
Why should GDPR’s younger sister concern you as a citizen?
Processing of personal data by the police and other law enforcement authorities
By Lefteris Chelioudakis
General Regulation 2016/679 for the processing of personal data (GDPR) has monopolised interest recently. You may have already read articles by Homo Digitalis on GDPR or have read articles on newspapers, websites, etc.
But what do you know about GDPR’s younger sister, Directive 2016/680? Probably nothing.
EU Directive 2016/680 regulates a very important part of the processing of personal data, which must concern every citizen of a democratic country. The Directive concerns the processing of data by the national law enforcement authorities for the prevention, investigation, tracking or prosecution of crimes or the implementation of criminal sanctions.
Which are these authorities? Greek Police, the Hellenic Coast Guard and the Special Secretary of the Economic Crime Prosecution Authority, which is part of the Ministry of Economics, are some of them. Furthermore, Directive 2016/680 also applies on the activities of the national judiciary.
Regarding the judiciary, the acts and procedures of processing of personal data, which are included in court decisions or archives of criminal procedures, may be further elaborated by every EU Member States through its national legislation on criminal procedure (i.e. the Criminal Procedure Code in Greece).
The same national rules should regulate the implementation of the right to get informed, the right to access, the right to correction, the right to erasure and the right to limit the processing of personal data in the context of a criminal investigation and criminal procedure in the national courts.
Additionally, to safeguard the impartiality of the judiciary, the national monitoring authorities (such as the Authority for the Protection of Personal Data in Greece) do not have jurisdiction upon the processing of personal data when the courts act under their judicial power.
Furthermore, the EU Member States may provide that the national monitoring authorities do not have jurisdiction upon the processing of personal data by other judicial authorities, which act in their judicial power, such as the prosecuting authorities.
It must be noted though that the proper implementation of the Directive 2016/680 by courts and other judicial authorities should always be subject to impartial inspection, according to the EU Charter of Fundamental Rights Article 8, paragraph 3.
So, why is Directive 2016/680 important?
The first reason is that it replaces a very poor legislative framework, Decision 2008/977/ΔΕΥ, which unfortunately has a very limited scope – the transboundary exchange of data between law enforcement authorities of the EU Member States- and did not strike a fair balance between the necessities of law enforcement authorities in the context of their investigations and the rights of the persons involved in these investigations. As a result, the legal values on processing of personal data, were not respected and the rights of the data subjects were significantly weakened.
The second reason is that it constitutes the first step for the residents of the EU area to enjoy an equal level of protection when their personal data are processed by the police and the other law enforcement authorities. For the first time, a legal act regulates in a uniform fashion in the EU the way that the police officer in your neighborhood, the border guards, etc. may process your personal data. Therefore, when incorporated in the Greek legal order, the provisions of Directive 2016/680 must clearly regulate the way in which you will be able to exercise your rights before the police or the other law enforcement authorities.
It is for sure that in relation to the GDPR, your rights and the legal values regarding the processing of your personal data are significantly weaker.
However, there are provisions in which Directive 2016/680 is stricter than the GDPR. For instance, the recordings (Article 25) constitute one of these provisions. Thanks to them, when a police officer searches or shares information on you, your identity, the reason for his act and the precise date and time on which this act occurred must be recorded. Thus, these recorded files may subsequently be used to verify the legality of the processing, as well as the protection of objectivity and the safety of personal data in the context of criminal proceedings. Recordings constitute an extra obligation, which adds to the one of simple filing of the acts of processing (Directive 2016/680, Article 24 and GDPR Article 30).
Caution! Directive 2016/680 does not concern the processing of your personal data by intelligence services of the EU Member States, such as the National Intelligence Service in Greece. This happens because Directive 2016/680 is part of the EU legislation and EU law does not include issues of national security in its scope; these remain on the exclusive legislative discretion of each Member State. In this case, national law must be harmonized with the Council of Europe law and more particularly the European Convention on Human Rights kai the Convention on the protection of natural persons from automated processing of their personal data (“Convention 108”), which includes national intelligence services in its scope.
Directive 2016/680 must be transposed by all Member States in their national legal orders; this transposition is very important for the interpretation of its provision in the national level.
Although Member States should have adopted and published the necessary national legal reforms to comply with this Directive until 6 May 2018, until the day when this article was published, Greece had not adopted any law on the issue. Only Czech Republic, Ireland, Croatia, France, Italy, Austria, Luxembourg, Malta, Portugal, Germany, Lithuania, Sweden, United Kingdom and Slovakia have done so until today.
Homo Digitalis watches closely the procedure regarding the draft law for the Protection of Personal Data to comply with EU Regulation 2016/679 and incorporate EU Directive 2016/680. Thus, when the procedure is completed and the final provisions are voted, Homo Digitalis will inform you on your rights and the obligations of the law enforcement authorities.

Freedom of online expression needs you yet again!
What has happened until now?
On the 5th of July, a big win for the freedom of online expression and information was achieved.
Specifically, 318 MEPs (members of the European Parliament) voted against the proposed directive for copyrights in the Digital Market. Therefore, the directive was rejected.
