότητά σου, καθώς και να επιλέξεις αν επιθυμείς να συνεχίσεις να αποθηκεύεται η δραστηριότητά σου στις υπηρεσίες Google που χρησιμοποιείς, εδώ:
Είσοδος στον Google Λογαριασμό σας -> Δεδομένα και εξατομίκευση -> Στοιχεία Ελέγχου Δραστηριότητας
Ζήτησε αντίγραφο των προσωπικών σου δεδομένων
Μπορείς επίσης να κατεβάσεις αντίγραφο των προσωπικών σου δεδομένων, ακολουθώντας τα παρακάτω βήματα:
Είσοδος στον Google Λογαριασμό σας -> Δεδομένα και εξατομίκευση -> Κατεβάστε, διαγράψτε ή σχεδιάστε τι θα συμβεί στα δεδομένα σας – > Κατεβάστε τα δεδομένα σας
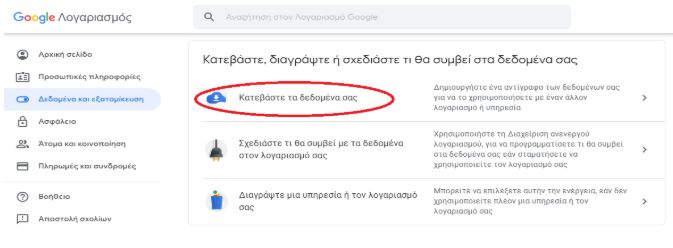
Κάνοντας κλικ στο πεδίο «Κατεβάστε τα δεδομένα σας», θα ανοίξει νέα καρτέλα όπου μπορείς να επιλέξεις αν επιθυμείς το αρχείο να περιέχει πληροφορίες για όλα τα προϊόντα της Google που χρησιμοποιείς ή μόνο για συγκεκριμένα προϊόντα, εάν επιθυμείς εξαγωγή του αρχείου μόνο μία φορά ή εξαγωγή αρχείων ανά δύο μήνες για ένα έτος, τη μέθοδο προβολής τους αρχείου (π.χ. μέσω email ή απευθείας αποθήκευση στο cloud) τον τύπο του αρχείου, καθώς και το μέγεθός του.
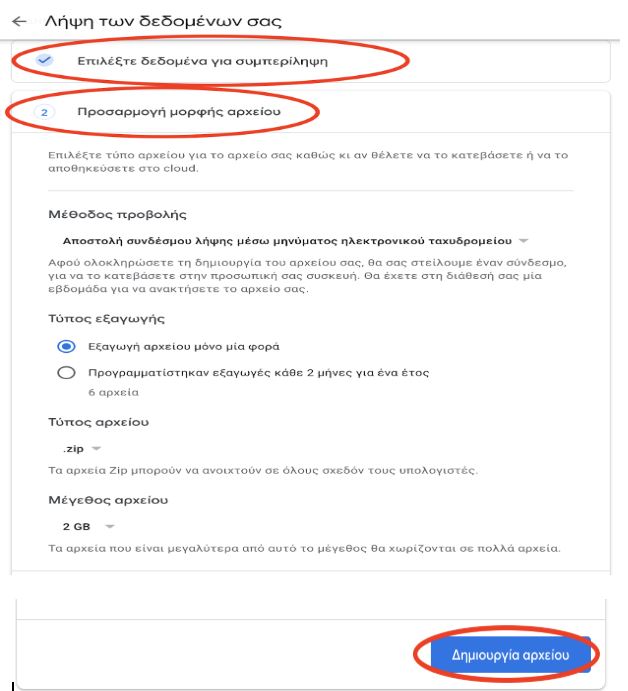
Αφότου υποβάλεις το αίτημα για λήψη αντιγράφου των δεδομένων σου, θα λάβεις ένα email όπου θα πρέπει να επιβεβαιώσεις ότι ζήτησες ο ίδιος το εν λόγω αρχείο. Στη συνέχεια, θα ξεκινήσει η διαδικασία δημιουργίας του αρχείου και αφότου ολοκληρωθεί, θα λάβεις email με την τοποθεσία του αρχείου σου, ανάλογα με τον τρόπο προβολής που επέλεξες. Για να λάβεις το αρχείο σου, θα πρέπει να πληκτρολογήσεις τον κωδικό πρόσβασης.
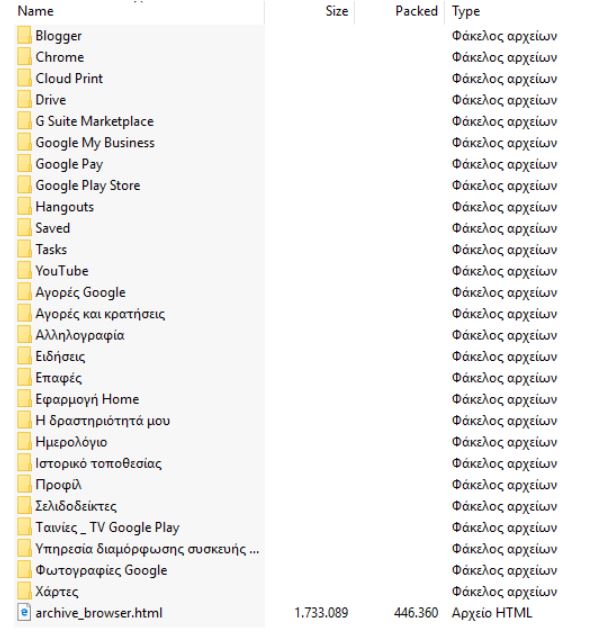
Στην περίπτωση που ζητήσεις το αρχείο σου να περιλαμβάνει όλα τα προϊόντα της Google, θα σου σταλεί το παρακάτω αρχείο.
Προσοχή! Τόσο στο Facebook όσο και στην Google, η διαδικασία δημιουργίας του αρχείου σου μπορεί να διαρκέσει από ώρες έως και μέρες, ανάλογα με τον όγκο των δεδομένων σου. Αφότου δημιουργηθεί το αρχείο, θα πρέπει να το κατεβάσεις άμεσα καθώς θα είναι διαθέσιμο για περιορισμένο χρονικό διάστημα.
-«Άσκησα το δικαίωμα πρόσβασης αλλά δεν μου απάντησαν καθόλου/εντός της προθεσμίας» , «Δεν έμεινα ικανοποιημένος από την απάντηση που έλαβα» , «Τα αρχεία δεν περιλαμβάνουν όλα τα προσωπικά μου δεδομένα». Τι μπορώ να κάνω σε αυτές τις περιπτώσεις;
Να θυμάσαι ότι σε κάθε περίπτωση έχεις το δικαίωμα να υποβάλεις καταγγελία στην Ελληνική Αρχή Προστασίας Δεδομένων Προσωπικού Χαρακτήρα, συμπληρώνοντας τη φόρμα Παραβίασης δικαιώματος (Άρθρα 15 – 22 GDPR) που θα βρεις εδώ.
*Η Μαρία-Αλεξάνδρα Παπουτσή είναι δικηγόρος με ειδίκευση στο διεθνές δίκαιο και τα ανθρώπινα δικαιώματα (LL.M.). Τα τελευταία έτη ασχολείται ενεργά με την εταιρική συμβουλευτική σε νομικά ζητήματα προστασίας προσωπικών δεδομένων και ιδιωτικότητας.

Δικτυακή ουδετερότητα: Tι είναι και πόσο μας αφορά;
Γράφει η Αντιγόνη Λογοθέτη*
Η ανάγκη για μία ελεύθερη, ενιαία ψηφιακή αγορά που προωθεί την ανοιχτή και ουδέτερη πρόσβαση στο διαδίκτυο έχει ήδη επισημανθεί από την Homo Digitalis σε προγενέστερο κείμενό της.
Έχει ακόμη επισημανθεί η ανεπάρκεια του υφιστάμενου ευρωπαϊκού ρυθμιστικού πλαισίου (Κανονισμός ΕΕ 2015/2120) σχετικά με την προώθηση της αρχής της δικτυακής ουδετερότητας ή όπως είναι ευρέως γνωστή με τον αγγλικό όρο “net neutrality”.
Τι είναι όμως η δικτυακή ουδετερότητα και τι αντίκτυπο έχει στην ψηφιακή μας καθημερινότητα;
Δικτυακή ουδετερότητα είναι η αρχή σύμφωνα με την οποία όλα τα δεδομένα που κινούνται και διαβιβάζονται στο διαδίκτυο χρήζουν ίσης μεταχείρισης, χωρίς να επιτρέπονται διακρίσεις βάσει προέλευσης, προορισμού ή τύπου των δεδομένων, χωρίς να επιτρέπεται να μπλοκάρονται ή να επιβραδύνονται συγκεκριμένα δεδομένα.
Σύμφωνα με τον Αμερικανό καθηγητή Lawrence Lessig: «σαν αιθεροβάμων ταχυδρόμος, το διαδίκτυο απλά κινεί τα δεδομένα και αφήνει την ερμηνεία τους στις εκάστοτε τελικές εφαρμογές». Σύμφωνα με τον ίδιο, ο μινιμαλισμός αυτός στον σχεδιασμό του δικτύου είναι σκόπιμος: αντανακλά τόσο μία πολιτική απόφαση σχετικά με την έλλειψη δυνατότητας ελέγχου όσο και μία τεχνολογική απόφαση σχετικά με τον βέλτιστο σχεδιασμό του δικτύου.
Πρακτικά η αρχή αυτή επιτάσσει την υποχρέωση των παρόχων υπηρεσιών διαδικτύου να αντιμετωπίζουν όλες τις διαδικτυακές επικοινωνίες ισότιμα και να μην επιβάλλουν διαφορετικές χρεώσεις, να μην επιβραδύνουν ή μπλοκάρουν επικοινωνίες επί τη βάσει διαφόρων παραγόντων όπως ενδεικτικά ο χρήστης, το περιεχόμενο της επικοινωνίας, η ιστοσελίδα, η πλατφόρμα, η εφαρμογή ή ο τύπος εξοπλισμού που χρησιμοποιείται, η διεύθυνση προέλευσης ή προορισμού και η μέθοδος επικοινωνίας.
Σε Ευρωπαϊκό επίπεδο η υιοθέτηση της αρχής της δικτυακής ουδετερότητας συμβάλλει στην προώθηση της ενιαίας ψηφιακής αγοράς, καθώς ενισχύει την καινοτομία, τον ανταγωνισμό, την ελεύθερη ροή πληροφοριών και τη βελτίωση των επιλογών του καταναλωτή.
Από πλευράς δικαίου η αρχή αυτή δημιουργεί νέα μέσα για την άσκηση θεμελιωδών δικαιωμάτων όπως η ελευθερία της έκφρασης, η ανταλλαγή πληροφοριών (χωρίς την παρεμβολή των εταιρειών τηλεπικοινωνίας), η προστασία της ιδιωτικής ζωής και των προσωπικών δεδομένων.
Χωρίς την αρχή της δικτυακής ουδετερότητας, οι πάροχοι διαδικτύου θα μπορούσαν για παράδειγμα να προσφέρουν υψηλότερες ταχύτητες σε συγκεκριμένες μηχανές αναζήτησης, καθιστώντας αυτές ελκυστικότερες για το χρήστη.
Αναπόφευκτη συνέπεια θα ήταν η νόθευση του ανταγωνισμού με τις εταιρείες κολοσσούς να επικρατούν ως οι μόνες δυνάμενες να πληρώσουν το αντίστοιχο τίμημα και τις μικρότερες εταιρείες να πασχίζουν για το μερίδιό τους στην αγορά. Τέτοιου είδους πρακτική θα έπληττε και τους καταναλωτές οι οποίοι θα έρχονταν αντιμέτωποι με λιγότερες επιλογές και χειρότερη εμπειρία στο διαδίκτυο.
Εκτός όμως από τον οικονομικό αντίκτυπο, η παραβίαση της αρχής της ουδετερότητας θα είχε ως συνέπεια ένας πάροχος υπηρεσιών διαδικτύου να μπορούσε να επιβραδύνει ή να αποκλείσει το περιεχόμενο ανταγωνιστών του ή ιστοσελίδων πολιτικά-θρησκευτικά αντίθετων.
Με τον Κανονισμό (ΕΕ) 2015/2120 τέθηκαν σε Ευρωπαϊκό επίπεδο μέτρα για την προώθηση της ανοικτής πρόσβασης στο διαδίκτυο και με τις κατευθυντήρiες γραμμές που εξέδωσε το Σώμα Ευρωπαίων Ρυθμιστών για τις Ηλεκτρονικές Επικοινωνίες. Επιχειρήθηκε η καθοδήγηση ως προς την ομοιόμορφη εφαρμογή του Κανονισμού αυτού από τους εθνικούς νομοθέτες και η ασφάλεια δικαίου (BEREC Guidelines).
Σημειωτέον ότι δεδομένου ότι πρόκειται για Κανονισμό, οι διατάξεις του έχουν άμεση εφαρμογή στα κράτη μέλη, χωρίς να χρειάζεται εθνικός εφαρμοστικός νόμος. Ωστόσο, υπάρχουν και διατάξεις οι οποίες αφήνουν τον τελικό λόγο στον εθνικό νομοθέτη.
