
Ignoring data analysis inferences
Written by Vasilis Vasilopoulos, DPO of ERT
Checking your credit card purchases you seem to be consuming a lot of snack, alcohol and fast food, and only a small part of your purchases in healthy foods such as vegetables, proteins and fruits. The fatty food that the machine can understand you buy is registered on the screen of your insurer, who adversely changes the terms of your contract.
The insurance company has been notified of your low risk of heart disease, but the life you lead, according to what you say in your Instagram posts, probably puts you in the high risk groups, as you always keep a cigarette and a glass of alcohol while you are with friends at a bar. The insurer will not let his company risk with you.
If you think that all the above are scripts written for Netflix movies, then what happens now with surveillance capitalism can be easily explained. Because these scenarios really happen! In fact, your follow-up continues in every venue, in any online environment or smart device. If you are indifferent about your personal data, it is even worse to ignore the fact that those who collect them earn money from coming to conclusions from them.
Understanding the knowledge gap is terrifying. As every Bank assesses your creditworthiness to identify a bad payer who makes a comfortable life avoiding debt repayment, insurance companies also want to know, before and after signing a contract with you, anything that relates to your health and the quality of life you live. On the other hand recruiters would like to know everything about you and your social life. They would like to find out if you are in bed with a fever or at some recreation area and you deceived your employer.
The knowledge gap that can be defined as a lack of understanding of the ability of the algorithm to draw conclusions, which reduce losses or increase profits to the surveillant, is due to the unceasing rate of digital tools and the one-way convenience, the charm of the comfort zone in work life, consumption of goods and our social relations.
Even worse, you cannot understand how you will lose something important, if the unknown who collects your data gain maximum profit. In other words, you cannot understand that you have sold your self-determination right to do what you want, enjoying a temporary sense of comfort and ease. For example, at the first level of lack of understanding algorithmic conclusions, you behave to your data as if they were worthless. On the second level, you realize that the algorithmic conclusion made from spying on your life significantly adds value to the one who took your data. Additionally, you are not sure if what you provided is a commodity that you exchanged with a free service of convenience, or a currency with which you bought luxury service for your everyday life.
There are tremendous questions you need to have answers to. To whom your data belong? Is data a commodity or a currency? Can be disconnected from yourself or are genetic features that define and allow you to decide on your life?
You can just do two evaluation tests yourself and you will get the answers that concern you:
-If you did not take up credit card convenience or if you did not follow the moments of entertainment and consumption of luxury goods, would you be losing or gaining from some algorithmic processing or more generally in your life?
-If you want to make yourself more secure of your privacy or hide from surveillance and the possible damage to your rights and freedoms, would this be a violent punishment or joy of celebrity since you reveal aspects of your personality, your relationships and behavior?

Homo Digitalis in Kathimerini Sunday Edition
Today, February 10, 2019, in the Kathimerini Sunday edition, an interview with Giannis Kouvakis, legal advisor to noyb.eu, is featured regarding the 50 million euro fine imposed by the French Data Protection Authority on Google for GDPR violations following their actions.
In the same column, statements from Eleftherios Chelioudakis, Secretary of Homo Digitalis, are also featured, where he discusses the state of digital rights in Greece

Facebook and Google know almost everything about you!
Written by Nikodimos Kallideris
“Everyone is guilty of something or has something to conceal. One must only look hard enough to find what that is” (Aleksandr Solzhenitsyn).
Frankly, did you know that according to statistical surveys the account holders on Facebook are more than five million in Greece? Respectively, active accounts on Google are even numerous with intensive growth rates…
Have you noticed that the use of the extremely useful and responsive accommodating services of both platforms is offered without any payment? They are totally free -or not? After all, it seems that they are not! The two platforms, like many others, “fed” on your personal data, that you provide them with during their use. Our personal data have been named the “the oil of the 21st century”. Of course, you have previously given your consent to provide them to the platforms; but really, are you aware of the volume of your personal data, that are stored in their servers?