At this point, we would like to remind you that the changes that the directive would cause on copyrights could considerably limit the freedom of expression and information on the Internet.
Those changes had the potential to even change the shape of the Internet as we know it.
What will happen now?
The total of 751 members of the European Parliament will now have the possibility to examine in detail the copyrights reform and submit amendments until the 5th of September.
Subsequently, the initial Proposal alongside with the new recommendations will be introduced in the European Parliament plenary on 12 September for a vote.
What can we do?
The majority of the Greek Parliament Members rejected the proposed directive at the 5th of July.
Thanks to the emails they received and the pressure by Greek voters and other Greek institutions –Homo Digitalis among them– they were informed and sensitized for the protection of the freedom of expression.
We can do the same now! By using the very simple tool that is offered here we can send mass messages to the Greek Parliament Members in order to put pressure on them to propose amendments for the proposed directive in favor of the protection of the freedom of online expression and information.
Let’s not forget that the European elections are not far off (23 and 26 May 2019). The more messages the Parliament Members receive, the more attention they will show for the retention of the Internet as we know it.
Send your message now. It will only take a minute but its impact can literally last for years!
Watch also the very interesting video of the campaign #SaveYourInternet.

The report of Homo Digitalis in the UN website
The report of the UN High Commissioner for Human Rights on the right to privacy in the digital age was published. The report will be presented in the 39th session of the UN Human Rights Council, which will take place in Geneva from 10 to 28 September 2018.
Homo Digitalis, responding to the open call of the High Commissioner, contributed in the drafting of the report by submitting its report.
In Chapter One of this report, Homo Digitalis focuses on encryption and anonymity as elements which reinforce human rights protection, including freedom of expression and freedom of opinion. In Chapter Two, Homo Digitalis evaluates the legislative framework on metadata of electronic communications in Greece. Finally, in the last Chapter of the report, Homo Digitalis puts forward its recommendations for the promotion and protection of the rights analysed in the two main Chapters.
The report of the UN High Commissioner is available here.
The report of Homo Digitalis has been published in the UN High Commissioner’s official website and is available here.
It must be noted that reports from Greece have also been submitted by the Ministry of Justice, the Home Office and the Ministry of Digital Policy, Telecommunications and Media.

Proposals to raise awareness through art and games in August
We are in the first days of August; a month which is linked to summer leisure. You might already be on vacation or might be expecting to do so soon. You might have just returned and be enjoying the calmness of August in the city; you might have not had the chance to go on holiday.
In any case, August is a month of relaxation, of enjoyment of peaceful moments with our family and happy moments with friends. It is a month when our free time tends to be more than during any other month in the year. This free time can be used for entertainment.
Homo Digitalis does not have time to rest and relax, since an organization which focuses on the protection of human rights must be alert all year long and preserve the values, to which it is dedicated to. You will learn more on our activity in the coming days.
Notably, our experience has taught us that due to summer relaxation, this time of the year is used on purpose by the governments to act or adopt important legislation. Therefore, August is one more working month.
However, the human body needs moments of relaxation in order for it to be strong and human brain needs moments of creative thought, without being limited by everyday stress and pressure.
Thus, Homo Digitalis would like to suggest that you use the moments of leisure this August to start understanding more on the human rights issues arising from the use of the Internet and new technologies.
Let us proceed to proposals related to literature, cinema, comics and video games, so that young and old can receive important stimulus through entertainment. The following suggestions are indicative and do not illustrate the whole artwork. Moreover, Homo Digitalis neither has any economic interest from these suggestions nor has personal relations with any copyright owner.
Video games
Data dealer (2013): This game was created by activists and has as a main goal to illustrate through parody and humour the dangerous world we live in. The player becomes a data dealer, who trades them with every kind of recipients. In this way, the game transmits a message regarding the monitoring of a contemporary Internet user and its impact on the user’s choices and life. The game is available here.
VPRO & Studio Moniker, “Clickclickclick.click” (2016): This game is just one simple website. With the particularity that this website describes thoroughly the monitoring you are subject to every time you use the Internet. The place on which your cursor is moving, the time for which you remained inactive, the number of the websites you have visited in the past and your data, are communicated to you through a web voice (open your speakers). An experiment directed to raising your awareness. You can try it here.
Joint Research Centre (JCR) – European Commission, “Cyber Chronix” (2018): This game was created by the European Commission and its aim is to familiarize the public with the provisions of the General Data Protection Regulation (GDPR). It is available in English, French and Italian. It tells a story, taking place light years away from the Earth. There, the heroes are trying to reach an event. Their path is full of obstacles related to the protection of personal data, which the player has to surpass. The game is available here.
Literature
Aldous Huxley, “Brave New World” (1932): One of the most beloved books and one of the most well-known in this list. The book describes a future society, where human feelings have disappeared. Human beings are classified in categories from the moment of their birth, which occurs in an artificial way. The creators of this world implant to every human certain ideas depending on the social class he/she belongs to, while humans who demonstrate some kind of consciousness are drugged. Truth is lost in an ocean of fake news, human are mundane existences and enjoyment rules the brain.