Πώς ανταποκρίθηκε όμως η χώρα μας στις επιταγές του Κανονισμού;
Η Εθνική Επιτροπή Τηλεπικοινωνιών και Ταχυδρομείων (ΕΕΤΤ) αποτελεί τη ρυθμιστική αρχή που εποπτεύει την αγορά ηλεκτρονικών επικοινωνιών στην Ελλάδα και ως εκ τούτου είναι η αρμόδια να παρακολουθεί τη συμμόρφωση των παρόχων με τον Κανονισμό.
Η ΕΕΤΤ υποχρεούται να δημοσιεύει κάθε χρόνο σχετικές αναφορές και να τις διαβιβάζει στην Ευρωπαϊκή Επιτροπή και στο BEREC. Ως προς αυτές τις αναφορές -δύο μέχρι ώρας από την θέση σε εφαρμογή του Κανονισμού-, παρά τη σχετική υποχρέωση, η χώρα μας δεν μπήκε στον κόπο να υποβάλει την αγγλική μετάφρασή τους παρά μόνο το ελληνικό κείμενο. Συνακόλουθο αποτέλεσμα ήταν να μην μπορεί η χώρα μας να συμβάλει στο διάλογο για την βελτίωση των κανόνων.
Επιπλέον, σύμφωνα με το άρθρο 6 του Κανονισμού τα κράτη μέλη έπρεπε να θεσπίσουν αποτελεσματικές κυρώσεις για τις παραβάσεις συγκεκριμένων άρθρων τα οποία αποτελούν τον σκληρό πυρήνα για την κατοχύρωση της δικτυακής ουδετερότητας.
Η Ελλάδα εμφανίζει τον μεγαλύτερο αριθμό (μαζί με την Ουγγαρία) στις προσφορές διαφορετικής τιμολόγησης χωρίς να έχει λάβει κανένα μέτρο για να παρέμβει ενάντια σε αυτό.
Η Ελλάδα δυστυχώς συγκαταλέγεται στις χώρες που έχουν μεν θεσπίσει κυρώσεις αλλά σύμφωνα με την Αναφορά για την Κατάσταση της Δικτυακής Ουδετερότητας στην ΕΕ που δημοσίευσε φέτος ο οργανισμός epicenter.works, οι κυρώσεις αυτές κρίθηκε ότι δεν πληρούν τα κριτήρια της αποτελεσματικότητας, αναλογικότητας και αποτρεπτικότητας που τίθενται στον Κανονισμό.
Αξίζει να σημειωθεί ότι στην παραπάνω αναφορά η Homo Digitalis συνέβαλε με την εισφορά όλων των στοιχείων για την Ελλάδα και την Κύπρο.
Ως προς τα προϊόντα μηδενικού συντελεστή -ευρέως γνωστά ως zero-rated products- η ΕΕΤΤ δεν έχει ξεκινήσει την επίσημη αξιολόγησή τους ως όφειλε και σε καμία από τις δύο παραπάνω αναφορές δεν έχει απαντήσει στη σχετική ερώτηση που τίθεται στο ερωτηματολόγιο του BEREC.
Μάλιστα, σύμφωνα με την παραπάνω αναφορά η Ελλάδα εμφανίζει τον μεγαλύτερο αριθμό (μαζί με την Ουγγαρία) στις προσφορές διαφορετικής τιμολόγησης (δηλαδή διαφορετική χρέωση του συνδρομητή από τον πάροχο για την αποστολή/λήψη δεδομένων ορισμένου περιεχομένου από τη χρέωση γενικών δεδομένων) χωρίς να έχει λάβει κανένα μέτρο για να παρέμβει ενάντια σε αυτό.
Σύμφωνα με την Ετήσια Έκθεση Ανοικτού Διαδικτύου 2018-2019 της ΕΕΤΤ στην Ελλάδα το 2018 παρέχονταν 25 υπηρεσίες διαφορετικής τιμολόγησης περιεχομένου και εφαρμογών. Η αντιμετώπιση των προϊόντων αυτών έχει σημασία διότι -εκτός των άλλων- η ύπαρξή τους συνδέεται με αγορές των οποίων οι τιμολογιακές πρακτικές είναι δυσμενείς προς τα συμφέροντα του καταναλωτή.
Επιλογικά, παρότι όχι και τόσο γνωστή στο ευρύ κοινό, η αρχή της δικτυακής ουδετερότητας παίζει σπουδαίο ρόλο στην ψηφιακή καθημερινότητά μας, τόσο ως καταναλωτών όσο και ως υποκειμένων δικαιωμάτων (data subjects).
Από την θέση σε εφαρμογή του σχετικού Κανονισμού και ανεξάρτητα από τις κριτικές που έχουν διατυπωθεί για τον Κανονισμό καθαυτό, σύμφωνα με την παραπάνω συγκριτική μελέτη του epicenter.works η χώρα μας για άλλη μια φορά αποδείχθηκε κατώτερη των περιστάσεων ως προς αφενός μεν την λήψη μέτρων για την εφαρμογή ορισμένων διατάξεων του Κανονισμού αφετέρου δε την αποτελεσματικότητα των όποιων ληφθέντων μέτρων καταλαμβάνοντας τις χαμηλότερες θέσεις στους συγκριτικούς πίνακες με τις σχετικές επιδόσεις όλων των κρατών μελών.
*Η Αντιγόνη Λογοθέτη είναι δικηγόρος, πρόσφατη απόφοιτος του Μεταπτυχιακού Προγράμματος LL.M. «Δίκαιο και Τεχνολογία», στο Tilburg University της Ολλανδίας. Είναι ασκούμενη στη noyb.eu, Ευρωπαϊκό Κέντρο για τα Ψηφιακά Δικαιώματα με έδρα τη Βιέννη.

Είναι η οικογένεια ο νέος “influencer” ;
Γράφει η Αναστασία Καραγιάννη
Η αλήθεια είναι ότι, λίγο πολύ, στις μέρες μας είμαστε ενημερωμένοι για την άμεση συλλογή και επεξεργασία των δεδομένων των παιδιών. Ωστόσο, είναι εξίσου αλήθεια ότι γνωρίζουμε πολύ λίγα πράγματα για άλλες μεθόδους έμμεσης συλλογής και επεξεργασίας των δεδομένων των παιδιών, κυρίως στις πλατφόρμες κοινωνικής δικτύωσης.
Τα προσωπικά δεδομένα των ανηλίκων βρίσκονται ακόμα και στις φωτογραφίες που μοιράζονται στο Facebook οι γονείς και οι φίλοι της οικογένειας, σε όλα τα βίντεο από την καθημερινή ζωή των παιδιών ή τα vlogs της οικογένειας στο YouTube, στα hashtags στο Twitter και στις στιγμιαίες φωτογραφίες στο Snapchat, και υποβάλλονται σε επεξεργασία σύμφωνα με το προφίλ των ενηλίκων
Δεδομένου ότι πολλά παιδιά ηλικίας 13 έως 16 ετών χρησιμοποιούν αυτές τις πλατφόρμες, τα δεδομένα τους είναι αυτονόητο ότι συλλέγονται και αποθηκεύονται. Όμως, τα δεδομένα αυτά βρίσκονται και στις φωτογραφίες που μοιράζονται στο Facebook οι γονείς και οι φίλοι της οικογένειας, σε όλα τα βίντεο από την καθημερινή ζωή των παιδιών ή τα vlogs της οικογένειας στο YouTube, στα hashtags στο Twitter και στις στιγμιαίες φωτογραφίες στο Snapchat, και υποβάλλονται σε επεξεργασία σύμφωνα με το προφίλ των ενηλίκων. Με αυτό τον τρόπο, τα δεδομένα των παιδιών ενσωματώνονται στα δεδομένα των ενηλίκων-γονέων στα πλαίσια των ‘οικογενειακών δεδομένων’.
Τον Νοέμβριο του 2018, το Facebook κατέθεσε δίπλωμα ευρεσιτεχνίας για τις προβλέψεις δημογραφικών στοιχείων, οι οποίες βασίστηκαν σε δεδομένα εικόνας. Αυτή η ‘πατέντα’ βασίζεται στην αναγνώριση προσώπου και επιτρέπει στο Facebook να κατηγοριοποιεί φωτογραφίες που δημοσιεύονται από το χρήστη και φωτογραφίες που έχουν αναρτηθεί από άλλους χρήστες οι οποίοι είναι ‘κοινωνικά συνδεδεμένοι’ μαζί του, καθώς και με άλλα είδη κειμένου, όπως οι λεζάντες που περιέχουν περισσότερες πληροφορίες σχετικά με το χρήστη και την οικογένειά του.
Παρόλο που οι πλατφόρμες των μέσων κοινωνικής δικτύωσης προσπαθούν να συμμορφωθούν με τον GDPR στις Πολιτικές Απορρήτου, στοχεύουν στα παιδιά ή συλλέγουν πληροφορίες από τα προφίλ της οικογένειας μέσω της εξαγωγής δεδομένων.
Δεν είναι τυχαίο, άλλωστε, που υπάρχουν επίσης οι περιπτώσεις των ‘moms influencers’ που μοιράζονται πληροφορίες όχι μόνο για τη δική τους ζωή, αλλά και των παιδιών τους, έχοντας ως σκοπό την προώθηση προϊόντων με διαφημίσεις, άρα το κέρδος, ή καθιστώντας τα παιδιά τους influencers στα κοινωνικά μέσα.
Ωστόσο, το ερώτημα είναι το εξής:
Τα δεδομένα στην εικόνα ανήκουν στα παιδιά και τι συμβαίνει όταν τα δικαιώματα που απορρέουν ασκούνται από τρίτους, όπως οι γονείς και οι έχοντες την γονική επιμέλεια; Αυτά τα δεδομένα σε ποιον ανήκουν; Και η ‘ιδιοκτησία των δεδομένων’ μπορεί να θεωρηθεί δικαίωμα ιδιοκτησίας;
Ιστορικά, τα παιδιά είναι υπό την ευθύνη των γονέων τους. Αυτή η θεμελιώδης αρχή παραμένει, αν και η ευαισθησία μας και η γλώσσα που χρησιμοποιούμε για να περιγράψουμε τη γονική σχέση έχει αλλάξει. Ο Ali Watson υποστηρίζει ότι παρά τις αλλαγές στην τεχνολογία, την κοινωνία και τον τρόπο με τον οποίο αντιλαμβανόμαστε την ανάπτυξη των παιδιών «η φύση των ίδιων των παιδιών έχει αλλάξει πολύ λίγο». Παρόλο που υπάρχει εκτενής βιβλιογραφία σχετικά με τις πρακτικές κληρονομιάς, οι πηγές που απευθύνονται άμεσα στα δικαιώματα ιδιοκτησίας των παιδιών είναι ελάχιστες.
Η απουσία νομικής ρύθμισης σχετικά με τα δικαιώματα ιδιοκτησίας των παιδιών οφείλεται στο γεγονός ότι τα παιδιά δεν έχουν πλήρη νομική προσωπικότητα, λόγω ηλικίας, ανωριμότητας και ευαλωτότητας, κάτι που τους απαγορεύει να ελέγχουν τα δικά τους συμφέροντα.
Ωστόσο, στο άρθρο 21 του Ν. 4624/2019 (άρθρο 6 και 8 του GDPR) για την προστασία των προσωπικών δεδομένων προβλέπεται το 15ο έτος ως όριο ηλικίας, όπου το παιδί μπορεί να δώσει την συναίνεσή του για την επεξεργασία των προσωπικών του δεδομένων κατά την προσφορά υπηρεσιών της κοινωνίας των πληροφοριών. Μ’ αυτόν τον τρόπο, ο νομοθέτης αναγνωρίζει ότι ένα παιδί-έφηβος/η στο 15ο έτος της ηλικίας του διαθέτει την στοιχειώδη ωριμότητα, ώστε να αντιληφθεί πιθανούς κινδύνους, να αντισταθμίσει τα οφέλη και να πάρει συνειδητά μία απόφαση.
Η Σύμβαση του ΟΗΕ για τα Δικαιώματα του Παιδιού εγγυάται στα παιδιά το δικαίωμα σε όνομα, εκπαίδευση, πολιτισμό, θρησκευτική ελευθερία, ενώ ενθαρρύνει τη δημοσίευση παιδικών βιβλίων. Ωστόσο, δεν αναφέρεται ρητά στα δικαιώματα ιδιοκτησίας των παιδιών. Πράγματι, αναφέρεται μόνο στην ιδιοκτησία, στο μέτρο που τα παιδιά δεν πρέπει να υφίστανται διακρίσεις εξαιτίας της ιδιοκτησίας τους ή της έλλειψης κυριότητας ιδιοκτησίας. Η υπογραφή της Σύμβασης του ΟΗΕ για τα Δικαιώματα του Παιδιού αποτέλεσε κρίσιμη στιγμή για την αναγνώριση των δικαιωμάτων του παιδιού σε ένα νομικό κείμενο και για την καθιέρωση ενός σημαντικού κριτηρίου στο άρθρο 3 ότι «το πρωταρχικό μέλημα πρέπει να είναι το βέλτιστο συμφέρον του παιδιού».