Let us first look at Facebook:
As a data subject, you have the right to access (GDPR Article 15) according to which you can make a request and get in return from the company (the data controller) everything they have stored that concerns you. You can exercise the right to access following the link: https://www.facebook.com/help/1701730696756992
Having submitted the request and anticipated the necessary time for its processing, you will receive a file, in which you will find: all personal written or audio messages you have sent, the exact time, the place and the device with which you were connected each time in your account, the applications used, your photos and videos and there is no end… All these from the outset of your account’s creation until today!
So, let us come now to Google:
If you have turned on GPS on your smartphone, Google records the history of every location you have been to, in conjunction with the period you stayed at each of them and the duration of the transition from one location to the other. Do you want to find this out on your own? Follow the link: https://www.google.com/maps/timeline?pb
You can also find easily your whole search history from every device even if you have deleted it (https://myactivity.google.com/myactivity) but also your search history on YouTube (https://www.youtube.com/feed/history/search_history).
Seek now to download on your computer every stored data by Google (https://takeout.google.com/settings/takeout). Do not be surprised by the volume of the file, which for that reason will may need several hours to be sent. It is likely to be several gigabytes in size, always depending on the frequency and the type of services’ use. In the file, you will find everything; from the deleted e-mails up to your navigation history in every detail, your calendar, the events you attended, your photos, purchases you made from Google and many others… Besides that, if you are connected in various platforms through your Google account (log in with Google) many of your sensitive personal data are recorded unintentionally, such as the place you are staying at, you are studying or working, the number of your friends on Google Plus, your gender, your name or the languages you speak. Any movement you make on the Internet has left in clear and indelible lettering its digital footprint even if you are not able to remember it right now.
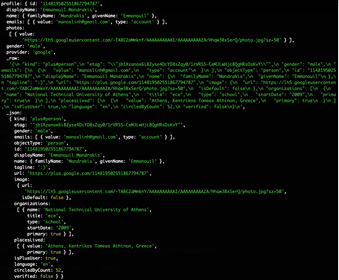
Photo shows the data that a platform of electronic orders learnt for Manos Mandrakis, member of Homo Digitalis, when he connected to it using his Google account.
Having followed the above steps, do you feel slightly numb or terrified? Not surprising at all! You might feel “digitally naked” and that an invisible power, such as Jeremy Bentham’s narratives, is constantly recording your moves and can make extraordinarily important conclusions from them. Against you or for your benefit? It depends on the incentives of your data’s holder. In any event, Facebook and Google possess information that you have never shared even with your family or your best friend.
Bear that in mind! The modern digital world of information offers you improbable facilities but also countless risks. Only you can protect yourself! And if you repeat the familiar and hazardous naive “I have nothing to hide” I would urge you to deepen on the saying written in the upper part of the article.

Guidelines by Homo Digitalis in the context of the European Data Protection Day
January 28 has been established as the European Data Protection Day by the Council of Europe. Information society and the increasing use of the Internet lead to the growth of our digital footprint. Personal data constitute an endless bone of contention for the companies which base their corporate model on them.
Which are the challenges and what can you do to protect your personal data? Homo Digitalis, in the context of the European Data Protection Day, created a short video with guidelines to help you prevent potential violations, as well as ways to react should you feel that your rights have been violated.
Watch the video and get informed through our website!

Homo Digitalis for the European Data Protection Day
January 28 has been established as the European Data Protection Day by the Council of Europe. The members of Homo Digitalis created a video explaining what do personal data mean for them.

The right to be forgotten
Written by Apollonia Ioannidou*
“What happens to the memory we do not recall? Can we preserve the past itself?’’ In these words, Proust, decades ago, described his anxiety about the things which are forgotten. Besides, it is undisputed that human memory is weak and cannot remember everything. Everyone suspects that there are things that we cannot recall: Even our own self is hiding in his experiences and cannot be solid and intact. The thymic memory is deeper than the man himself. It surpasses him. Besides, people by their very nature tend to forget; remembering is the exception rather than the rule.