George Orwell, “1984” (1949): A classic book. If you have not read it, you should do so this summer. The book describes the story of a hero, living in a country with an authoritarian regime. All the citizens are under constant surveillance under very pressing conditions. Unlimited rule, subjugation and deprivation of information prevail, while privacy is non existent.
Ira Levin, “This Perfect Day” (1970): This story takes place in an apparently ideal globalized society, the most fundamental characteristic of which is uniformity. All nations of the planet have merged in one, while otherness in not acceptable. The population is drugged in order to remain obedient, while a central computer has been programmed to keep under its control any human action.
Neal Stephenson, “Cryptonomicon” (1999): This book includes an impressive number of technical information. It is divided in two stories, taking place on a different point in time. The first story concerns cryptographers during World War II, who decrypt and transmit fake news. The second one occurs in the 1990s; a team of experts in encryption, telecommunications and computer systems tries to create an anonymous network for transactions of digital currency and circulation of information.
Dave Eggers, “The Cyrcle” (2013): This book’s heroine is the young May, who is employed by the Cyrcle, the most powerful Internet company worldwide. The Cyrcle uses its own platform through which, its users exchange money, complete their banking transactions and socialize. The Cyrcle constantly develops new technologies, among which a camera which everyone can carry with him and record everything live. Soon, transparency becomes the most important value and the solution to every problem, while privacy is left aside.
David Shafer, “Whiskey Tango Foxtrot” (2014): This book describes events from the lives of three different persons. They have nothing in common, until the moment they are called to join other activists to fight against an anti-democratic team of people, who serve great interests and strive for the privatization of all information.
Yuval Noah Harari, “Homo Deus: A brief History of Tomorrow” (2016): The author examines the form of the world and the human of the future, based on personal conclusions, but also common assumptions and lessons learned through history, philosophy, sociology and many other scientific fields.
Comics
Brian K. Vaughan, Marcos Martin, Muntsa Vicente, “The Private Eye” (2013-2015): What can someone say for these comics series? Exceptional creators, who have been linked with famous comics creations (Ex Machina, Saga, Daredevil, Amazing Spider-man) transfer the reader in an extremely particular future society. There, because of the fact that in the past the personal data of all people had leaked, thus shuttering the notion of privacy, the Internet is not used anymore, people come out of their houses only in carnival costumes, while the media play the role of police.
Brian K. Vaughan, Steve Skroce, Matt Hollingsworth, “We Stand on Guard” (2015-2016): This comic talks about the adventures of a group of Canadian citizens in 2112. This group is trying to protect their society from the US, which is a tremendously advanced State in terms of technology.
EDRi, “Digital Defenders vs Data Intruders” (2016): EDRi constitutes an umbrella under which all NGOs, which focus on the protection of digital rights in Europe and globally, are united. In the context of raising children’s awareness, it published the comic “Digital Defenders vs Data Intruders”. In the comic the Digital Defenders will show you some tricks and will share some advice to protect yourself on the Internet and will teach you “Web self-defense” to fight the Data Intruders.
Rick Remender, Sean Murphy, Matt Hollingsworth, “Tokyo Ghost” (2015-2017): This story takes place in Los Angeles in the year 2089. There, people live in a society, which drives them to addiction to technology and entertainment. Internet access has a significant impact, since every activity is monitored by hackers.
Cinema and TV series
Francis Ford Coppola, “The Conversation” (1974): The hero specializes in surveillance missions. A past incident though haunts every new task he assumes. This will also happen when a businessman asks him to watch two of his employees.
Peter Weir, “The Truman Show” (1998): Truman is the main hero; his life is being transmitted 24 hours per day worldwide, without him being aware of this fact. He lives in an artificial town, inhabited by actors, and fears to travel outside its boundaries and discover the real world.
Stephen Spielberg, “Minority Report” (2002): Based on the book by Philip K. Dick under the same title (1956), the movie describes technological evolution in year 2054, when murders are predicted before they are committed and the “perpetrators” get arrested before they commit a crime. What will happen when the director of this project will become the target of his own program?
Florian Henckel von Donnersmarck, “Das Leben der Anderen” (The Lives of Others, 2006): The movie tells the story of a man, who is a spy in Eastern Berlin 1984. There, the Stasi spies watch the citizens. The hero will adopt a different approach towards a writer, whom he is assigned to watch.
Charlie Brooker, “Black Mirror” (2011-today): This series consists of self-contained episodes, which describe stories occuring in the not so distant future, where new technologies have gained unpredictable growth.
Sam Esmail, “Mr. Robot” (2015-today): The series describes Elliot’s life, who is a computer programmer and hacker. His everyday life changes unexpectedly when he becomes member to a team of hackers led by Mr. Robot. The goal of the team is to destroy the giant corporation E-Corp.
Alex Garland, “Ex machina” (2015): The movie describes an innovative experiment; a programmer will have to spend a few days isolated with his boss, a successful inventor and businessman, in the latter’s villa. A robot with Artificial Intelligence, the latest invention of the talented inventor, seems to be the object of the experiment.
This brings us to the end of the suggested artwork. We really hope that you invest some of your time in one of them and take some stimulus from it. Please remember, though, that human rights challenges arising from new technologies, are not fictionary, but real.