Η πρώτη σημαντική διεθνής σύμβαση για την αναγνώριση των δικαιωμάτων ιδιοκτησίας του παιδιού είναι η Σύμβαση της Χάγης του 1996 για τη γονική μέριμνα και την προστασία των παιδιών. Ειδικότερα, στο άρθρο 1, η Σύμβαση καλεί τα κράτη να «προστατεύσουν το πρόσωπο ή την περιουσία του παιδιού». Η συχνή χρήση της φράσης «πρόσωπο ή ιδιοκτησία του παιδιού» δηλώνει την αναγνώριση των σημερινών και μελλοντικών δικαιωμάτων ιδιοκτησίας του παιδιού.
Ωστόσο, πριν εξεταστεί ο ρόλος των γονέων σε αυτή την περίπτωση, θα πρέπει να διευκρινίσουμε την έννοια της ιδιοκτησίας των δεδομένων και της σχέσης της με τα δικαιώματα ιδιοκτησίας. Σύμφωνα με την Valentina Pavel, η κυριότητα είναι το αποκλειστικό δικαίωμα χρήσης, κατοχής και διάθεσης της περιουσίας. Πολλοί άνθρωποι αναπτύσσουν συναισθηματικά επιχειρήματα σχετικά με την ιδιοκτησία των δεδομένων, οπότε ένας νομικός ορισμός της ιδιοκτησίας είναι αναγκαίος, όπως και η σημασία που δίνεται από τις επιχειρήσεις.
Σύμφωνα με την Sylvie Delacroix, η διαρροή των δεδομένων μας καθιστά ευάλωτους. Η συνεχής, διαισθητική σχέση ιδιοκτησίας με τον έλεγχο φαίνεται να βασίζεται σε ένα πολύ συγκεκριμένο ιδεώδες ιδιοκτησίας, το οποίο αντικατοπτρίζεται στο ρητό, «το σπίτι κάποιου είναι το κάστρο του».
Η Sylvie Delacroix υποστηρίζει ότι η προσπάθεια του GDPR να περιορίσει την ελευθερία των συμβάσεων δεν αρκεί από μόνη της, ώστε να αντιστρέψει την ασυμμετρία εξουσίας μεταξύ αυτών που ελέγχουν τα δεδομένα και των υποκειμένων των δεδομένων. Η λύση σύμφωνα με την Sylvie Delacroix είναι η εμπιστοσύνη των δεδομένων, ένας μηχανισμός με τον οποίο τα υποκείμενα δεδομένων επιλέγουν να συγκεντρώσουν τα δεδομένα τους εντός του νομικού πλαισίου της εμπιστευτικότητας.
Τα δικαιώματα των γονέων στην ελευθερία της έκφρασης και της γονικής επιμέλειας μπορεί να έρθουν σε σύγκρουση, όπως και με το δικαίωμα στην ιδιωτικότητα των παιδιών
Όταν οι γονείς μοιράζονται πληροφορίες σχετικά με τα παιδιά τους στο διαδίκτυο, τις περισσότερες φορές το κάνουν χωρίς τη συγκατάθεση των παιδιών τους. Οι γονείς παίζουν τόσο τον ρόλο του ‘φύλακα’ και ‘προστάτη’ των προσωπικών δεδομένων των παιδιών τους όσο και του ‘αφηγητή’ των προσωπικών ιστοριών τους.
Αυτός ο διπλός ρόλος των γονέων συμβάλλει σημαντικά στην διαμόρφωση της ηλεκτρονικής ταυτότητας των παιδιών, ενώ τους παρέχει ελάχιστη προστασία. Προκαλείται μια σύγκρουση συμφερόντων, καθώς τα παιδιά μπορεί κάποια μέρα να αντιδράσουν στις δημοσιεύσεις που έκαναν πριν χρόνια οι γονείς τους και να συνειδητοποιήσουν ότι δεν μπορούν να ελέγξουν πλέον το ψηφιακό τους αποτύπωμα.
Πράγματι, τα πρωτοβάθμια Δικαστήρια στην Αυστρία κλήθηκαν να αντιμετωπίσουν την υπόθεση μιας δεκαοχτάχρονης κοπέλας, η οποία μήνυσε τους γονείς της, επειδή μοιράστηκαν 500 φωτογραφίες της με τους 700 διαδικτυακούς τους φίλους στο Facebook. Η κοπέλα συγκεκριμένα αναφέρει πως οι γονείς την δεν έβαλαν όρια και δεν σκέφτηκαν ότι μπορεί να αισθάνεται η ίδια αργότερα ντροπή για αυτές τις φωτογραφίες, αφού σε κάποιες απεικονίζεται ακόμα και γυμνή στην μπανιέρα. Για αυτό το λόγο, ζήτησε από το Δικαστήριο να αποσυρθούν αυτές οι φωτογραφίες και η ίδια να αποζημιωθεί οικονομικά.
Όταν οι γονείς δημοσιεύουν φωτογραφίες των παιδιών τους από την καθημερινότητά τους, μπορούν να εγγυηθούν ότι τα παιδιά τους δεν θα δυσαρεστηθούν από αυτές τις φωτογραφίες ή δε θα ζητήσουν να αφαιρεθούν αυτές οι φωτογραφίες;
Μόλις ‘ανέβει’ μία φωτογραφία στο διαδίκτυο, δεν μπορεί να εξαφανιστεί εύκολα. Το γεγονός ότι τα περισσότερα από τα παιδιά δεν μπορούν να εκφράσουν την γνώμη τους σε μικρή ηλικία, γιατί δεν αντιλαμβάνονται τι συμβαίνει, δεν σημαίνει ότι οι γονείς δεν πρέπει να ρωτήσουν την γνώμη τους, να τους εξηγήσουν για ποιο λόγο θέλουν αν μοιραστούν μία φωτογραφία τους και πως λειτουργεί ο ψηφιακός χώρος.
Μια έρευνα ανέφερε ότι οι περισσότεροι γονείς κατά 89% δραστηριοποιούνται καθημερινά στο διαδίκτυο, ενώ μόλις το 11% δήλωσε ότι ανησυχούν σχετικά με την προστασία της ιδιωτικής τους ζωής και προσπαθούν να περιορίσουν τη χρήση του διαδικτύου.
Οι ‘Insta-Moms’, οι μητέρες που δημοσιεύουν συχνά τις φωτογραφίες των παιδιών τους στο Instagram, και οι ‘Moms-influencers’ συχνά επικρίνονται επειδή χρησιμοποιούν τις εικόνες των παιδιών τους με επικερδή τρόπο. Η έρευνα αυτή ανέφερε επίσης ότι μόνο το 14% των γονέων με παιδιά ηλικίας 9-12 ετών, και το 48% των γονέων με παιδιά ηλικίας 13-17 ετών, έκριναν ότι το παιδί τους ήταν αρκετά ώριμο, ώστε να έχει αυτοτελές δικαίωμα στην ιδιωτικότητα στον ψηφιακό χώρο.
Το ‘Sharenting’ (από το parenting που σημαίνει γονική μέριμνα και το share που σημαίνει μοιράζομαι) είναι η συνεχής συμπεριφορά των γονέων να μοιράζονται τα δεδομένα των παιδιών τους σαν να είναι δικά τους δεδομένα, στα πλαίσια της ιδιοκτησίας και της γονικής επιμέλειας. Η χρησιμοποίηση των φωτογραφιών των παιδιών με σκοπό το κέρδος, τις διαφημίσεις και τις χορηγίες είναι εντελώς διαφορετικό από την απλή λήψη φωτογραφιών.
Προωθώντας διάφορα προϊόντα, από παιχνίδια μέχρι ρούχα υψηλής ραπτικής, αυτά τα παιδιά μπορούν να κερδίσουν πολλά χρήματα για μία φωτογραφία. Χωρίς να μπορούν να υπογράψουν κάποια σύμβαση, τα κέρδη απλώς καταλήγουν στα χέρια των γονέων, δημιουργώντας δεοντολογικά και πρακτικά προβλήματα. Κάποιοι γονείς μπορεί να δημιουργούν λογαριασμούς ταμιευτηρίου ή να προσθέτουν τα κέρδη σε ένα κοινό ταμείο με τα παιδιά τους, ώστε να τα χρησιμοποιήσουν μόλις ενηλικιωθεί, αλλά τις περισσότερες φορές οι γονείς χρησιμοποιούν αυτά τα χρήματα πολύ πριν από την ενηλικίωση των παιδιών.
Ο ρόλος των γονέων είναι να εξοικειώσουν τα παιδιά τους με το νόημα και την ουσία της ιδιωτικής ζωής στο διαδίκτυο, να τους εξηγήσουν γιατί χρειάζονται τα όρια της ιδιωτικής ζωής στο ψηφιακό περιβάλλον αλλά και πώς μπορούν να επωφεληθούν από τον σύγχρονο ψηφιακό κόσμο
Συνοψίζοντας, οι εταιρείες και οι γονείς πρέπει να συνεργάζονται και να ακολουθούν μία κοινή πολιτική και πρακτική που τους επιτρέπει να μην παραβιάζουν τα δικαιώματα ιδιωτικότητας και προστασίας προσωπικών δεδομένων των παιδιών. Οι γονείς πρέπει να είναι πιο επιλεκτικοί με τις εταιρείες που επιλέγουν να συνεργαστούν, καθώς και να διασφαλίζουν διαρκώς ότι έχουν λάβει την ενημερωμένη συγκατάθεση του παιδιού πριν από την πραγματοποίηση οποιωνδήποτε δημοσιεύσεων.
Δεδομένου ότι το ψηφιακό περιβάλλον είναι πραγματικά ευρύ και ρευστό, ο ρόλος των γονέων είναι να εξοικειώσουν τα παιδιά τους με το νόημα και την ουσία της ιδιωτικής ζωής στο διαδίκτυο, να τους εξηγήσουν γιατί χρειάζονται τα όρια της ιδιωτικής ζωής στο ψηφιακό περιβάλλον, και πώς μπορούν να επωφεληθούν από τον ψηφιακό κόσμο, όχι μόνο με λόγια, αλλά και με το να αποτελούν το παράδειγμα με τις πράξεις τους.

Τι είναι το SSL και πως λειτουργεί;
Γράφει ο Βύρων Καβαλίνης*
Το SSL πλέον θεωρείται απαραίτητο σε ένα website γιατί προστατεύει τόσο το ίδιο, όσο και τον επισκέπτη. Επίσης, βοηθάει στην επισκεψιμότητα του website, καθώς μεγάλες μηχανές αναζήτησης έχουν ανακοινώσει ότι websites χωρίς SSL δεν θα εμφανίζονται πρώτα στα αποτελέσματα των αναζητήσεων.
Σκοπός του άρθρου αυτού είναι να παρουσιάσει τεχνικά πώς λειτουργεί ένα SSL. Μπορείτε να διαβάσετε περισσότερες πληροφορίες για τα πιστοποιητικά στο άρθρο του Γιάννη Κωνσταντινίδη.
Το SSL είναι ένα παγκόσμιο πρωτόκολλο το οποίο αναπτύχθηκε ώστε να παρέχει ασφάλεια στην μετάδοση των δεδομένων στο διαδίκτυο. Το SSL βεβαιώνει ότι τα δεδομένα που θα ανταλλαχθούν μεταξύ δύο συστημάτων (client, server) είναι αδύνατον να διαβαστούν από κάποιον τρίτο μη εξουσιοδοτημένο χρήστη.
Το SSL χρησιμοποιεί μεθόδους κρυπτογράφησης των δεδομένων που ανταλλάσσονται δημιουργώντας μια ασφαλή σύνδεση μεταξύ των δύο συστημάτων. Η λειτουργία του γίνεται μετά το TCP/IP πρωτόκολλο και πριν της εφαρμογές υψηλού επιπέδου όπως για παράδειγμα το HTTP/FPT/IMAP.
Ουσιαστικά αυτό που κάνει το πιστοποιητικό είναι να κρυπτογραφεί τις πληροφορίες που λαμβάνει από τις εφαρμογές υψηλού επιπέδου και στη συνέχεια να τις μεταδίδει.
Η Netscape το 1996 κυκλοφόρησε την έκδοση 3.0 του SSL το οποίο αποτέλεσε και τη βάση για την ανάπτυξη του πρωτοκόλλου TLS το οποίο πλέον έχει αντικαταστήσει το SSL ενώ συνεχίζουμε και το αναφέρουμε σαν απλό SSL.
Πώς λειτουργεί το πιστοποιητικό
Όπως αναφέραμε και παραπάνω το πιστοποιητικό δημιουργεί μια ασφαλή σύνδεση μεταξύ δύο συστημάτων και κρυπτογραφεί τα δεδομένα ώστε να μην μπορούν να “διαβαστούν” από κάποιο τρίτο μη εξουσιοδοτημένο χρήστη. Για να γίνει η σύνδεση αυτή χρησιμοποιούνται η συμμετρική και ασύμμετρη κρυπτογράφηση.
Τις δύο αυτές έννοιες έχει ήδη αναλύσει εξαιρετικά στο άρθρο του ο Αναστάσιος Αραμπατζής. Στο σημείο αυτό, θα τις εξηγήσουμε συνοπτικά με σκοπό να επικεντρωθούμε στη συνέχεια στη χρήση τους για τη λειτουργία του SSL.