In the short story “Funes, the Memorious” the great Argentine writer Jorge Luis Borges describes the tragic life of a person who never forgets anything, thus highlighting the decisive importance of the processes of oblivion for a healthy and balanced human life. It is precisely this gap that technological development has come to cover, by creating a website where information is kept intact erasing the process of oblivion. The right to be forgotten was adopted on the one hand in order to defend the protection and, on the other hand, to establish control over the personal data of individuals. Although there are cases where this right has been implemented, its exact content has not yet been clarified. In addition, it is a fact that this right also conflicts with other known and established rights, creating even greater need for its analysis and clarification.
What is the right to be forgotten?
The right to oblivion is defined as “the right not to refer to past events that belong to the past and are no longer relevant”. We would think that this right applies mainly to the mass media and is understood as the right of the person not to be subject to journalistic interest and commentary on past situations in his life. This, of course, is considered to be reasonable because the opposite would increase the difficulty of reintegrating the individual into society if, for example, they were using journalistic means for committing criminal offenses. This is not an absolute right; a fair balance must be found when there is a legitimate public interest in information. Of course, it is not clear when there is a reason for legitimate interest.
The example of HIV positive women
The case of HIV-positive women in April 2012 is remarkable. During massive checks conducted by the police, women were subject to forced HIV tests, accused of being prostitutes knowing that they have HIV and wanting to transmit the HIV virus to the alleged customers. At the same time, their photos and ID details were published, while it came out that they were HIV positive as well as the prosecution against them. This publication is alleged to have had a serious impact on the data subjects, perpetuated them permanently and potentially led to the suicide of some of them.
This data was made public because, as claimed, there was a legitimate public interest in information. Of course, it is remarkable that the publication, the continuous reproduction of the topic and the over-displaying of the photographs of the women brought the opposite results, as the men who had had sex with these women were not medically examined, fearing that they would also become targeted by the media. It therefore emerges that it is unclear whether and when there is indeed a public interest requirement requiring the publication of photographs and data to inform the public.
When it comes to the right to be forgotten, it is worth mentioning that in the international literature there is a variety of terms referring to this right, the right to forget and the right to be forgotten, the right to oblivion, or the right to delete.
The digital oblivion
By digital oblivion, we mean the right of individuals to stop the processing of their personal data, but also to delete them when they are not needed for legitimate purposes. The European Commission has recently requested clarification of the concept and made an initial effort to give its own (broad and vague) definition (above). Undoubtedly, this right means that personal information of a person must be irrevocably abolished. In 2008, Jonathan Zittrain also proposed a similar concept -called reputation bankruptcy- allowing people a “new start” on the Internet. It can be obvious that when a person withdraws its consent or expresses its wish to stop the processing of its personal data, the data must be irrevocably removed and removed from the data processor’s servers. However, this affair does not fit perfectly with the legal, economic and technical reality.
The GDPR includes detailed complicated provisions, which can cover a wide range of situations. The level of protection afforded to data subjects is also to be praised, especially as regards the rights of the data subject, such as the right to oblivion, as this will contribute to the further protection of such data sets that are so sensitive as to adversely affect life of the data subject. These rights, some of which are novel, will contribute in the long run not only to improving the level of data protection for the data subjects but also to a large extent to the provision of free flow of information to promote the trust of data subjects on their security and hence the greater ease of doing business across the EU.
*Apollonia Ioannidou holds a Bachelor from the Law School of the Aristotle University of Thessaloniki and a Master from Panteion University, Faculty of Public Administration, Law, Technology and Economy track. She is currently attending a second Master in the Faculty Business for Lawyers in Alba Business School.