Therefore, we call you to devote some time to our website as well. Here you can find content with which we pose concerns and inform the public on our activities, as well as the ongoing situation.
Take a look at our articles, written by our members and partners, the latest news, concerning current affairs and our activity, as well as the jurisprudence concerning digital rights.
You can always contact us to express your concerns and learn more on Homo Digitalis. Please keep in mind that our team is open to new members, who are interested in the protection of human rights in the contemporary digital era.

Connecting or cutting the chain?
The European Union has to face its choices
By Stefanos Vitoratos
All of us who are somehow concerned with technology, have undoubtedly faced the term “Blockchain” recently. Permitting the distribution of information, but not its copying, blockchain has started to support the backbone of a new form of revolution of information.
Although we got acquainted with blockchain mostly through Bitcoin, it is applicable beyond cryptocurrency.
Energy networks, the health sector, the banking sector, supply chains, transports, education, industry and the public sector are only some of the sectors, on which the application of blockchain is becoming examined on a pilot basis.
Blockchain redefines the role of faith in transactions and in this way it makes intermediaries less necessary.
What is the view of the European Union? Will it become part of this chain? Let us start from the beginning.
What does Blockchain mean?
This technology is based on the notion of the simultaneous creation and sharing of information. This logic is that of a digital file; let us think of something like a ledger. Every user records a transaction and then another one, thus slowly creating a record block. Every new record block is daisy-chained with the previous one, thus creating a blockchain.
Processing this model is by default decentralized, since every user who confirms the previous records and adds a new one, acts from his own computer, while the chain is common to all participants, since all of them save a copy for processing.
The faith of the transactors is based on an algorithmic relation-confirmation, rather than the traditional protection offered by a third person, which is theoretically trustworthy, such as a bank. Therefore, to put it briefly, blockchain is a cryptographically secured transaction file, which functions without a centralized authority interfering.
The difference to what we already know is that blockchain’s database is not saved centrally. The files kept are public and data are always verifiable because of the uninterrupted chain of records, hosted by millions of computers at the same time. Therefore, no block of the chain can be destroyed or amended, since such an action would require the use of tremendous computer power, capable of beating the whole network of the connected users.
Public access to blockchain safeguards transparency in transactions and diffusion of information. In the same context, the need for intermediaries, who augment the costs, disappears, since all the information related to the transaction are encrypted in the blockchain.
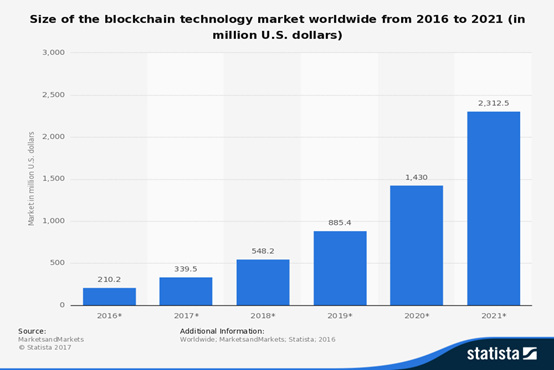 Evolution of the blockchain technology market in $, Source: Statista
Evolution of the blockchain technology market in $, Source: Statista
Blockchain and human rights
As already mentioned, blockchain as we got to know it through cryptocurrency, as well as the rationale of this technology can enhance human rights protection. Think of a world where each information is public and constantly verified. Imagine how transparency could be endorsed if, for instance, the pharmaceutical supplies of hospitals, were stored in blockchain.
It is indicative that some first attempts have initiated. The UN World Food Programme (WFP), in order to alleviate the refugee crisis, in 2017 provided more than 10,000 Syrian refugees a sum in cryptocurrency, which they could use only to buy food.
The reason why blockchain was selected as a means for sharing was that the refugees, being displaced, neither had access to bank accounts nor had the opportunity to open an account rapidly in the new country where they were installed. Thus, an electronic purse was opened for everyone and the money was deposited there.
Therefore, not only did they have access to their account from anywhere in the world, but also money was saved; money which would have been paid to bank commissions for wire transfers.
Where does the EU stand?
The European Union made a step towards claiming the role of the world leader in the fourth Industrial Revolution -as it is called- through adopting a resolution for blockchain technology on May 16, 2018.
The Committee for Industry, Power and Technology of the European Parliament voted for the resolution (with 52 votes in favour, 1 against), in an initiative by the Greek Member of the European Parliament, Eva Kaili. This was the first time that an institutional organ, such as the European Parliament, discussed the potential form of a regulatory framework for the new decentralized technologies, such as blockchain.
The aim is that the relationship, which is being cultivated through this resolution, becomes the vehicle for cooperation of the Member States. In particular, the exchange of experience and expertise in technical and regulatory fields will prepare the planning of european applications of the blockchain technology in favour of the public and private sector, which will ultimately be in favour of the European citizens.
The question is how can blockchain technology comply with the GDPR, which was adopted to protect the data of the users from central entities. What is not properly answered is what happens with decentralized technology.