Συμμετρική Κρυπτογράφηση
Στη συμμετρική κρυπτογράφηση τόσο ο αποστολέας όσο και ο παραλήπτης χρησιμοποιούν ένα κοινό κλειδί για την κρυπτογράφηση και αποκρυπτογράφηση της πληροφορίας. Η κρυπτογράφηση αυτή είναι πιο γρήγορη αλλά δεν είναι τόσο ασφαλής όσο η ασύμμετρη καθώς αν κάποιος τρίτος έχει το κλειδί πρόσβαση στο κλειδί της κρυπτογράφησης αυτόματα μπορεί να αποκρυπτογραφήσει και τα δεδομένα που ανταλλάσσονται.
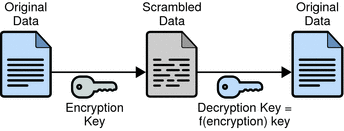
Στην περίπτωση των υπολογιστών το κλειδί είναι ένας αριθμητικός κωδικός, το μέγεθος του οποίου ορίζεται από το πόσα bits τον αποτελούν.Ο πρώτος σημαντικός αλγόριθμος για κρυπτογράφηση δεδομένων μέσω υπολογιστή ήταν ο Data Encryption Stantard (DES) που αναπτύχθηκε από την IBM στις ΗΠΑ και εγκρίθηκε για χρήση το 1970. Ο DES χρησιμοποιεί κλειδί μήκους 56-bit, που διαθέτει πάνω από 72 τετράκις εκατομμύρια πιθανούς συνδυασμούς (72.057.594.037.927.936, για την ακρίβεια).
Πλέον, ο DES έχει αντικατασταθεί από τον αλγόριθμο Advanced Encryption Standard (AES), που χρησιμοποιεί κλειδιά 128, 192 ή 256-bit. Με την αύξηση των bit και οι πιθανοί συνδυασμοί έχουν αυξηθεί υπερβολικά πολύ. Ένα κλειδί 128-bit μπορεί να έχει πάνω από 300.000.000.000.000.000.000.000.000.000.000.000 πιθανούς συνδυασμούς. Ο μεγαλύτερος υπερυπολογιστής αυτή τη στιγμή στον κόσμο θα μπορούσε θεωρητικά να σπάσει τον DES σε 2 δευτερόλεπτα ενώ θα χρειαζόταν περίπου 250 δισεκατομμύρια χρόνια για να ελέγξει όλους τους συνδυασμούς του AES-128.
Άλλοι γνωστοί αλγόριθμοι είναι οι RC4, 3DES, IDEA, CAST5, Twofish, Serpent, Blowfish.
Ασύμμετρη κρυπτογράφηση
Ένα πρόβλημα της συμμετρικής κρυπτογράφησης είναι ότι αν κάποιος θέλει να στείλει κάτι κρυπτογραφημένο θα χρειαστεί με κάποιο τρόπο να μας στείλει και ένα αντίγραφο του κλειδιού του για να μπορέσουμε να το αποκρυπτογραφήσουμε.
Είναι κατανοητό ότι η μετάδοση του κλειδιού στο διαδίκτυο, που είναι ένα δημόσιο δίκτυο, θα έδινε την ευκαιρία σε οποιοδήποτε να έχει πρόσβαση σε αυτό και κατά συνέχεια να μπορεί να αποκρυπτογραφήσει και την πληροφορία που έχει σταλεί.
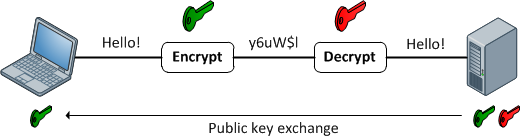
Αυτό το πρόβλημα λύνει η ασύμμετρη κρυπτογράφηση. Στην ασύμμετρη κρυπτογράφηση χρησιμοποιείται ένα public key το οποίο μπορεί μόνο να κρυπτογραφήσει την επικοινωνία η οποία μπορεί να αποκρυπτογραφηθεί μόνο με το αντίστοιχο private key το οποίο είναι αποθηκευμένο και κρυφό. Με αυτό το τρόπο μόνο ο σωστός χρήστης μπορεί να αποκρυπτογραφήσει την πληροφορία που έχει λάβει. Η συγκεκριμένη κρυπτογράφηση είναι πιο ασφαλής αλλά απαιτεί μεγαλύτερη υπολογιστική ισχύ.
Συνοπτικά χρησιμοποιούνται δύο κλειδιά:
– Το Public key, που είναι δημόσιο και μπορεί να χρησιμοποιηθεί από οποιδήποτε για την κρυπτογράφηση δεδομένων.
– Το Private key, το οποίο είναι μυστικό και συνδέεται μαθηματικά με το Public key και είναι απαραίτητο για την αποκρυπτογράφηση.
Η διαδικασία ασφαλούς σύνδεσης
Όπως αναφέραμε παραπάνω, το TLS είναι το πρωτόκολλο κρυπτογράφησης του Internet και είναι ο διάδοχος του SSL (αλλά αναφέρεται ακόμα και σήμερα σαν SSL) και υπαγορεύει τα βήματα που πρέπει να ακολουθηθούν για να πραγματοποιηθεί μια ασφαλής σύνδεση.
Τα βήματα αυτά συμπεριλαμβάνουν, μεταξύ άλλων:
– ποια στοιχεία χρειάζεται να ανταλλάξουν ο υπολογιστής μας και ο server πριν δημιουργηθεί η ασφαλής σύνδεση
– ποιος αλγόριθμος Public/Asymmetric key θα χρησιμοποιηθεί και για την κρυπτογράφηση ποιων δεδομένων
– ποιος αλγόριθμος θα χρησιμοποιηθεί για το Symmetric key
– πόσο διάστημα θα διαρκέσει η σύνδεση (session) πριν χρειαστεί να ανανεωθεί
Για να δημιουργηθεί μια κρυπτογραφημένη επικοινωνία γίνεται χρήση τόσο της ασύμμετρης κρυπτογράφησης όσο και της συμμετρικής. Αρχικά και αφού έχει γίνει η αρχική επικοινωνία του browser με τον server και έγινε η επιβεβαίωση της ύπαρξης ενεργού πιστοποιητικού ξεκινάει η ασύμμετρη κρυπτογράφηση ενώ ακολουθεί η συμμετρική.
1. Ο browser στέλνει τα στοιχεία του στο server: ποιες εκδόσεις SSL και TLS υποστηρίζει, ποιους αλγόριθμους για την κρυπτογράφηση δεδομένων, στοιχεία που αφορούν το session (πχ ημερομηνία και ώρα έναρξης) και γενικά όσα στοιχεία χρειάζεται για να γίνει η σύνδεση.
2. Ο web server της σελίδας στέλνει τα αντίστοιχα στοιχεία του όσον αφορά το SSL/TLS, τους αλγόριθμους, το session κλπ. Επίσης στέλνει το digital certificate του.
3. Ο browser ελέγχει τρία πράγματα:
α) Αν το digital certificate προέρχεται από μια πιστοποιημένη Certificate Authority,
β) αν ισχύει ακόμα και
γ) αν συνδέεται με το site που έχουμε μπει.
4. Εφόσον είναι όλα καλά ο server στέλνει ένα αντίγραφο του ασύμμετρου δημόσιου κλειδιού του (public key). Με το κλειδί αυτό μπορεί να κρυπτογραφηθεί μόνο η πληροφορία ενώ για την αποκρυπτογράφηση της χρειάζεται το private key του server που είναι κρυμμένο και ασφαλές.
5. Με το public key του server, ο client δημιουργεί ένα συμμετρικό session key το οποίο κρυπτογραφεί με αυτό και το στέλνει σε αυτόν.
6. Ο server στη συνέχεια αποκρυπτογραφεί τα δεδομένα που του έχει στείλει ο client με το private key του κι έτσι έχει πλέον το συμμετρικό session key του client.
7. Πλέον ο client και o server κρυπτογραφούν και αποκρυπτογραφούν τα δεδομένα που στέλνουν και λαμβάνουν με τη χρήση του session key που έχουν και οι δύο πλέον. Αυτό επιτρέπει ένα ασφαλές κανάλι επειδή μόνο ο client και ο server γνωρίζουν το συμμετρικό session key και μόνο γι αυτή την περίοδο σύνδεσης. Αν ο περιηγητής χρειαστεί να συνδεθεί με τον server κάποια άλλη στιγμή τότε θα δημιουργηθεί νέο session key με τον παραπάνω τρόπο.
Το πιστοποιητικό SSL θεωρείται πλέον αναπόσπαστο κομμάτι μιας σελίδας. Η Google είχε ανακοινώσει ότι όσα sites δεν διαθέτουν ενεργό πιστοποιητικό δεν θα εμφανίζονται με προτεραιότητα στις αναζητήσεις των χρηστών, μια αλλαγή ιδιαίτερα σημαντική.
Από την πλευρά μας θα προτείναμε να ελέγχετε τις σελίδες που επισκέπτεστε ώστε να βεβαιωθείτε ότι διαθέτουν ενεργό πιστοποιητικό, ειδικά αν πρόκειται για online καταστήματα.
Μπορείτε να δείτε απλά βήματα ώστε να επιβεβαιώσετε ότι το πιστοποιητικό σας λειτουργεί κανονικά εδώ.
*Ο Βύρωνας είναι απόφοιτος του τμήματος Εφαρμοσμένης Πληροφορικής και Πολυμέσων του ΤΕΙ Ηρακλείου. Εργάζεται σε εταιρεία, η οποία δραστηριοποιείται στο χώρο του Web hosting και των domain names. Ασχολείται με την ανάπτυξη ιστοσελίδων και την ασφάλεια. Στο παρελθόν, έχει ασχοληθεί με τα πιστοποιητικά SSL.

Πρόστιμο 400.000€ της ΑΠΔΠΧ στον ΟΤΕ: Ένας σχολιασμός
Γράφουν οι Ελπίδα Βαμβακά*, Στέργιος Κωνσταντίνου*, Εμμανουήλ Τζιβιέρης*
Η Αρχή Προστασίας Δεδομένων Προσωπικού Χαρακτήρα (στο εξής: “η Αρχή”) επέβαλε στον Οργανισμό Τηλεπικοινωνιών Ελλάδος Α.Ε. (εφεξής: “ΟΤΕ”) δύο πρόστιμα συνολικού ύψους 400.000 ευρώ αφενός για τη μη ικανοποίηση του δικαιώματος εναντίωσης και παραβίαση της αρχής της προστασίας των δεδομένων καθώς και για την παραβίαση της αρχής της ακρίβειας και της προστασίας των δεδομένων ήδη από τον σχεδιασμό κατά την τήρηση προσωπικών δεδομένων συνδρομητών της.
Οι σχετικές αποφάσεις είναι δημοσιευμένες στην ιστοσελίδα της Αρχής.
Α. Σύντομη περιγραφή των δύο αποφάσεων της Αρχής:
i) Ως προς την απόφαση 34/2019: μη ικανοποίηση του δικαιώματος εναντίωσης και παραβίαση της αρχής της προστασίας των δεδομένων ήδη από τον σχεδιασμό κατά την τήρηση προσωπικών δεδομένων συνδρομητών.
Στην Αρχή υποβλήθηκαν δύο (2) καταγγελίες φυσικών προσώπων συνδρομητών του ΟΤΕ από παραλήπτες μηνυμάτων διαφημιστικού περιεχομένου, σχετικά με την αδυναμία διαγραφής τους από τη λίστα αποδεκτών μηνυμάτων διαφημιστικού περιεχομένου.
Κατά την εξέταση των καταγγελιών αυτών προέκυψε ότι, από το 2013 και μετά, λόγω τεχνικού σφάλματος, δεν λειτουργούσε η διαγραφή από τις λίστες αποδεκτών των μηνυμάτων διαφημιστικού περιεχομένου για όσους παραλήπτες άσκησαν το δικαίωμά τους αυτό, μέσω του συνδέσμου «unsubscribe» ενώ, οι εναλλακτικοί μηχανισμοί, δηλαδή τηλεφωνικά και με αποστολή μηνύματος ηλεκτρονικού ταχυδρομείου, λειτουργούσαν.
Μόλις αυτό έγινε αντιληπτό, μετά την παρέμβαση της Αρχής, διορθώθηκε το σφάλμα και o OTE προέβη στη διαγραφή 8.000 περίπου συνδρομητών, οι οποίοι είχαν ανεπιτυχώς προσπαθήσει να διαγραφούν από τις λίστες αποδεκτών από το 2013.
Η Αρχή λοιπόν διαπίστωσε παράβαση του δικαιώματος εναντίωσης του υποκειμένου στην επεξεργασία για σκοπούς απευθείας εμπορικής προώθησης (άρθρο 21 παρ. 3) του Κανονισμού καθώς και του άρθρου 25 (προστασία των δεδομένων ήδη από το σχεδιασμό) του Κανονισμού και επέβαλε διοικητικό πρόστιμο στον ΟΤΕ.