An imaginary football story
By Konstantinos Kakavoulis
It is May and we are in the middle of spring in Barcelona.
It is 5 in the afternoon and the first locals have already appeared at Plaça del Sol to enjoy a cool beer after a day at work. As it is Monday, the stores are already closed. At Cafe del Sol, the only ones who do not seem to be tourists are three men who look pretty tanned by the sun – a sign that they started their excursions to Costa Brava early this year.
They are almost 45 years old, but they look younger. Manu, the wittiest of the company, immediately orders 3 frozen beers and one portion of patatas bravas. The conversation soon turns to last night’s local football derby between the worldwide reputed Barcelona and Espanyol, a very well-run team that does not have the shine of their fellow countrymen, but after yesterday’s victory they have become major league contesters.
The three friends had attended the stadium to watch the match. It was the first time after more or less a decade that the fans of the away team were allowed to enter the stadium alongside with the home fans. After a crowd disorder caused some very serious incidents, the Spanish federation had decided to forbid the movement of fans and so, for several years only the home team fans could watch the game in the stadium. Manu, Barcelona fan since he was a child, starts the discussion. “Your first goal starts with a clear foul in front of the referee. It should have never counted.”
“Yes, but the penalty he gave you after that was a clear dive. The defender never touched your player“ was Felipe’s, a Sevillian and warm supporter of any team playing against Barcelona, immediate response.
“It seemed that the referee never meant to give the final whistle of the match. He was expecting that you could equalize until the very last moment” adds Jordi, whose father was a legendary goalkeeper of Espanyol.
“In any case, it is a pity we could not get a picture of us three. We had so many years to hang out together in the stadium”, Felipe recalls.
“It is really unacceptable that this new law forbids a photo of 3 friends who managed to go to the stadium and spend a beautiful afternoon supporting their teams. I honestly cannot figure out why this is forbidden “.
“Come on, do not grumble, let’s take one now. Estelle asked me to send her a photo of us”, Manu suggests.
“Forget it, we cannot take any photo even here. They have brought this Miró sculpture in the square. If its visible in the picture, we cannot send it anywhere. “
“Well, are they insane?” Manu says with a red-faced face – maybe he was not that nervous, maybe he just turned red when he ate the last chilly potato.
“At least I will write a very nice article about our experience in the stadium,” says Felipe who works for a well-known online magazine.”
“Just be careful, do not put a picture of the match again. They will not let you upload it, like last time.”
“But who wants to read an article about a football match with no picture in it?”
“I would not read it, even if I knew you had written it.”
“But the first goal was a foul,” Manu says.
“Well, you can say whatever you want. This year’s championship is ours. “
“Will we get another round?”
*The above story is fictional. No elements beyond the site, patatas bravas and ongoing football debates in Barcelona’s squares for the two teams of the city are real.
A scenario banning the movement of fans in Spain, as in Greece, seems unlikely. Almost as improbable as Espanyol being league contesters alongside FC Barcelona, winning them in one of the last matches of La Liga.
The restrictions that the three friends discuss about the photos and the article for the match are not that fictional though. It is very likely that they will soon be part of our daily routine. Read more here.

Fake News on the Internet - Nature, Dangers and Troubleshooting
Written by Ioannis Ntokos
What is fake news?
Fake news is not a new phenomenon. According to Wikipedia, fake news is a form of gutter press or propaganda that consists of deliberate misinformation or farce propagating through the traditional press, media transmission or online social media. ” We notice, therefore, that fake news can be spread through a variety of communication methods. It is worth mentioning, for example, the spread of a rumor within closed, or even more widespread, social clusters over the last century (the so-called gossip, which was often based on rumors rather than on reality).
