
It is raining technological advancements
Artificial Intelligence is constantly evolving. What can we do to keep it under our control?
By Konstantinos Kakavoulis
In Saudi Arabia it is believed that it scarcely rains. The truth is that it rains quite often. However, due to high temperatures, the raindrops evaporate before they reach the ground and people become aware of them. People feel the rain only on the rare occasions, when it rains a lot. On these occasions, there is also frequent flooding.

Picture from flooding in Saudi Arabia. Source: SahilOnline
The evolution of Artificial Intelligence does not differ much from the example of the rain in Saudi Arabia. We tend to believe that Artificial Intelligence evolves rarely. In reality, it is constantly evolving.
The small improvements which are achieved daily do not reach us. Only on the occasion of an important achievement we realize that Artificial Intelligence is indeed advancing. These big technological “booms” frighten us, like heavy rainfalls frighten the Saudi Arabians.
We are not used to them, because they rarely occur. If we paid more importance to the small progress achieved daily, we would not be that astonished. We would understand that technological achievements are the logical consequences of such progress.
The question is: what can we do to avoid the “flooding”, which might stem from the evolution of Artificial Intelligence?
Stuart Russel, one of the most prominent researchers in the field of Artificial Intelligence, had noted: “Let us assume that there is 10% possibility that we achieve Super Intelligence within the next 50 years. Shouldn’t we start working now, so that we make sure that we will be able to hold Super Intelligence within our control?”
Indeed, there is no reason for us to wait until the “floods” come to face their consequences. We can create infrastructure, which will protect us. This infrastructure is nothing else than a regulatory framework, which will not restrict technological progress, but will protect the people.
Artificial Intelligence does not advance as fast as we might fear. The inventors of Artificial Intelligence as we know it today, believed that within 10 years they would be able to create a computer which would be able to beat a world-class chess player. This took 40 years to happen.
They also thought that in 10 years they would be able to create a computer, which would be able to understand human speech and respond to it in any existing human language. They believed this back in 1956. Until today it has not been fully achieved, although translating applications are constantly evolving.
Finally, in the field of Computer Vision, the experts estimated that teaching a computer program to classify photos according to their content was an appropriate summer project for a Master student.
However, 62 years later, although Computer Vision constitutes one of the biggest success stories in Artificial Intelligence, this task has not been adequately fulfilled.
Of course, there are examples of achievements of Artificial Intelligence which have been accomplished a lot earlier than expected. For instance, two years ago the experts estimated that for a computer to be able to beat a champion of the board game Go, 10 more years would be needed. Nevertheless, last year the AlphaGo computer managed to beat the Go world champion in all of their three encounters. The achievement of AlphaGo opens up new opportunities for Artificial Intelligence but is the exception rather than the rule.
Therefore, we may have more time than we believe to get adequately prepared for the progress in Artificial Intelligence. We might neither know what the future holds nor be able to predict it. However, we should not demonize the progress of Artificial Intelligence under any circumstances.
Scientists often bear responsibility for that; they often discourage the public from getting involved with Artificial Intelligence topics, claiming that since they do not know how Artificial Intelligence works, their opinion should not be taken into account. The progress in Artificial Intelligence influence the lives of us all. We should all participate in the discussion on their use. The first step for this to get informed.
If the inhabitants of Saudi Arabia could see the raindrops, before they evaporated, the might have taken more appropriate safeguards to get protected from the floods. If we know that it is “raining” technological advancements, it is worth following them; this way we can take all the appropriate measures on time to keep the situation under our control.
Under no occasion should we try to predict or criticize the progress in Artificial Intelligence. When we try to do so without possessing the adequate knowledge, it is reasonable that scientists do not seriously taken into account our opinion.
Through the State and the pertinent authorities we should be able to explain to the scientists which of the methods they use are socially acceptable and which are not. We should care about the results of their research -not the results we deem possible, but the real results- and see if we consider them acceptable. The State should legislate on this direction, taking into account the public opinion and the ethics it stands for.