Πιο συγκεκριμένα, η Αρχή αξιολογώντας,
α. τη χρονική διάρκεια του συμβάντος κατά το οποίο συνδρομητές του ΟΤΕ στερήθηκαν του δικαιώματός τους (από το 2013, 8.000 περίπου συνδρομητές είχαν ανεπιτυχώς προσπαθήσει να διαγραφούν)
β. τα στοιχεία που είναι δημόσια διαθέσιμα στο Γ.Ε.Μ.Η., από τα οποία προκύπτουν τα έσοδα του ομίλου ΟΤΕ για το έτος 2018 (2.887,6 εκατομμύρια ευρώ) και
γ. ότι το συμβάν δεν οφείλεται σε δόλο του υπευθύνου επεξεργασίας
Επέβαλε στον ΟΤΕ διοικητικό πρόστιμο ύψους 200.000 ευρώ, με βάση τα κριτήρια του άρθρου 83 §2 του ΓΚΠΔ.
ii) Ως προς την απόφαση 31/2019: παραβίαση της αρχής της ακρίβειας και της προστασίας των δεδομένων ήδη από τον σχεδιασμό κατά την τήρηση προσωπικών δεδομένων συνδρομητών
Στην προκειμένη περίπτωση, υποβλήθηκαν καταγγελίες των πελατών του ΟΤΕ με τις οποίες, οι καταναλωτές παραπονέθηκαν ότι, παρότι είχαν εγγραφεί στο μητρώο του άρθρου 11 του νόμου 3471/2006,[1] συνέχιζαν να λαμβάνουν κλήσεις από τρίτες εταιρείες για απευθείας εμπορική προώθηση.
Όπως διαπιστώθηκε, οι εν λόγω συνδρομητές είχαν υποβάλει αίτημα φορητότητας για τη μεταφορά της τηλεφωνικής τους σύνδεσης σε άλλο πάροχο. Σε ικανοποίηση του αιτήματος των συνδρομητών, ο ΟΤΕ διέγραψε τα στοιχεία τους από το μητρώο. Ωστόσο, όταν οι συγκεκριμένοι συνδρομητές ακύρωσαν το αίτημα φορητότητας, δεν υπήρχε ορθή διαδικασία για την ακύρωση της διαγραφής τους από το τηρούμενο μητρώο του άρθρου 11.
Οι συνδρομητές εμφανίζονταν μεν ως εγγεγραμμένοι στο μητρώο στην εσωτερική εφαρμογή- σύστημα- του ΟΤΕ, αλλά οι τηλεφωνικοί αριθμοί τους δεν περιλαμβάνονταν στο μητρώο, που έστειλε ο ΟΤΕ στις συνεργαζόμενες εταιρείες διαφήμισης, αφού τα δύο συστήματα λόγω του σφάλματος στη διασύνδεσή τους, δεν είχαν το ίδιο περιεχόμενο. Αποτέλεσμα αυτού ήταν οι συγκεκριμένοι συνδρομητές να λαμβάνουν διαφημιστικά μηνύματα παρότι είχαν εγγραφεί στο μητρώο του άρθρου 11.
Για την ανωτέρω περίπτωση η Αρχή έκρινε ότι, υπάρχει παράβαση μη ορθής τήρησης του μητρώου του άρθρου 11 ακόμη και όταν η μη ορθή τήρηση οφείλεται σε επιβεβαιωμένο τεχνικό πρόβλημα καθώς συνεπάγεται: α) παράβαση της αρχής προστασίας των δεδομένων ήδη από τον σχεδιασμό κατά την τήρηση προσωπικών δεδομένων συνδρομητών της και της αρχής της ακρίβειας και β) στέρηση του δικαιώματος των συνδρομητών να μη λαμβάνουν αυτόκλητες διαφημιστικές κλήσεις, ενώ είχαν την εντύπωση ότι διασφαλιζόταν η άσκηση του δικαιώματος αυτού.
Με την 31/2019 απόφαση της Αρχής , η αρχή επέβαλε πρόστιμο ποσού διακοσίων χιλιάδων ευρώ (200.000) στον ΟΤΕ.
B) Κάποιες σκέψεις
i) ως προς το επιβληθέν τελικά πρόστιμο
Το πρώτο πράγμα που διακρίνει κανείς διαβάζοντας τις δύο αποφάσεις είναι φυσικά το ύψος του επιβληθέντος προστίμου. Το σωρευτικό πρόστιμο των 400.000€ αποτελεί το υψηλότερο πρόστιμο που έχει επιβληθεί ποτέ από την Αρχή.
Υπενθυμίζεται ότι, το ανώτατο προβλεπόμενο πρόστιμο, σύμφωνα με τις διατάξεις του «παλιού» Ν. 2472/1997, ήταν οι 150.000 €, ενώ σε αυτό το ύψος ανήλθε και το πρόσφατο πρόστιμο που επέβαλε η Αρχή στην PwC με την υπ’ αριθμόν 26/2019 απόφαση της, εφαρμόζοντας, ωστόσο, τις διατάξεις του Γενικού Κανονισμού Προστασίας Δεδομένων[2] (στο εξής ΓΚΠΔ). Αν και δε πρόκειται για το πρώτο πρόστιμο που επιβάλλει η Αρχή κατ’ εφαρμογή των διατάξεων του ΓΚΠΔ, εντούτοις είναι η πρώτη φορά που ξεπερνά το «φράγμα» των 150.000€.
Επιπλέον, στις συγκεκριμένες αποφάσεις η Αρχή εφαρμόζει πιστά τα κριτήρια επιμέτρησης διοικητικών προστίμων, όπως προβλέπονται στο άρθρο 83 ΓΚΠΔ και όπως τα εφάρμοσε και στην 26/2019. Ειδικότερα στις σκέψεις 6, 7 και 8 αμφότερων των αποφάσεων, λαμβάνονται υπόψη τα εξής:
α) Η βαρύτητα και η διάρκεια της παράβασης,
β) Το πλήθος θιγόμενων υποκειμένων επεξεργασίας,
γ) Τα τεχνικά και οργανωτικά μέτρα που έλαβε ο υπεύθυνος της επεξεργασίας,
δ) Τον δόλο του υπευθύνου της επεξεργασίας
ε) Την οικονομική κατάσταση του υπεύθυνου επεξεργασίας,
στ) Προηγούμενες παραβάσεις του υπευθύνου επεξεργασίας ,
ζ) Η διάθεση συνεργασίας με την Αρχή.
Παράλληλα, η Αρχή με τις δύο αυτές αποφάσεις, στέλνει ηχηρό μήνυμα στους υπεύθυνους επεξεργασίας να μην υποτιμούν την υποχρέωση για ακρίβεια των δεδομένων και προστασία τους ήδη από τον σχεδιασμό, ενώ ιδιαίτερη έμφαση δίνεται στην τήρηση των κατάλληλων τεχνικών και οργανωτικών μέτρων με παράθεση συγκεκριμένων παραδειγμάτων ορθής συμμόρφωσης, όπως η τήρηση διαδικασίας ικανοποίησης δικαιωμάτων των υποκειμένων και η διενέργεια περιοδικών ελέγχων.
ii) Ως προς την αλληλεπίδραση του ν.3471/2006 και του ΓΚΠΔ
Οι καταγγελίες που οδήγησαν στην έκδοση των δύο αποφάσεων, έδωσαν την ευκαιρία στην Αρχή, να ξεκαθαρίσει, στην Ελληνική εφαρμογή, τα ζητήματα που προκύπτουν όταν οι διατάξεις του ΓΚΠΔ εφαρμόζονται ταυτόχρονα με τις διατάξεις του ν.3471/2006. O τελευταίος, αποτελεί ενσωμάτωση της οδηγίας για το e-Privacy[3] και ρυθμίζει την προστασία των προσωπικών δεδομένων στον τομέα των ηλεκτρονικών επικοινωνιών.
Με μια λιτή αλλά περιεκτική διατύπωση η Αρχή, με την υπ’ αριθμόν 31/2019 απόφασή της εύλογα έκρινε ότι “για κάθε ζήτημα σχετικό με την παροχή υπηρεσιών ηλεκτρονικών επικοινωνιών που δεν ρυθμίζεται ειδικότερα στον ν. 3471/2006 εφαρμόζεται ο ΓΚΠΔ”.
Επί της ουσίας, η αρχή ξεκαθάρισε ότι, οι βασικές αρχές που διέπουν την επεξεργασία δεδομένων και που προβλέπονται στο άρθρο 5 και 25 του ΓΚΠΔ, καθώς και οι παράγωγες διατάξεις τους, τυγχάνουν πλήρους εφαρμογής σε όλους τους τύπους επεξεργασίας, συμπεριλαμβανομένης και της επεξεργασίας για την διεξαγωγή της ηλεκτρονικής επικοινωνίας. Πρακτικά εφαρμόζεται η αρχή «lex specialis derogate legi generali»[4] βάσει της οποίας ο ν.3471/2006, ως «lex specialis», εξειδικεύει τον ΓΚΠΔ σχετικά με τις ηλεκτρονικές επικοινωνίες. Συνεπώς, εν απουσία ειδικών διατάξεων, το lex generalis -δηλαδή ο ΓΚΠΔ- εφαρμόζεται[5].
Η απόφαση αυτή ουσιαστικά, αποτελεί την συνέχεια μιας παγιωμένης Ενωσιακής πρακτικής η οποία προσδιορίστηκε νομολογιακά,[6] νομοθετικά[7] και εκφράστηκε από την Ομάδα Εργασίας του άρθρου 29[8] και το Ευρωπαϊκό Συμβούλιο Προστασίας Δεδομένων (στο εξής ΕΣΠΔ)[9].
iii) ως προς τον τύπο ευθύνης του παρόχου
Και στις δύο αποφάσεις η Αρχή συμπεριλαμβάνει στο σκεπτικό της την ανυπαρξία δόλου από την πλευρά του υπευθύνου της επεξεργασίας.[10]
Η παράμετρος του δόλου και της αμέλειας παίζει ρόλο στον προσδιορισμό του ύψους του προστίμου αλλά και στην θεμελίωση της ευθύνης εκ μέρους του υπευθύνου της επεξεργασίας. Στον ΓΚΠΔ ορίζεται πως “[κ]άθε πρόσωπο το οποίο υπέστη υλική ή μη υλική ζημία ως αποτέλεσμα παραβίασης του παρόντος κανονισμού δικαιούται αποζημίωση από τον υπεύθυνο επεξεργασίας”[11] και πως “κάθε υπεύθυνος επεξεργασίας που συμμετέχει στην επεξεργασία είναι υπεύθυνος για τη ζημία που προκάλεσε η εκ μέρους του επεξεργασία που παραβαίνει τον παρόντα κανονισμό.”[12] Επίσης, στο ν. 3471/2006 ορίζεται ρητά πως “[φ]υσικό ή νοµικό πρόσωπο που, κατά παράβαση του νόµου αυτού, προκαλεί περιουσιακή βλάβη υποχρεούται σε πλήρη αποζηµίωση”[13].
Και στα δύο ρυθμιστικά πλαίσια, οι προϋποθέσεις γέννησης της ευθύνης που προκύπτουν από την γραμματική ερμηνεία των διατάξεων είναι η ζημία, η παραβίαση του κανόνα και η αιτιώδης συνάφεια ανάμεσα σε αυτά τα δύο. Σε κανένα σημείο δεν προβλέπεται η ύπαρξη υπαιτιότητας για την θεμελίωση της ευθύνης. Κάτι που θα έπρεπε να αναφέρεται ρητά.[14]
Συνεπώς, προκύπτει πως κατ’αρχήν ο υπεύθυνος επεξεργασίας έχει γνήσια αντικειμενική ευθύνη για τις επεξεργασίες που πραγματοποιεί. Ωστόσο, η ευθύνη αυτή τρέπεται σε νόθο αντικειμενική από την τρίτη παράγραφο του άρθρου 82 του ΓΚΠΔ η οποία ορίζει ότι “[ο] υπεύθυνος επεξεργασίας […] απαλλάσσεται από την ευθύνη […] εάν αποδεικνύει ότι δεν φέρει καμία ευθύνη για το γενεσιουργό γεγονός της ζημίας”.
Το ίδιο ίσχυε με το νόμο 2472/1997[15] όπου κατ’ αρχήν με το άρθρο 23 θεμελιώνονταν γνήσια αντικειμενική ευθύνη. Ωστόσο, η δεύτερη παράγραφος του ίδιου άρθρου η οποία όριζε πως “[η] κατά το άρθρο 932 ΑΚ χρηματική ικανοποίηση λόγω ηθικής βλάβης για παράβαση του παρόντος νόμου […] παράβαση οφείλεται σε αμέλεια”[16] και συνεπώς μετέτρεπε την ευθύνη του υπεύθυνου από γνήσια αντικειμενική, σε νόθο αντικειμενική[17].
Η άποψη ότι η ευθύνη του υπευθύνου επεξεργασίας είναι νόθος αντικειμενική υποστηρίχθηκε από την Ελληνική νομολογία[18] καθώς και από μια μερίδα της θεωρίας.[19] Το ότι ο πάροχος υπηρεσιών υπέχει νόθο αντικειμενική ευθύνη υποστηρίζεται και από τις εθνικές διατάξεις όμορων δικαιϊκών κλάδων, όπως το δίκαιο της προστασίας του καταναλωτή.[20]
Τέλος, βάσει της αρχής της λογοδοσίας[21] ο υπεύθυνος επεξεργασίας έχει το βάρος ευθύνης της απόδειξης της συμμόρφωσης του με τις βασικές αρχές της επεξεργασίας που προβλέπει ο ΓΚΠΔ. Συνεπώς και ως προς την συμμόρφωση του με τον Κανονισμό, η ευθύνη του υπεύθυνου συνιστά τελικά νόθο αντικειμενική ευθύνη.