The main feature that has changed over fake news in the 21st century is the method by which they are spread. Beyond the “traditional” type, which is still used to create propaganda, modern media, mainly based on the use of the Internet for their operation, have been added to the list of ways in which untrue news appear to the average user. Newspapers, magazines and news agencies (especially the largest in scope) have acquired their own website, online channel, and electronic ‘forms’ to exploit the widespread growth of the internet. Access to these media has become very easy on the internet, with the latter being a source of information for millions of people around the world. According to a survey by Reuters Institute (2016), most residents in 26 countries surveyed are now more reliant on social media rather than the press to get informed.
Reference value at this point is the impressive but also worrying (as we shall see below) Chinese avant-garde in news broadcasting. The Xinhua Chinese press has designed and created the first news anchormen entirely based on Artificial Intelligence. This is undoubtedly an impressive achievement, but the risks of misinformation and fake news remain.
What are the implications and risks of spreading fake news over the Internet?
The first of the most damaging effects of fake news is of a legal nature, and it has to do with possible violations of rights to information and expression. These rights are enshrined in the European Convention on Human Rights, ECHR (Article 10), and constitutionally guaranteed in Greece under Articles 5a and 14 respectively. Based on these provisions, every Greek citizen must be able to be informed and express himself/herself, without restrictions (unless exceptions are allowed). The impact of fake news, in legal terms, at first glance, seems to be very important: this news misinforms the citizen, with the consequent violation of his/her fundamental rights. At first sight, therefore, the dissemination of such news is constitutionally forbidden in Greece. This prohibition applies to news broadcasted by any means, including the Internet. On a more practical level, fake news found in online environments can be harmful, given the way they become known and accessible to the general public. The means by which this news is transmitted (i.e. the Internet) helps: a) the ease of writing / authoring; b) the ease of their transmission (in which the recipient of such news can now play an active role, their distribution to more people through social networking platforms); and c) the difficulty of identifying the source of the news given the vast amount of information available on the internet.
What do all the above mean? Quite simply, the ease with which such news can reach an Internet user, coupled with the overwhelming – already available and new – information, makes their dissemination extremely easy. This ease grows sharply with the help of social media, offering an extremely effective channel of communication of such news with their ultimate recipient. Because of their ease of creation, they can be extremely persuasive and plausible. At the same time, this news is difficult to crosscheck and confirm because of the already large amount of information available on the Internet and the difficulty of filtering them from the average user of online media.
Undoubtedly, the most damaging effect of fake news is the spreading of their (untrue) content. The person targeted by such publications, news and content generally faces the dangers arising from the inducements of those who disseminate them. Every kind of purpose is served by the dissemination of such news. Indicatively, these may be political, economic, social, humanitarian or terroristic. The influence of the recipient may lead to subsequent manipulation, terror, prejudice and marginalization. Similarly, especially when false news refers to individuals or organizations, they can cause non-material damage to them, in the form of slander, prejudice, hate, and positive feelings, without relying on true facts.
Methods of dealing with the phenomenon
In conclusion, misleading news on the Internet, having many points in common with those used in more “disconnected” environments, is even more disastrous. How can we therefore get protected against dubious validity news? The most effective tool for this is undoubtedly the use of critical thinking. The better you filter / analyze the content you encounter on the Internet, the easier it is to identify inconsistencies and misconceptions.
For this, you can ask the following:
– What is the source of the news?
– Who is the author / writer?
– Are the above credible?
– When was the news published? Is it recent / crucial?
– Published in more media / from different sources?
– Is the content objective or subjective / biased?
The awareness of the phenomenon, its features, and the ways in which it spreads, is the first precautionary step against news made up for misleading and malicious purposes.

Artificial intelligence in the courts: Myths and reality
By Eleftherios Chelioudakis
Many people think that the term “artificial intelligence” is synonymous to technological development, whilst it is frequently presented as the hope for resolution of serious problems, which plague our societies.
Through its articles, our team has tried to explain to our readers the term “artificial intelligence”, as well as the reason why we should be cautious regarding the developments in this sector.