As mentioned above, transactions in blockchain are unchangeable. Neither can the transactions change, nor can the data be deleted, since this will “break the chain” in a way, rendering the whole blockchain non functional. At the time, the GDPR prohibits the potential storing of personal data in data chain.
Making a brief flashback, the GDPR was proposed for the first time by the European Commission in 2012 and focused mainly on cloud computing and social media.
More specifically, the GDPR, in its Article 17 introduces the “right to be forgotten”, meaning the right of persons to request the erasure of their data, thus requiring that there will be central servers which will be able to “erase” this data.
The Regulation was drafted without taking into account the blockchain technology, which was not commonly known -even as a word. Therefore, there arises an important question on whether blockchain technology can function properly, without violating the EU legislation, since a fundamental -and at the same time revolutionary- element of blockchain is that data cannot be deleted. In the way that the GDPR has been drafted, it seems that we cannot store personal data directly in the blockchain, since in the words of the GDPR these data “will not be erasable”.
At this point it must be noted that we refer to public chains, not private ones, such as the ones that a company can use for internal reasons; the latter can be created from scratch with a provision of limited/locked access by the public.
Looking into the future
When the European policy makers were discussing and finalizing the GDPR, the blockchain was not in the radar of most people.
What is obvious is that in the future we will need a flexible governance framework, which will permit us to understand the advantages of data and technology.
Governments should cooperate with society, academics and the private sector for policy to conform with such a dynamic procedure, as technology.
With the new initiatives it seems that the legislator understands that blockchain technology is able to create a system structure, in which existing business models could go forward and design a new value chain.
Through the resolution, new roads of regulatory and legal certainty for investing vehicles based on blockchain are opened, confronting serious cases of fraud and unreliability.
The very promising blockchain technology is expected to create a radically innovative ambience for the neuralgic industries and the operational structure of the public sector, while also changing our lives as consumers and citizens in general.Undoubtedly, it seems like a very complex technology. But, let us keep in mind that it constitutes the most feasible, from a technical perspective, attempt for liberation and democratization of the global economic transactions. We expect the developments and wait to see how will the EU comply with its choices.
Reddit was hacked
Both people and the State can become victims of a cyber-attack. Regardless of the security measures everyone uses, there will always be a team of talented hackers, which might be able to take advantage of some human mistake or a weakness in the installed cybersecurity systems and successfully hack them after persistent efforts.
The latest victim of such a cyber-attack is the Internet platform “Reddit”, which is one of the most well-known platforms of informations exchange in the Internet, having hundreds millions users.
According to the official press release by the company, published yesterday (01.08.2018), some hackers got access to the computer systems of the platform and thus, gained access to users’ personal data, including e-mail accounts, encrypted passwords and personal messages exchanged through the platform during the first years of its existence (2005-2007).
Additionally, the intruder gained access to recent files (dated form 3 to 17 June 2018), which the company sent as recommended material to its users. These files contain the users’ username, as well as the e-mail address associated with these usernames, while the recommended material is based on popular content of the platform and on content which is supposed to fit the users’ preferences.
The cyber-attack allegedly occurred quite recently, probably between 14 and 18 June 2018. In its official press release, Reddit states that it is running an investigation since 19 June 2018 to see the full range of the intrusion. Moreover, it has reported the attack to the responsible authorities and has contacted the users, who have been influenced by this attack, through e-mail.
This news reminds us that not only the owners of computer systems are the victims of cyber-attacks, but also the data subjects of the data contained in these computer systems.
The protection of digital rights, such as privacy, protection of personal data and the freedom of online expression and information, is intrinsically linked to the security of the computer systems and the adoption of the pertinent techniques or organizational measures, which guarantee the requisite protection.
You can read the official press release by Reddit here.

Evidence and Cloud computing
By Kostas Pratikakis
What is cloud computing? It is quite possible that you have heard someone say that he/she saves photos, documents and other data on “cloud” to transfer them between devices.
This “cloud” is nothing more than databases, service platforms and software, which are not really in your device.
Thanks to the Internet, a cloud service user -that being you, companies or the State- can use his/her device to have access to these databases, service platforms and software, which might be hundreds or thousands kilometres away. Well-known examples of cloudcomputing are: Microsoft Office 365, Salesforce, Facebook, Youtube, Instagram, Google Drive, Dropbox, Gmail, Yahoo Mail, Spotify, Vimeo, Twitter, etc.
Cloud computing definitely creates unlimited opportunities. However, it also creates many issues. For instance, a person residing in Greece can save his data in a platform belonging to a US company; the databases of this company might be in one or more States, such as Australia or Japan. All these different States can cause a headache in the event that a search regarding a serious crime takes place.
In this context, the Council of Europe announced in June 2017 the drafting of new additional protocol to the Convention on Cybercrime (Budapest Convention), concerning cloud computing.
The new additional protocol, which is expected to be finalized by the end of 2019, aims at the successful exchange of information and mutual court assistance, providing for the cooperation with the service providers and the demarcation of the existing practices of transboundary access to data.
The main purpose of this venture is the reinforcement of the protection of human rights in the context of certain criminal proceedings, which require access to certain data.