[1] Σύμφωνα με το άρθρο 11 § 2 του ν.3471/2006, οι φορείς παροχής της επικοινωνίας υποχρεούνται να τηρούν ειδικό κατάλογο με τους συνδρομητές που έχουν δηλώσει προς τον φορέα παροχής της υπηρεσίας, ότι δεν επιθυμούν γενικώς να γίνονται δέκτες μη ζητηθείσας επικοινωνίας για σκοπούς μάρκετινγκ.
[2] Κανονισμός (ΕΕ) 2016/679 του Ευρωπαϊκού Κοινοβουλίου και του Συμβουλίου, της 27ης Απριλίου 2016, για την προστασία των φυσικών προσώπων έναντι της επεξεργασίας των δεδομένων προσωπικού χαρακτήρα και για την ελεύθερη κυκλοφορία των δεδομένων αυτών και την κατάργηση της οδηγίας 95/46/ΕΚ (Γενικός Κανονισμός για την Προστασία Δεδομένων)
[3] Οδηγία 2002/21/ΕΚ του Ευρωπαϊκού Κοινοβουλίου και του Συμβουλίου, της 7ης Μαρτίου 2002, σχετικά με κοινό κανονιστικό πλαίσιο για δίκτυα και υπηρεσίες ηλεκτρονικών επικοινωνιών
[4] Απόφαση της 22ης Απριλίου 2016, RENV I και RENV II, Τ-50/06, EU:T:2016:227, σκέψη 81
[5] Ευρωπαϊκό Συμβούλιο Προστασίας Δεδομένων, Γνώμη 5/2019 σχετικά με την αλληλεπίδραση μεταξύ της Οδηγίας για την προστασία της ιδιωτικής ζωής στον τομέα των ηλεκτρονικών επικοινωνιών και του ΓΚΠΔ, ιδίως όσον αφορά την αρμοδιότητα, τα καθήκοντα και τις εξουσίες των αρχών προστασίας δεδομένων, 12 Μαρτίου 2019, σ. 18
[6] Απόφαση της 5ης Ιουνίου 2018, Wirtschaftsakademie, C-210/16, EU:C:2018:388, σκέψεις 33 -34
[7] ‘Άρθρο 95 σε συνδυασμό με την αιτιολογική σκέψη 173 ΓΚΠΔ
[8] Ομάδα Εργασίας του άρθρου 29 για την προστασία των δεδομένων, Γνώμη 2/2010 σχετικά με την επιγραμμική συμπεριφορική διαφήμιση, 22 Ιουνίου 2010, WP 171, σ. 11. Βλ. επίσης Γνώμη 1/2008 σχετικά με τα θέματα προστασίας δεδομένων σε σχέση με τις μηχανές αναζήτησης, 4 Απριλίου 2008,WP148, ενότητα 4.1.3, σ. 13-15
[9] Ευρωπαϊκό Συμβούλιο Προστασίας Δεδομένων, Γνώμη 5/2019 σχετικά με την αλληλεπίδραση μεταξύ της Οδηγίας για την προστασία της ιδιωτικής ζωής στον τομέα των ηλεκτρονικών επικοινωνιών και του ΓΚΠΔ, ιδίως όσον αφορά την αρμοδιότητα, τα καθήκοντα και τις εξουσίες των αρχών προστασίας δεδομένων, 12 Μαρτίου 2019
[10] ΑΠΔΠΧ, Αποφάσεις 31/2019,Γ/ΕΞ/6223/13-09-2019 και 34/2019 Γ/ΕΞ/6549/30-09-2019, σκέψη 8
[11] Άρθρο 82§1 ΓΚΠΔ
[12] Άρθρο 82§2 εδ.α’ ΓΚΠΔ
[13] Άρθρο 14§1 εδ.α’’ ν.3471/2006
[14] Αι. Βραττή (2012), Η αστική ευθύνη στο νόμο περί προστασίας δεδομένων προσωπικού χαρακτήρα, Διπλωματική εργασία, σ.42. Διαθέσιμο στο https://pergamos.lib.uoa.gr/uoa/dl/frontend/file/lib/default/data/1321570/theFile (τελευταία πρόσβαση 13/10/2019)
[15] Άρθρο 21§1 εδ.α’ ν.2472/1997 και Άρθρο 21§1 εδ.γ’ ν.2472/1997
[16] Άρθρο 21§2 ν.2472/1997
[17] Αι. Βραττή (2012), Η αστική ευθύνη στο νόμο περί προστασίας δεδομένων προσωπικού χαρακτήρα, Διπλωματική εργασία, σ.43. Διαθέσιμο στο https://pergamos.lib.uoa.gr/uoa/dl/frontend/file/lib/default/data/1321570/theFile (τελευταία πρόσβαση 13/10/2019)
[18] ΑΠ 1923/2006, ΝοΒ 2006, σελ 367, ΑΠ 353/2009, ΝοΒ 2009, σελ 1428, ΑΠ 174/2011, ΝοΒ 2011, σελ 1606
[19] Ι. Ιγγλεζάκης, Ευαίσθητα Προσωπικά Δεδομένα, Εκδόσεις Σάκκουλας,Αθήνα-Θεσσαλονίκη 2004, σ. 283-284
[20] Άρθρο 8 του Ν. 2251/1994 περί «προστασίας καταναλωτών», όπως αυτό τροποποιήθηκε με το άρθρο 10 του Ν. 3587/2007
[21] Η οποία ρυθμίζεται με τα άρθρα 5,77,82 και 83 ΓΚΠΔ
*Η Ελπίδα Βαμβακά είναι πρόεδρος της Homo Digitalis και νομική σύμβουλος της Enartia Group.
*Ο Στέργιος Κωνσταντίνου είναι δικηγόρος με εξειδίκευση στην προστασία προσωπικών δεδομένων.
*Ο Εμμανουήλ Τζιβιέρης είναι Υπεύθυνος Προστασίας Δεδομένων (DPO) της Optima Bank.

Μήπως τελικά έχουμε κάτι να κρύψουμε;
Γράφει ο Δημήτρης Ντόσας*
Υπάρχει -διεθνώς- μια παραδοξότητα που βρίσκεται σε εξέλιξη.
Από τη μία πλευρά, παρατηρείται μια ολοένα αυξανόμενη ευαισθητοποίηση του κόσμου στον τομέα των προσωπικών δεδομένων, της online παρακολούθησης, των ψηφιακών δικαιωμάτων. Από την άλλη, πολλοί και πολλές τείνουν να πιστεύουν πως η ιδιωτικότητα δεν είναι θέμα μείζονος σημασίας καθώς “δεν έχουν κάτι να κρύψουν”.
Αυτό συμβαίνει για πολλούς λόγους. Η κυρίαρχη αφήγηση θέλει να συνδέσει τη μαζική παρακολούθηση με την έρευνα για άσκηση παράνομων δραστηριοτήτων. Ταυτόχρονα, θεωρούμε πως οι μεγάλες εταιρείες του GAFAM (Google, Apple, Facebook, Amazon και Microsoft), και όχι μόνο, ασφαλίζουν επαρκώς τα δεδομένα μας οπότε δεν υπάρχει λόγος να φοβόμαστε την έκθεση.
Είναι όμως έτσι; Χρειάζεται να είσαι εγκληματίας ή τεχνοφρικιό (sic) για να σε απασχολεί το τι συμβαίνει με το ψηφιακό σου αποτύπωμα;
Μάλλον όχι!
Όπως πολύ εύστοχα είχε αναφέρει ο Edward Snowden, “το να λες ότι το δικαίωμα στην ιδιωτικότητα δε σε αφορά, επειδή δεν έχεις κάτι να κρύψεις, είναι το ίδιο με το να λες ότι το δικαίωμα της ελεύθερης έκφρασης δε σε αφορά, επειδή δεν έχεις κάτι να πεις”.
Στο παρόν άρθρο δεν έχουμε σκοπό να δώσουμε έτοιμες απαντήσεις, αλλά να θέσουμε το ερώτημα στη ορθή του βάση.
“Data is the new Oil”
Η τελευταία δεκαετία είναι μια πολύ συμπυκνωμένη ιστορικά περίοδος σε σχέση με την ενσωμάτωση της ανθρωπότητας στον ψηφιακό κόσμο.
Ο Homo Consumus υπέστη μια βίαιη μετάβαση, καθώς πολλές πρακτικές της καθημερινότητάς του μεταφέρθηκαν, ολοκληρωτικά ή μερικώς, σε ψηφιακό περιβάλλον.
Δραστηριότητες που άπτονται της επικοινωνίας, της ψυχαγωγίας, της κατανάλωσης, της αναζήτησης πληροφοριών, κλπ. είναι πλέον μόνο ένα “κλικ” μακριά.
Τα τελευταία χρόνια, η κάλυψη πολλών αναγκών μας γίνεται ευκολότερα και αποδοτικότερα μέσω των νέων τεχνολογιών και καινοτομιών, αλλά ταυτόχρονα παρουσιάζονται και δυνατότητες που χρήζουν συζήτησης.
Δυνατότητα 1: Οι ηλεκτρονικές συσκευές έχουν εξελιχθεί τόσο, ώστε να έχουν πλέον τη δυνατότητα καταγραφής μεγάλου εύρους της συμπεριφοράς και του περιβάλλοντος μας. Σκεφτείτε πόσα διαφορετικά είδη δεδομένων μπορούν να συλλέξουν οι σένσορες ενός έξυπνου κινητού. Τα δεδομένα αυτά αφορούν από τη θερμοκρασία και την τοποθεσία στην οποία βρισκόμαστε, μέχρι το πότε κοιμόμαστε κ.ο.κ. Επιπλέον, υπηρεσίες όπως οι μηχανές αναζήτησης και τα social media, συλλέγουν αναλυτικά στοιχεία για το τι διαβάζουμε, πώς αντιδρούμε σε αυτά, με ποιους και τι μοιραζόμαστε. Η λίστα είναι -σχεδόν- ατελείωτη.
Δυνατότητα 2: Είναι η πρώτη φορά που τα δεδομένα και οι πληροφορίες που προκύπτουν, μπορούν να καταγραφούν, να αποθηκευτούν και να επεξεργαστούν σε τόσο μεγάλους όγκους.
Ο συνήθης κύκλος ζωής -πλέον- μιας δραστηριότητας που γίνεται με ψηφιακό τρόπο είναι: α) να καταγραφεί από κάτι για κάποιον-κάπου, β) να αποθηκευτεί και να επεξεργαστεί, γ) να συνδυαστεί με άλλες για να παραχθούν συμπεράσματα.
Οι περιπτώσεις χρήσης που προκύπτουν ήταν αρκετές ώστε να καταστήσουν τη συλλογή και επεξεργασία δεδομένων ένα αγαθό με αξία τέτοια, που να θέτει σε αμφισβήτηση ακόμα και την πρωτοκαθεδρία του μαύρου χρυσού στην αντίστοιχη κλίμακα.
Είναι μια διαρκής καταγραφή της καθημερινής πρακτικής του ατόμου. Ένας τεράστιος όγκος στοιχείων που η σύνθεση τους μπορεί με μεγάλη ακρίβεια να προσδιορίσει ποιοι είμαστε, πώς ζούμε και επικοινωνούμε, πώς ερωτευόμαστε, τι ανάγκες έχουμε, τις πολιτικές-κοινωνικές πεποιθήσεις και πολλά άλλα
From personal profiling to social trends
Η ψηφιοποίηση της ζωής μας αποκτά ακόμα μεγαλύτερο ενδιαφέρον, διότι παράγει ένα μοναδικό προφίλ για τον καθένα και την καθεμιά από εμάς. Τα δεδομένα και τα μεταδεδομένα [1] της διαδικτυακής μας κίνησης μπορούν να σχηματίσουν ένα πολύ ακριβές και πλούσιο ψηφιδωτό της ψηφιακής μας ταυτότητας.
Μπορείτε ενδεικτικά να δείτε και εδώ και εδώ, μερικά από τα στοιχεία που διατηρούν δυο τεχνολογικοί κολοσσοί για εμάς.
Κάποιος θα ισχυριστεί ότι δεν έχει δα και τόση σημασία αν κάποιος γνωρίζει για σένα τι ψώνισες χθες από το σουπερμάρκετ, τι μουσική άκουσες το πρωί, πόσο συχνά μπαίνεις στο Instagram. Όλα τα παραπάνω είναι φαινομενικά ασήμαντα.
Ακόμα και αν ήταν δημόσια όλα αυτά τα στοιχεία για τη ζωή κάποιου, δε θα απειλούνταν με άμεσο τρόπο η προσωπικότητα και η ελευθερία του σε μια φαινομενικά δημοκρατική κοινωνία.
Όντως, το να γνωρίζει κάποιος π.χ. τι μουσική άκουσες το πρωί, δεν έχει τόσο μεγάλη αξία από μόνο του.