Through this article we will focus on the frenzy regarding artificial intelligence, we will find out if the idea of its use on the area of justice constitutes a new and innovative approach and at the end we will note issues which merit particular attention. However, it is not the first time that Homo Digitalis focuses its attention on the use of artificial intelligence on the area of justice as we have already hosted an article regarding philosophical issues, which concern the replacement of the judiciary by machines and by means of Machine Learning.
In the information society we live in, the increased use of computers and the internet result in the rampant growth of modern human’s digital footprint. Smart devices, like smartphones, wearable systems which record our sporting activity and our health status, even coffee machines, fridges and toothbrushes, simple household appliances, collect and process a flood of information for its users and demonstrate aspects of their daily life and their personality.
The volume of information produced is so enormous, that it suddenly adds value on the gathered information. Large firms base their business model on the exploitation of these information. The goods and services of these firms are provided “for free” and users “pay” with their personal data, which are analysed and shared with third parties in order to create targeted advertisements, which will lead to profit-making.
As societies, we are heading to the belief that collecting information will bring us closer to acquiring knowledge. As human beings we do not have the intellectual capability to process the vast amounts of information arising; thus, we are placing our hopes on the calculating force of machines. The key that opens the door to control diseases, to combat crime, to better administration of our cities and to our personal well-being is data analysis, the identification of correlations between them and the production of forecasts and comparisons. At least this is the idea we are called to embrace.
Thus, sectors like artificial intelligence, which two decades ago were considered outdated and ineffective, such as the sector of machine learning, suddenly attracted more attention. The modern smartphone, the use of the internet and the computers, the improvement of processors, as well as the increased capacity of the means’ of data storage, gave to the algorithms of machine learning the requisite fuel; large amounts of data.
Serious problems in various sectors, such as health, local governance, self-improvement, transports and policing can be resolved as if by magic through the analysis of the amount of information gathered. Certainly, the judicial system could not be absent from these sectors.
At this point, we should distinguish between the use of mechanisms and artificial intelligence tools for supporting court administration (such as the use of Natural Language Processing tools, which aims to the automation of bureaucratic procedures and rapid writing, registration and analysis of judgements and other documents), and the use of the said mechanisms and tools for the granting of justice and the influence on the decision-making procedure from judicial authorities. This article does not address the first category, as the challenges and restrictions arising there, are the same for other application areas of Natural Language Processing technology. In contrast, the article focuses on the second category and the idea that artificial intelligence mechanisms could abet judicial authorities in the decision-making procedure.
The truth is that the idea of using technology in the decision-making procedure in the area of justice is not pioneering nor innovative. On the contrary, it is a past idea that has appeared and has been used a lot in foreign judicial systems, such as Canada, Australia and U.S.A. already since the end of the past century, while it is commonly known to the similar sector of judicial psychology and psychiatric. Systems such as “Level of Service Inventory-Revised (LSI-R)” and the “Correctional Offender Management Profiling for Alternative Sanctions (COMPAS)” were used as risk assessment tools to help the judge in various stages of the criminal proceedings, such as the suspect’s detention, conviction, imposition of a sentence and the decision to release sentenced on behaviour before serving his/her sentence. Frequently, technologies, which just implement mathematical and statistical methods of risk assessment, are baptised by their creators and media as artificial intelligence. Analyses have been repeatedly carried out over the last few decades for these systems and the critical review according to their solvency and their effectiveness differ depending on which agency finances the related researches.
While the uncertainty about the use of different technologies on justice area has been strongly expressed the Council of Europe (1. Parliamentary Assembly (PACE), Recommendation 2101 (2017) 1, Technological convergence, artificial intelligence and human rights, 2. Parliamentary Assembly: Motion for a recommendation about Justice by algorithm – the role of artificial intelligence in policing and criminal justice systems, and 3. European Commission for the Efficiency of Justice (CEPEJ): European Ethical Charter on the use of artificial intelligence in judicial systems) and the European Union (1. European Commission: Communication on Artificial Intelligence in Europe, and 2. European Commission’s Hight-Level Expert Group on Artificial Intelligence (AI HLEG): Draft Ethics guidelines for trustworthy AI) through their actions during the past two years, explore the possibility of the use of artificial intelligence mechanisms in the area of justice from their Member States.