On July 2018, the “Octopus Conference 2018” of the Council of Europe took place. This conference aims at enhancing cooperation against cybercrime. This year, the centre of discussion was the important challenges, which arise from the adoption of an additional protocol to the Budapest Convention concerning cloud computing.
Experts on cybercrime, States delegates, academics and civil society representatives, such as European Digital Rights (EDRi) and Electronic Frontier Foundation (EFF), discussed their views and concerns related to the new protocol.
Before we describe the challenges which arise, let us begin with explaining in a few words the Budapest Convention and the existing additional protocol to it.
The Budapest Convention and the existing Additional Protocol to it on the Criminalization of acts of racist and xenophobic nature through computer systems
As criminal activities increasingly use and on the same time influence the electronic systems for data proceeding, there was a need for new criminal provisions to confront this challenge. Therefore, the Council of Europe adopted the Convention on Cybercrime (Budapest Convention), which constitutes a binding international legal act which concerns crimes through or against electronic networks. The existing Additional Protocol to the Budapest Convention concerns the criminalization of acts of racist and xenophobic nature committed through computer systems.
Although Greece signed the Budapest Convention and the Additional Protocol to it in 2001 and 2003 respectively, it demonstrated negligence once more and finally ratified them with Law 4411 in 2016, thus harmonizing the Greek legislation with their provisions and changing significantly the Criminal Code.
The Budapest Convention permits the accession of third countries, non-members to the Council of Europe. It remains the most significant international convention concerning violations of the law through the Internet or other networks of information and its text has been ratified by third countries, non-members to the Council of Europe, such as USA, Argentina, Australia, Chile, Canada, Japan, Israel, etc.
The Convention requires that the States parties to it update and harmonize their criminal legislation on piracy and other security systems violations, including the violation of copyrights, fraud though computer systems, child pornography and other illegal activities in cyberspace.
It also provides for procedural powers concern the search of computer networks and the monitoring of communications in the context of confronting cybercrime. It also promotes efficient international cooperation.
Although the Convention is not a means for the promotion of the right to the protection of personal data, it criminalizes activities which may violate the right in question. It also requires from the parties to adopt legal measures, which will permit their national authorities to monitor traffic and content data. Finally, it obliges the parties to it to provide for adequate protection of the fundamental rights and freedoms, including those protected under the ECHR, when implementing the Convention.
The Additional Protocol to the Budapest Convention includes the circulation of xenophobic and racist content through the Internet within the scope of the Convention. Moreover, it provides for the use of procedural means to be used against these violations.
This Additional Protocol acknowledges the need to safeguard a balance between freedom of expression and the ceasure of acts of racist and xenophobic nature. Finally, international cooperation regarding the alleviation of cybercrime related to racism and xenophobia is promoted.
Potential challenges arising from the new Additional Protocol to the Budapest Convention on the effective exchange of information and the mutual court assistance in the context of cloud computing
Now that we briefly discussed the scope of the Budapest Convention and the existing Additional Protocol to it, we will move forward to describe the challenges, which might arise from the new Additional Protocol.
This new Additional Protocol, as already mentioned, is expected to be finalized by the end of 2019. It will concern the effective exchange of information and the mutual court assistance regarding certain criminal proceedings, which require access to certain data in the context of cloud computing.
For the Internet and cloud computing services to be a place in which each and everyone of us will be able to enjoy his/her rights, it is necessary to enact certain safeguards when the State authorities, which are responsible for enforcing the law, exchange information and mutually cooperate in the context of transboundary criminal proceedings.
The discussions which took place during “Octopus Conference 2018” underlined important potential challenges, which might arise from the new Additional Protocol, if necessary safeguards are not adopted.
It must be noted that particular attention was paid to the necessity of restructuring mutual court assistance between two or more States with the objective to collect and exchange information in an endeavour to enforce the provisions of the new Additional Protocol in regards to certain transboundary criminal investigations or proceedings.
Furthermore, it is necessary to ensure that national legislation of third countries will be harmonized to the high level of protection, recognized by the European Court of Human Rights. Both the legislators and the law enforcement authorities of these third States should respect and abide by the legal principles and values reflected in the legislation and jurisprudence of the Council of Europe regarding the protection of human rights.
Only in this way will the authorities have access to evidence, coming from cloud computing services, with the necessary prerequisites being followed; this way, the interference will be proportional the human rights and freedoms of Internet users will be protected.
You can learn more by watching a short video by the Council of Europe with statements of some of the participants to “Octopus Conference 2018”, by clicking here.

It is raining technological advancements
Artificial Intelligence is constantly evolving. What can we do to keep it under our control?
By Konstantinos Kakavoulis
In Saudi Arabia it is believed that it scarcely rains. The truth is that it rains quite often. However, due to high temperatures, the raindrops evaporate before they reach the ground and people become aware of them. People feel the rain only on the rare occasions, when it rains a lot. On these occasions, there is also frequent flooding.

Picture from flooding in Saudi Arabia. Source: SahilOnline
The evolution of Artificial Intelligence does not differ much from the example of the rain in Saudi Arabia. We tend to believe that Artificial Intelligence evolves rarely. In reality, it is constantly evolving.