Τι γίνεται, όμως, αν βρίσκεται υπό την κατοχή κάποιου ένα μεγάλο υποσύνολο του ψηφιακού ιστορικού σου;
Ποια άρθρα διάβασες, σε ποια νέα της επικαιρότητας έκανες like, με ποιους επικοινώνησες, τις αναζητήσεις σου στο Google, τις ώρες που είσαι ενεργός, μέχρι και τι φαγητό παρήγγειλες. Δε μιλάμε πλέον για ασύνδετα και μεμονωμένα δεδομένα και σίγουρα, δεν αναφερόμαστε πλέον σε μια συγκεκριμένη χρονική στιγμή. Είναι μια διαρκής καταγραφή της καθημερινής πρακτικής του ατόμου. Ένας τεράστιος όγκος στοιχείων που η σύνθεση τους μπορεί με μεγάλη ακρίβεια να προσδιορίσει ποιοι είμαστε, πώς ζούμε και επικοινωνούμε, πώς ερωτευόμαστε, τι ανάγκες έχουμε, πολιτικές-κοινωνικές πεποιθήσεις που ασπαζόμαστε και πληθώρα άλλων πραγμάτων.
Μεγαλώνοντας την κλίμακα παρατήρησης, αν αθροιστούν όλα αυτά τα ατομικά προφίλ, μπορούν να σχηματίσουν κοινότητες. Μπορούν να εξαχθούν κοινωνικές τάσεις σχηματίζοντας πλήθη με βάση γεωγραφικά κριτήρια, το φύλο, την εθνικότητα, τις καταναλωτικές συνήθειες, τα πολιτικά πιστεύω και μια σειρά άλλων διαστάσεων.
Είναι η στιγμή, που από χρήστες μιας πλατφόρμας γινόμαστε προϊόντα μια συναλλαγής, που δε θα μάθουμε ποτέ
If you are not paying for the product, the product is you
Οι δυνατότητες της νέας εποχής προφανώς δεν έχουν μείνει ανεκμετάλλευτες. Σχεδόν κάθε γνωστή εφαρμογή ή υπηρεσία που χρησιμοποιούμε στο διαδίκτυο, συλλέγει προσωπικά δεδομένα μας.
Αναρωτηθήκατε ποτέ ποιο είναι το επιχειρηματικό μοντέλο εταιρειών σαν τη Facebook και τη Google? Γιατί μας παρέχουν τόσο ποιοτικές υπηρεσίες δωρεάν; Το κάνουν γιατί κερδίζουν τα πολλαπλάσια από αυτά που ξοδεύουν μέσω της εκμετάλλευσης των δεδομένων και του περιεχομένου που εμείς παράγουμε. Είτε δίνοντας τη δυνατότητα σε ένα διαφημιστή για βέλτιστη εξατομικευμένη προώθηση προϊόντων είτε πουλώντας (με έντεχνο, νόμιμο (;) και ηθικό τρόπο, sic) τα δεδομένα σε τρίτα μέρη, όπως δημοσκοπικές εταιρείες και συμβούλους πολιτικής καμπάνιας, κ.ο.κ.
Εάν κάποιος σας έκανε 100 ερωτήσεις σχετικά με την προσωπική σας ζωή για να τα πουλήσει, θα του απαντούσατε; Πιθανώς όχι. Αλλά το αφήνουμε να συμβαίνει κάθε φορά που χρησιμοποιούμε μια υπηρεσία, που αποκομίζει κέρδη πουλώντας τις πληροφορίες μας. Είναι η στιγμή που, από χρήστες μιας πλατφόρμας γινόμαστε προϊόντα μια συναλλαγής, που δε θα μάθουμε ποτέ.
Και το σημαντικό βέβαια εδώ δεν είναι μόνο τα κέρδη. Αυτό που προκαλεί προβληματισμούς είναι ότι όλος αυτός ο όγκος πληροφοριών είναι εκεί, πάντα διαθέσιμος για κάποιον να τον εκμεταλλευτεί για σκοπούς που δεν μπορούμε να γνωρίζουμε και, προφανώς, ούτε να ελέγξουμε. Τι θα γινόταν αν όλη αυτή η πληροφορία έπεφτε σε “λάθος χέρια”;
Σε μια φαινομενικά πιο αθώα περίπτωση, τα παραπάνω χρησιμοποιούνται από ένα διαφημιστή για λόγους μάρκετινγκ. Στη νέα ζοφερή πραγματικότητα, όμως, έχουν χρησιμοποιηθεί και για να χειραγωγήσουν το αποτέλεσμα των εκλογών σε μια από τις πιο ισχυρές χώρες του πλανήτη, τις ΗΠΑ. Ναι, έχει συμβεί και αξίζει το θέμα λίγο από το χρόνο σας, δείτε περισσότερα εδώ.
Privacy Matters
Ο ερχομός του Διαδικτύου είχε ενθουσιώδη χαρακτηριστικά και ένα από αυτά αποτελεί το γεγονός πως είναι το μόνο μέσο όπου, θεωρητικά και πρακτικά, εμείς επιλέγουμε με ποιες πληροφορίες θα αλληλεπιδράσουμε.
Ταυτόχρονα, η ολοένα και αυξανόμενη ψηφιακή έκθεση μας καθιστά ευάλωτους τόσο σε προσωπικό, όσο και συλλογικό επίπεδο. Όσοι έχουν πρόσβαση στο ψηφιακό μας αποτύπωμα, ασχέτως των προθέσεων τους, έχουν τη δυνατότητα της άμεσης ή έμμεσης παρακολούθησης ποικίλων πτυχών της ζωής μας.
Σε αυτό το νέο περιβάλλον, η ιδιωτικότητα είναι αναγκαία προϋπόθεση εξέλιξης. Είναι κάτι που χρειαζόμαστε για να εξερευνήσουμε τον εαυτό μας, να αποκτήσουμε γνώση και να πάρουμε αποφάσεις σχετικά με τη ζωή μας. Είναι κάτι που μπορεί να διασφαλίσει την ποιότητα της περιήγησης και την αποφυγή εσφαλμένων κατηγοριοποιήσεων του εαυτού μας με ταμπέλες που μπορούν εν δυνάμει να στραφούν εναντίον μας.
Είναι μια προϋπόθεση απαραίτητη ώστε να μπορεί κάποιος να εξερευνήσει τη σεξουαλικότητα του χωρίς να χρειάζεται μετά να γίνεται στόχος διαφημιστικών μηνυμάτων, λόγω των προτιμήσεων του. Είναι προϋπόθεση, ώστε ένας εργαζόμενος να μπορεί να ψάξει μια εναλλακτική στην καριέρα του, χωρίς το φόβο ότι θα ενημερωθεί ο εργοδότης του. Είναι προϋπόθεση για να μπορούμε να εξερευνήσουμε ιδεολογίες και γνώση χωρίς να στιγματιστούμε από κάποιον αλγόριθμο ως “ακραίοι”. Τα παραδείγματα είναι πολλά.
Και η ουσία σε αυτό το σημείο είναι πως χωρίς την έννοια της ιδιωτικότητας, αυτής της μορφής η αυτο-εξερεύνηση δεν υφίσταται.
Η αξία κάθε νέας τεχνολογίας και καινοτομίας έγκειται στη χρήση τους
Αντί επιλόγου
Την τελευταία δεκαετία έχουν ωριμάσει τεχνολογίες με επαναστατικά χαρακτηριστικά ως προς τις δυνατότητες τους. To Διαδίκτυο, οι έξυπνες ηλεκτρονικές συσκευές, τα Big Data, η τεχνητή νοημοσύνη αποτελούν στοιχεία, που μπορούν να διαδραματίσουν σημαντικό ρόλο στην πρόοδο των επιστημών και της ανθρωπότητας.
Όμως, το νόμισμα αυτό έχει δύο όψεις. Και πέρα από το θετικό κοινωνικό αντίκτυπο που μπορεί φυσικά να προκύψει, πρέπει να τονίσουμε και προκαταβάλουμε τις ανησυχητικά αρνητικές συνέπειες που εμφανίζονται από την καταχρηστική εκμετάλλευση τους.Γιατί, εν τέλει, η αξία κάθε νέας τεχνολογίας και καινοτομίας έγκειται στη χρήση τους.
Αν θέλουμε να απολαμβάνουμε τα προνόμια της νέας ψηφιακής εποχής χωρίς να κινδυνεύουν οι προσωπικές μας ελευθερίες, οφείλουμε να θωρακίσουμε τους εαυτούς και τις κοινωνίες μας από αυτό το νέο είδος biased διαμεσολάβησης.
Και η πρωταρχική συνθήκη για να το πετύχουμε, είναι να επαναπροσδιορίσουμε τη στάση μας απέναντι στο μετασχηματισμό των προσωπικών δεδομένων από πυρήνα των ατομικών δικαιωμάτων σε κάτι που δεν μας ανήκει, σε κάτι στο οποίο δεν έχουμε ιδιοκτησία, παρά μόνον πρόσβαση.
Το ερώτημα, τελικά, δεν είναι αν υπάρχουν πράγματα που χρειάζεται να “κρύψουμε”, αλλά πόσα είναι αυτά και γιατί.
[1] Ποια η διαφορά δεδομένων και μετα-δεδομένων; Για παράδειγμα σκεφτείτε μια τηλεφωνική κλήση. Τα δεδομένα της κλήσης είναι το τι είπατε, ενώ τα μετα-δεδομένα είναι, τι ώρα καλέσατε, από πού μιλήσατε και πόσο διήρκεσε η κλήση, κτλπ.
* Ο Δημήτρης Ντόσας είναι Μηχανικός Υποδομών και Κυβερνοασφάλειας. Συμμετέχει επί έτη σε έργα συμμόρφωσης δημόσιων και ιδιωτικών οργανισμών στους τομείς της Ασφάλειας Πληροφοριών και επεξεργασίας Προσωπικών Δεδομένων.

Κρυπτογράφηση και Αποκρυπτογράφηση
Γράφει ο Αναστάσιος Αραμπατζής*
Η κρυπτογράφηση βασίζεται στην επιστήμη της κρυπτογραφίας, η οποία είναι τόσο παλιά όσο και η ανάγκη του κόσμου να κρατήσει ορισμένες πληροφορίες μυστικές. Η κρυπτογραφία χρησιμοποιείται για τη διασφάλιση και την προστασία των δεδομένων κατά τη στιγμή της επικοινωνίας. Πριν από την ψηφιακή εποχή, οι μεγαλύτεροι χρήστες της κρυπτογραφίας ήταν οι κυβερνήσεις, ιδιαίτερα για στρατιωτικούς σκοπούς. Η κρυπτογραφία έχει μακρά ιστορία, που χρονολογείται από την εποχή που οι αρχαίοι Έλληνες και Ρωμαίοι έστελναν μυστικά μηνύματα υποκαθιστώντας γράμματα, αποκρυπτογραφούμενα μόνο με τη χρήση ενός μυστικού κλειδιού.
Για τη μεταφορά ευαίσθητων πληροφοριών, ένα σύστημα πρέπει να είναι σε θέση να διασφαλίζει τη μυστικότητα (secrecy) και την ιδιωτικότητα (privacy). Ένα σύστημα επικοινωνιών δεν μπορεί να αποτρέψει με απόλυτο τρόπο τη μη εξουσιοδοτημένη πρόσβαση στα μέσα μετάδοσης.
Η αλλοίωση των δεδομένων, η πράξη της σκόπιμης τροποποίησης των δεδομένων μέσω ενός μη εξουσιοδοτημένου καναλιού, δεν είναι ένα νέο πρόβλημα. Η αλλαγή της πληροφορίας θα μπορούσε, ενδεχομένως, να την προστατεύσει από μη εξουσιοδοτημένη πρόσβαση και, ως εκ τούτου, μόνο ο εξουσιοδοτημένος αποδέκτης να μπορεί να την κατανοήσει.
Η κρυπτογράφηση και η αποκρυπτογράφηση είναι οι δύο βασικές λειτουργίες της κρυπτογραφίας.
Ιστορία της κρυπτογράφησης
Οι αρχαίοι Έλληνες χρησιμοποιούσαν ένα εργαλείο που ονομαζόταν Σκυτάλη για να επιτύχουν ταχύτερη κρυπτογράφηση των μηνυμάτων τους. Τύλιγαν μία λωρίδα περγαμηνής γύρω από ένα πολύπλευρο κύλινδρο, έγραφαν το μήνυμα και στη συνέχεια, όταν η περγαμηνή ξετυλίγονταν, το κείμενο δεν είχε νόημα.
Αυτή η μέθοδος κρυπτογράφησης μπορούσε φυσικά να “σπάσει” εύκολα, αλλά είναι ένα από τα πρώτα παραδείγματα κρυπτογράφησης που χρησιμοποιήθηκαν ιστορικά.
Ο Ιούλιος Καίσαρας χρησιμοποίησε μια κάπως παρόμοια μέθοδο, μεταθέτοντας κάθε γράμμα της αλφαβήτου προς τα δεξιά ή προς τα αριστερά κατά μια προκαθορισμένη σειρά θέσεων, μια τεχνική κρυπτογράφησης που έμεινε γνωστή ως ο “Κώδικας του Καίσαρα”.