Although we are against the introduction of artificial intelligence mechanisms into the decision-making procedure and we believe that this approach is not the solution to any problem from those besetting the judiciary, because of the frenzy which prevails during the last few years, we consider it important to mention briefly the main issues emerging from the assumed use of artificial intelligence in the field of justice- especially in criminal proceedings. The enumeration which follows is indicative:
- Decision-making solely based on automated processing: as provided by Article 11 of Directive 2016/680, taking a decision based exclusively on automated processing, which produces unfavourable legal effects concerning the data subject or largely affects him, is forbidden. Except in the cases, where the law allows the decision at issue, providing appropriate safeguards to ensure the data subject’s rights and freedoms, as at least the right for human intervention. It is, therefore, recognisable that the human factor is an indispensable component in the decision-making procedure.
- Risk of discrimination and quality of the data used: Artificial intelligence mechanisms, which are trained on the basis of processed data are dependent on the quality of these. In simple terms, the provisions for my future behaviour will be based on other people’s data based on which the algorithm has been trained. If the quality of data used during the training is low, or if any prejudice underlies these data, predictions are condemned to be insolvent. They may also be illegal if they are based on personal data, which are by their very nature particularly sensitive as defined in Articles 10 and 11 of Directive 2016/680.
- Technical training of judges and lawyers: Before the use of any artificial intelligence mechanism on bearings and the decision-making processing, it is a reasonable prerequisite that professional users of this mechanism who use it on daily basis, are familiar with technology. Unfortunately, most judges and lawyers have a poor technical knowledge and do not have programming capabilities or basic knowledge on the capabilities and the functionality of the different artificial intelligence mechanisms. In light of the above, a basic training of the law practitioners is considered necessary, already starting from bachelor studies and a retraining of judges during their education in judiciary.
- Clear rules concerning data ownership used by artificial intelligence mechanisms: Under no circumstances should companies which have created the artificial intelligence mechanism, have access to the personal data of the people tried and the people condemned, nor use them commercially nor for research purposes. Justice cannot be a profit-making sector.
- Concise and explicable way of the way of operation of the artificial intelligence mechanism: The area of justice is interwoven with the principles of transparency and impartiality. Therefore, if a judge bases, even partly, his decision on a prediction of some artificial intelligence mechanism, it should be possible to explain the reason, why the mechanism has come to this prediction. If this explanation is not possible, the judge’s decision which was based on it, does not comply with the principle of transparency and will not be considered as impartial. At this point, it should be underlined that popular and complex mechanisms, such as neural networks, make particularly difficult to meet this requisite.
- Checking artificial intelligence mechanisms’ effectiveness by independent authorities: A scheduled and regular assessment of the validity of the predictions, made by artificial intelligence mechanisms, should be conducted. An independent supervisory authority with sufficient financial resources and personnel with a high level of knowledge and experience is the ideal body for the fulfilment of this task. The assessments of this authority should be based on both quantitative data, such as statistics, arising out of the efficacy of predictions of artificial intelligence mechanisms and qualitative factors, such as the conclusions taken into consideration case-by-case.
Undoubtedly, the implementation of artificial intelligence mechanisms in any sector of modern life is a complex issue, requiring a multidisciplinary approach. In any event, it is not merely a legal issue. On the contrary, it has intense ethical and social aspects, which require serious contemplation. Rapid technology development is of the utmost importance for the improvement of our life quality and for sure we should integrate it in our society. However, its inclusion should be done with thorough preparation and planning. Only then we will experience new technologies’ benefits and we will severely restrict challenges and dangers for the protection of Human Rights.