The small improvements which are achieved daily do not reach us. Only on the occasion of an important achievement we realize that Artificial Intelligence is indeed advancing. These big technological “booms” frighten us, like heavy rainfalls frighten the Saudi Arabians.
We are not used to them, because they rarely occur. If we paid more importance to the small progress achieved daily, we would not be that astonished. We would understand that technological achievements are the logical consequences of such progress.
The question is: what can we do to avoid the “flooding”, which might stem from the evolution of Artificial Intelligence?
Stuart Russel, one of the most prominent researchers in the field of Artificial Intelligence, had noted: “Let us assume that there is 10% possibility that we achieve Super Intelligence within the next 50 years. Shouldn’t we start working now, so that we make sure that we will be able to hold Super Intelligence within our control?”
Indeed, there is no reason for us to wait until the “floods” come to face their consequences. We can create infrastructure, which will protect us. This infrastructure is nothing else than a regulatory framework, which will not restrict technological progress, but will protect the people.
Artificial Intelligence does not advance as fast as we might fear. The inventors of Artificial Intelligence as we know it today, believed that within 10 years they would be able to create a computer which would be able to beat a world-class chess player. This took 40 years to happen.
They also thought that in 10 years they would be able to create a computer, which would be able to understand human speech and respond to it in any existing human language. They believed this back in 1956. Until today it has not been fully achieved, although translating applications are constantly evolving.
Finally, in the field of Computer Vision, the experts estimated that teaching a computer program to classify photos according to their content was an appropriate summer project for a Master student.
However, 62 years later, although Computer Vision constitutes one of the biggest success stories in Artificial Intelligence, this task has not been adequately fulfilled.
Of course, there are examples of achievements of Artificial Intelligence which have been accomplished a lot earlier than expected. For instance, two years ago the experts estimated that for a computer to be able to beat a champion of the board game Go, 10 more years would be needed. Nevertheless, last year the AlphaGo computer managed to beat the Go world champion in all of their three encounters. The achievement of AlphaGo opens up new opportunities for Artificial Intelligence but is the exception rather than the rule.
Therefore, we may have more time than we believe to get adequately prepared for the progress in Artificial Intelligence. We might neither know what the future holds nor be able to predict it. However, we should not demonize the progress of Artificial Intelligence under any circumstances.
Scientists often bear responsibility for that; they often discourage the public from getting involved with Artificial Intelligence topics, claiming that since they do not know how Artificial Intelligence works, their opinion should not be taken into account. The progress in Artificial Intelligence influence the lives of us all. We should all participate in the discussion on their use. The first step for this to get informed.
If the inhabitants of Saudi Arabia could see the raindrops, before they evaporated, the might have taken more appropriate safeguards to get protected from the floods. If we know that it is “raining” technological advancements, it is worth following them; this way we can take all the appropriate measures on time to keep the situation under our control.
Under no occasion should we try to predict or criticize the progress in Artificial Intelligence. When we try to do so without possessing the adequate knowledge, it is reasonable that scientists do not seriously taken into account our opinion.
Through the State and the pertinent authorities we should be able to explain to the scientists which of the methods they use are socially acceptable and which are not. We should care about the results of their research -not the results we deem possible, but the real results- and see if we consider them acceptable. The State should legislate on this direction, taking into account the public opinion and the ethics it stands for.

From imagination to reality and back to imagination
by Nikos Giannaros*
The history of Artificial Intelligence as something achievable coincides with the history of computer evolution. The first theories for the development of systems with Artificial Intelligence capabilities came out back in the 1950s. Only man possesses such capabilities and could be able to teach a computer system to take autonomous decision and act as a thoughtful being.
The initially theoretical approach of Artificial Intelligence was directed to the creation of the necessary tools for a computer to act like the human brain.
These tools were based on logic and semantics, which constitute the prominent tools with which the human brain thinks and acts depending on the stimulus it receives. In this context, there have been efforts to standardize logical rules and correlations, which led to the creation of tools such as Logical Programming.
The basis of Logical Programming is the provision of basic entities to a computer system, so that with the application of a procedure of creation of logical conclusions, the system will be able to take decisions, imitating the procedure followed by the human brain.
This approach is based on the “up to down” logic. The system is supplied with the total of the requisite knowledge and the endeavour focuses on the way with which it will manage and combine properly this knowledge.
It soon became obvious that this kind of approach can offer limited practical solutions, because are not harmonized with the fundamental functional principles of a computer. The computer in its core is a machine, which can process mathematical calculations with great speed. There was a need for an approach which would work the other way round; the “down to up” approach.
This approach focuses on the endeavour to modelize a problem of -apparently- logic to a pure mathematical problem. A mathematical problem can be solved by using certain procedures with clearly determined steps, on which the computer is highly efficient. The outcome is also easy to classify, to categorize and be interpreted by the computer.
This finding led to the evolution of Machine Learning since the 1980s. This approach aims at modelizing through math certain human actions, so that a computer can conclude to the same result.