Δεδομένου ότι μόνο ο προορισμένος παραλήπτης του μηνύματος γνώριζε τον κώδικα, ήταν δύσκολο για οποιοδήποτε άλλο άτομο να αποκωδικοποιήσει το μήνυμα.
Κατά τη διάρκεια του Β Παγκοσμίου Πολέμου, οι Γερμανοί χρησιμοποίησαν τη μηχανή Enigma για να μεταβιβάσουν κρυπτογραφημένες μηνύματα προς και από το πεδίο της μάχης.
Οι συμμαχικές δυνάμεις χρειάστηκαν αρκετά χρόνια πριν μπορέσουν να σπάσουν τον κώδικα, γεγονός που συνέβαλε στη νίκη τους.
Τι είναι όμως η κρυπτογράφηση;
Η κρυπτογράφηση (encryption) είναι η διαδικασία κατά την οποία ο αποστολέας μετατρέπει την αρχική πληροφορία σε άλλη μορφή και μεταδίδει το προκύπτον ακατανόητο μήνυμα μέσω ενός ανοικτού δικτύου.
Ο αποστολέας χρησιμοποιεί έναν αλγόριθμο κρυπτογράφησης και ένα κλειδί για τη μετατροπή του απλού κειμένου (αρχικού μηνύματος) σε κρυπτοκείμενο (κρυπτογραφημένο μήνυμα).
Το απλό κείμενο (plaintext) είναι τα δεδομένα που πρέπει να προστατευθούν κατά τη διάρκεια της μετάδοσης.
Το κρυπτοκείμενο (cipher text) είναι το κωδικοποιημένο κείμενο που παράγεται ως αποτέλεσμα του αλγόριθμου κρυπτογράφησης για τον οποίο χρησιμοποιείται ένα συγκεκριμένο κλειδί.
Ο αλγόριθμος κρυπτογράφησης είναι ένας κρυπτογραφικός αλγόριθμος στον οποίο εισάγεται ένα απλό κείμενο και ένα κλειδί κρυπτογράφησης και παράγει ένα κρυπτογραφημένο κείμενο.
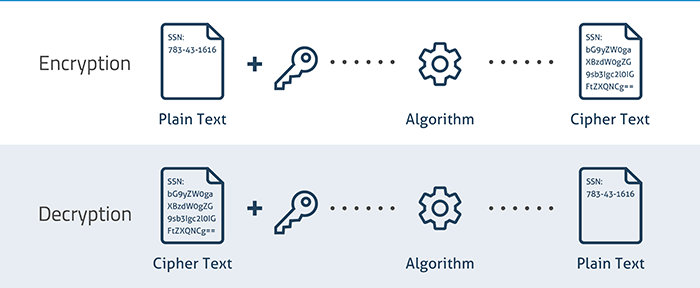
Εικόνα 1: Κρυπτογράφηση και Αποκρυπτογράφηση
Τι είναι η αποκρυπτογράφηση;
Η αποκρυπτογράφηση (decryption) αναστρέφει τη διαδικασία της κρυπτογράφησης για να μετατρέψει το μήνυμα στην αρχική του μορφή.
Ο δέκτης χρησιμοποιεί έναν αλγόριθμο αποκρυπτογράφησης και ένα κλειδί για να μετατρέψει το κρυπτοκείμενο στο αρχικό, απλό κείμενο.
Ο αλγόριθμος αποκρυπτογράφησης είναι μια μαθηματική διαδικασία που χρησιμοποιείται για την αποκρυπτογράφηση και παράγει το αρχικό απλό κείμενο ως αποτέλεσμα οποιουδήποτε δεδομένου κρυπτογραφημένου κειμένου και του κλειδιού αποκρυπτογράφησης.
Είναι η αντίστροφη διαδικασία του αλγόριθμου κρυπτογράφησης.
Κλειδιά κρυπτογράφησης και αποκρυπτογράφησης
Τα κλειδιά είναι τυχαία σειρά δυαδικών ψηφίων (bits) που δημιουργούνται ειδικά για την κρυπτογράφηση και αποκρυπτογράφηση δεδομένων.
Τα κλειδιά που χρησιμοποιούνται για κρυπτογράφηση και αποκρυπτογράφηση μπορεί να είναι είτε παρόμοια είτε ανόμοια, ανάλογα με τον τύπο των κρυπτοσυστημάτων που χρησιμοποιούνται (κρυπτογράφηση συμμετρικού κλειδιού ή κρυπτογράφηση ασύμμετρου ή δημόσιου κλειδιού).
Κάθε κλειδί είναι μοναδικό και δημιουργείται μέσω ενός αλγορίθμου ώστε να εξασφαλιστεί ότι δεν είναι προβλέψιμο. Τα κλειδιά παράγονται συνήθως με γεννήτριες τυχαίων αριθμών ή με αλγορίθμους υπολογιστών που μιμούνται γεννήτριες τυχαίων αριθμών.
Η κρυπτογράφηση συμμετρικού κλειδιού (symmetric key encryption) αναφέρεται στους αλγορίθμους που χρησιμοποιούν το ίδιο μυστικό κλειδί τόσο για την κρυπτογράφηση όσο και για την αποκρυπτογράφηση.
Εικόνα 2: Κρυπτογράφηση Συμμετρικού Κλειδιού
Η κρυπτογράφηση ασύμμετρου ή δημόσιου κλειδιού (asymmetric or public key encryption) αναφέρεται στους αλγόριθμους που χρησιμοποιούν ένα ζεύγος κλειδιών για τον σκοπό της κρυπτογράφησης.
Το δημόσιο κλειδί (public key) είναι διαθέσιμο σε οποιοδήποτε τυχαίο άτομο, ενώ το απόρρητο, ιδιωτικό κλειδί (private key) διατίθεται μόνο στον παραλήπτη του μηνύματος.
Βασικές διαφορές μεταξύ κρυπτογράφησης και αποκρυπτογράφησης
Παρακάτω παρατίθενται οι βασικές διαφορές μεταξύ της κρυπτογράφησης και της αποκρυπτογράφησης:
-Ο αλγόριθμος κρυπτογράφησης χρησιμοποιεί κατά τη διαδικασία κρυπτογράφησης ένα πρωτότυπο μήνυμα σε μια αναγνώσιμη μορφή, που ονομάζεται απλό κείμενο, και ένα κλειδί για να μετατρέψει το απλό κείμενο σε μια ακατανόητη και ασαφή μορφή που δεν μπορεί να ερμηνευτεί. Κατά τη διαδικασία της αποκρυπτογράφησης ο αλγόριθμος αποκρυπτογράφησης μετασχηματίζει, χρησιμοποιώντας το μυστικό κλειδί, την κρυπτογραφημένη μορφή του μηνύματος, το κρυπτοκείμενο, σε μορφή που μπορεί να κατανοηθεί από έναν άνθρωπο.
-Η κρυπτογράφηση πραγματοποιείται στη μεριά του αποστολέα, που καλείται πηγή, ενώ η αποκρυπτογράφηση πραγματοποιείται στο δέκτη, ο οποίος ονομάζεται προορισμός.
-Η κύρια λειτουργία της κρυπτογράφησης είναι η μετατροπή του απλού κειμένου σε κρυπτοκείμενο, ενώ η κύρια λειτουργικότητα της αποκρυπτογράφησης είναι η μετατροπή του κρυπτοκειμένου σε απλό κείμενο.
-Η κρυπτογράφηση πραγματοποιείται αυτόματα στην πηγή, όταν αποστέλλονται δεδομένα από ένα μηχάνημα. Προγράμματα που είναι προεγκατεστημένα μετασχηματίζουν τις αρχικές πληροφορίες σε κρυπτογραφημένη μορφή πριν από την αποστολή.
-Η αποκρυπτογράφηση πραγματοποιείται αυτόματα στο μηχάνημα του προορισμού. Το μηχάνημα λαμβάνει και μετατρέπει την κρυπτογραφημένη μορφή των δεδομένων στην αρχική μορφή.
-Η κρυπτογράφηση και η αποκρυπτογράφηση αλληλοσυνδέονται και θεωρούνται οι ακρογωνιαίοι λίθοι της διαφύλαξης της εμπιστευτικότητας, της ακεραιότητας και της διαθεσιμότητας των δεδομένων.
Χρήση ασύμμετρης και συμμετρικής κρυπτογράφησης: Εφαρμογές μηνυμάτων
Οι εφαρμογές μηνυμάτων, όπως το Signal ή το Whatsapp, χρησιμοποιούν κρυπτογράφηση από άκρο σε άκρο για την προστασία της εμπιστευτικότητας και της ιδιωτικότητας των επικοινωνιών των χρηστών και για την εξακρίβωση της ταυτότητας των χρηστών.
Στην κρυπτογράφηση από άκρο σε άκρο, κρυπτογραφούνται μόνο τα δεδομένα. Η βάση για την κρυπτογράφηση από άκρο σε άκρο είναι ένα πρωτόκολλο (Signal Protocol), το οποίο έχει αναπτυχθεί από την εταιρεία Open Whisper Systems. Αυτό το πρωτόκολλο κρυπτογράφησης από άκρο σε άκρο έχει σχεδιαστεί για να εμποδίζει τα τρίτα μέρη και την εταιρεία παραγωγής της εφαρμογής να έχουν ελεύθερη πρόσβαση σε μηνύματα ή κλήσεις.
Επιπλέον, ακόμη και αν τα κλειδιά κρυπτογράφησης από τη συσκευή ενός χρήστη έχουν παραβιαστεί, δεν μπορούν να χρησιμοποιηθούν για την αποκρυπτογράφηση μηνυμάτων που έχουν σταλεί στο παρελθόν.
Η κρυπτογράφηση των μηνυμάτων υλοποιείται χρησιμοποιώντας ασύμμετρη και συμμετρική κρυπτογράφηση. Η ασύμμετρη κρυπτογράφηση χρησιμοποιείται για την προετοιμασία της κρυπτογραφημένης συνομιλίας μεταξύ δύο χρηστών, ενώ η συμμετρική κρυπτογράφηση χρησιμοποιείται κατά τη διάρκεια της επικοινωνίας.
Χρήση ασύμμετρης και συμμετρικής κρυπτογράφησης: HTTPS
Ενώ η κρυπτογράφηση στις εφαρμογές μηνυμάτων χρησιμοποιείται για την ταυτοποίηση των χρηστών – ανθρώπων – το HTTPS χρησιμοποιείται για την ταυτοποίηση μηχανών. Σε έναν εξαιρετικά συνδεδεμένο κόσμο, όπου καθημερινά μεταφέρονται εκατομμύρια ευαίσθητα δεδομένα μέσω του διαδικτύου, η ανάγκη διασφάλισης των διαύλων επικοινωνίας μεταξύ πελατών / browsers και διακομιστών (servers) είναι υψίστης σημασίας.
Το HTTPS είναι ένα πρωτόκολλο του μοντέλου TCP/IP, το οποίο είναι ο συνδυασμός του πρωτοκόλλου ασφαλείας SSL/TLS (Secure Sockets Layer / Transport Layer Security) πάνω στο πρωτόκολλο HTTP (Hyper Text Transmission Protocol). Ουσιαστικά το HTTPS είναι η πράσινη κλειδαριά που βλέπουμε αριστερά από τη διεύθυνση της ιστοσελίδας που επισκεπτόμαστε.
Μια σύνδεση HTTPS μεταξύ ενός πελάτη και ενός διακομιστή χρησιμοποιεί και τους δύο τύπους κρυπτογράφησης. Η ασύμμετρη κρυπτογράφηση χρησιμοποιείται πρώτα για να δημιουργηθεί η σύνδεση, η οποία στη συνέχεια αντικαθίσταται με συμμετρική κρυπτογράφηση για όλη τη διάρκεια της σύνδεσης.
Και στις δύο περιπτώσεις, εφαρμογές μηνυμάτων και HTTPS, η ασύμμετρη κρυπτογράφηση χρησιμοποιείται μόνο σύντομα στην αρχή για την ανταλλαγή του συμμετρικού κλειδιού που χρησιμοποιείται για την υπόλοιπη σύνδεση. Αυτό γίνεται για να ξεπεραστεί το κύριο μειονέκτημα της ασύμμετρης κρυπτογράφησης, της μαθηματικής της πολυπλοκότητας, που την καθιστά αργή και ενεργοβόρα. Από την άλλη πλευρά, η χρήση ασύμμετρης κρυπτογράφησης επιλύει το πρόβλημα της διανομής κλειδιών της συμμετρικής κρυπτογράφησης.
*Ο Αναστάσιος Αραμπατζής είναι μέλος της Homo Digitalis, απόστρατος Αξιωματικός της Πολεμικής Αεροπορίας με πάνω από 25 χρόνια εμπειρία σε θέματα ασφάλειας πληροφοριών. Κατά τη θητεία του στην Π.Α. ήταν πιστοποιημένος αξιολογητής του ΝΑΤΟ σε θέματα κυβερνοασφάλειας και έχει τιμηθεί για τις γνώσεις του και την απόδοσή του. Σήμερα αρθρογραφεί για τη στήλη State of Security της εταιρείας Tripwire και για το blog της Venafi. Άρθρα του έχουν δημοσιευθεί σε πληθώρα έγκριτων ιστοσελίδων.