The most notable of these problems include the recognition of voice and image, processing of a human language into written form, robotics, forecasting, etc. Machine Learning uses the power of computers, their incomparable calculating capability, to make good use of big volumes of data to learn successfully to take decisions such as the ones taken by humans.
The models used are based on the way of functioning of the human organism (neuronic networks, genetic algorithms), of other living organisms (particle swarm optimisation, ant colony optimisation, bees algorithm), on applications of probability theory and of other field of Mathematics.
The various approaches which result to tangible algorithms, which can be carried out be a computer, that does not need any special structure or design, was revolutionary for Machine Learning.
Machine Learning consists of 3 main fields:
– Supervised Learning;
– Unsupervised Learning and
– Reinforcement Learning, which constitutes a combination of the other two.
The notion of Supervised Learning is the simplest of the three; the computer is provided with an appropriate training data set to get trained on the work which we want to assign to it.
The most common example for Supervised Learning is the provision of photos of men and women to a computer; on the photos there is a tag clarifying whether the photo depicts a man or a woman. A successful training will result in the computer being able to recognize the sex of the person depicted in any photo, since it will have been trained in classifying the data it receives.
In order to achieve this, the computer is provided with many features for every sex. Therefore, it becomes able to decide upon the sex of the person depicted in any photo with remarkable precision, based on the features appearing on each photo. This procedure requires that the determination and standardization of the features has been made by a human, specialized on the topic, before the training begins.
The feature extraction and selection constitutes a keystone for the successful application of Supervised Learning and has ended up being a whole, autonomous field.
Supervised Learning has long got away from the experimental and theoretical sphere and is used in commercial applications of voice, face and handwriting recognition, as well as in more specialized applications depending on the applicable field, such as customer segmentation, recommender systems/collaborative filtering, stock market prediction, preventive maintenance, etc.
Furthermore, with the appearance of Deep Learning, a sub-field of Supervised Learning, the feature extraction and selection can now be carried out by the computer itself; this results in further diminishing human intervention in the procedure. In the example of photo classification, the computer could, after having processed the photos it used as a training set, decide that lip shape is a more vital characteristic for the classification than eye shape and therefore give more importance to this feature.
In Unsupervised Learning, the computer does not first come through a training stage with use of data with determined features, in which the intended result is known. On the contrary, it is self-trained based on unknown data, which it can process.
The computer’s potential to work without first having been provided with knowledge, makes Unsupervised Learning look like extremely exotic and part of science fiction.
The truth is that in this case also, the applicable models make use of the computer’s ability to compare things and decide the level of similarity between them.
The structural difference with Supervised Learning is that the computer does not “know” the qualitative interpretation of the produced result. In contradiction to the example of Supervised Learning, an algorithm of Unsupervised Learning, which can classify photos of people according to their sex, can do so with equal rates of success, but does not know which category belongs to “man” and which to “woman”.
Unsupervised Learning has also many commercial applications. These are often in fields like the ones of Supervised Learning. However, as the power of computer systems is rapidly evolving, the ability of a system to be self-trained will replace the onerous human preliminary work with one more automated procedure. A perfect example for Unsupervised Learning is the ability of a computer to classify vegetables and fruits according to their shape, their size and their colour, without having first been trained to do so.
Finally, Reinforcement Learning constitutes a combination of the other two methods and is mostly used in robotics. The robot tries to carry out the instructions with which it has been trained in the best possible way, but on the same time enjoys some freedom to decide to deviate from these instructions. This might result in an even better result than the one already achieved.
Applications of Reinforcement Learning, such as self-driving cars, are in the anteroom of commercial application. Moreover, the various robots, which are used as human assistants, apply successfully the model of Reinforcement Learning, since their behaviour evolves based on the various stimulus they receive from different people with who they discuss.
It is obvious that Machine Learning is already here. It constitutes a reality and part of our everyday lives and not a science fiction plot. Many projects which seem evident, such as the recognition of the plate of our car in the airport parking, the digital help assistants in the phone centre of banks, which recognize our voice instructions, the applications of recognition of the music track we listen to (such as Shazam), the advertisements and the suggested posts in social media (such as Facebook, which combines the posts we open with the history of our search engine to show us relevant advertisements), the security applications, which activate video recording when a man approaches the door of a shop out of working hours, constitute a reality thanks to Machine Learning.
The fact that it is impossible that a person carries out the same tasks in the same time, justifies the label of “Artificial Intelligence” that is given to such applications.
On the other hand, the fact that computers carry out these tasks mechanically, without the result having any meaningful result for them and without them deviating from the way they carry out a task if they continue receiving the same stimulus, means that Machine Learning is still far from becoming real Artificial Intelligence; there are many unknown steps until this happens.
Computers carry out the task they have been assigned to without judgement and without feelings, with no possibility to deviate from what they have been designed to do. They can carry out the the tasks assigned to them in an increasingly better fashion, but they are not able to “start a revolution” and change their way of operation. A future in which humans and machines will be equal is definitely far away. The reality of Machine Learning though, is here.
*Nikos Giannaros is an Electric and Computer Engineer. He specializes in Artificial Intelligence and Machine Learning. He is interested in the sociopolitical impingements of technology.