From imagination to reality and back to imagination
by Nikos Giannaros*
The history of Artificial Intelligence as something achievable coincides with the history of computer evolution. The first theories for the development of systems with Artificial Intelligence capabilities came out back in the 1950s. Only man possesses such capabilities and could be able to teach a computer system to take autonomous decision and act as a thoughtful being.
The initially theoretical approach of Artificial Intelligence was directed to the creation of the necessary tools for a computer to act like the human brain.
These tools were based on logic and semantics, which constitute the prominent tools with which the human brain thinks and acts depending on the stimulus it receives. In this context, there have been efforts to standardize logical rules and correlations, which led to the creation of tools such as Logical Programming.
The basis of Logical Programming is the provision of basic entities to a computer system, so that with the application of a procedure of creation of logical conclusions, the system will be able to take decisions, imitating the procedure followed by the human brain.
This approach is based on the “up to down” logic. The system is supplied with the total of the requisite knowledge and the endeavour focuses on the way with which it will manage and combine properly this knowledge.
It soon became obvious that this kind of approach can offer limited practical solutions, because are not harmonized with the fundamental functional principles of a computer. The computer in its core is a machine, which can process mathematical calculations with great speed. There was a need for an approach which would work the other way round; the “down to up” approach.
This approach focuses on the endeavour to modelize a problem of -apparently- logic to a pure mathematical problem. A mathematical problem can be solved by using certain procedures with clearly determined steps, on which the computer is highly efficient. The outcome is also easy to classify, to categorize and be interpreted by the computer.
This finding led to the evolution of Machine Learning since the 1980s. This approach aims at modelizing through math certain human actions, so that a computer can conclude to the same result.
The most notable of these problems include the recognition of voice and image, processing of a human language into written form, robotics, forecasting, etc. Machine Learning uses the power of computers, their incomparable calculating capability, to make good use of big volumes of data to learn successfully to take decisions such as the ones taken by humans.
The models used are based on the way of functioning of the human organism (neuronic networks, genetic algorithms), of other living organisms (particle swarm optimisation, ant colony optimisation, bees algorithm), on applications of probability theory and of other field of Mathematics.
The various approaches which result to tangible algorithms, which can be carried out be a computer, that does not need any special structure or design, was revolutionary for Machine Learning.
Machine Learning consists of 3 main fields:
– Supervised Learning;
– Unsupervised Learning and
– Reinforcement Learning, which constitutes a combination of the other two.
The notion of Supervised Learning is the simplest of the three; the computer is provided with an appropriate training data set to get trained on the work which we want to assign to it.
The most common example for Supervised Learning is the provision of photos of men and women to a computer; on the photos there is a tag clarifying whether the photo depicts a man or a woman. A successful training will result in the computer being able to recognize the sex of the person depicted in any photo, since it will have been trained in classifying the data it receives.
In order to achieve this, the computer is provided with many features for every sex. Therefore, it becomes able to decide upon the sex of the person depicted in any photo with remarkable precision, based on the features appearing on each photo. This procedure requires that the determination and standardization of the features has been made by a human, specialized on the topic, before the training begins.
The feature extraction and selection constitutes a keystone for the successful application of Supervised Learning and has ended up being a whole, autonomous field.
Supervised Learning has long got away from the experimental and theoretical sphere and is used in commercial applications of voice, face and handwriting recognition, as well as in more specialized applications depending on the applicable field, such as customer segmentation, recommender systems/collaborative filtering, stock market prediction, preventive maintenance, etc.
Furthermore, with the appearance of Deep Learning, a sub-field of Supervised Learning, the feature extraction and selection can now be carried out by the computer itself; this results in further diminishing human intervention in the procedure. In the example of photo classification, the computer could, after having processed the photos it used as a training set, decide that lip shape is a more vital characteristic for the classification than eye shape and therefore give more importance to this feature.
In Unsupervised Learning, the computer does not first come through a training stage with use of data with determined features, in which the intended result is known. On the contrary, it is self-trained based on unknown data, which it can process.
The computer’s potential to work without first having been provided with knowledge, makes Unsupervised Learning look like extremely exotic and part of science fiction.
The truth is that in this case also, the applicable models make use of the computer’s ability to compare things and decide the level of similarity between them.
The structural difference with Supervised Learning is that the computer does not “know” the qualitative interpretation of the produced result. In contradiction to the example of Supervised Learning, an algorithm of Unsupervised Learning, which can classify photos of people according to their sex, can do so with equal rates of success, but does not know which category belongs to “man” and which to “woman”.
Unsupervised Learning has also many commercial applications. These are often in fields like the ones of Supervised Learning. However, as the power of computer systems is rapidly evolving, the ability of a system to be self-trained will replace the onerous human preliminary work with one more automated procedure. A perfect example for Unsupervised Learning is the ability of a computer to classify vegetables and fruits according to their shape, their size and their colour, without having first been trained to do so.
Finally, Reinforcement Learning constitutes a combination of the other two methods and is mostly used in robotics. The robot tries to carry out the instructions with which it has been trained in the best possible way, but on the same time enjoys some freedom to decide to deviate from these instructions. This might result in an even better result than the one already achieved.
Applications of Reinforcement Learning, such as self-driving cars, are in the anteroom of commercial application. Moreover, the various robots, which are used as human assistants, apply successfully the model of Reinforcement Learning, since their behaviour evolves based on the various stimulus they receive from different people with who they discuss.
It is obvious that Machine Learning is already here. It constitutes a reality and part of our everyday lives and not a science fiction plot. Many projects which seem evident, such as the recognition of the plate of our car in the airport parking, the digital help assistants in the phone centre of banks, which recognize our voice instructions, the applications of recognition of the music track we listen to (such as Shazam), the advertisements and the suggested posts in social media (such as Facebook, which combines the posts we open with the history of our search engine to show us relevant advertisements), the security applications, which activate video recording when a man approaches the door of a shop out of working hours, constitute a reality thanks to Machine Learning.
The fact that it is impossible that a person carries out the same tasks in the same time, justifies the label of “Artificial Intelligence” that is given to such applications.
On the other hand, the fact that computers carry out these tasks mechanically, without the result having any meaningful result for them and without them deviating from the way they carry out a task if they continue receiving the same stimulus, means that Machine Learning is still far from becoming real Artificial Intelligence; there are many unknown steps until this happens.
Computers carry out the task they have been assigned to without judgement and without feelings, with no possibility to deviate from what they have been designed to do. They can carry out the the tasks assigned to them in an increasingly better fashion, but they are not able to “start a revolution” and change their way of operation. A future in which humans and machines will be equal is definitely far away. The reality of Machine Learning though, is here.
*Nikos Giannaros is an Electric and Computer Engineer. He specializes in Artificial Intelligence and Machine Learning. He is interested in the sociopolitical impingements of technology.

Statewatch announces the establishment of a new observatory
Statewatch is one of the most prominent NGOs operating in the European plane. Established in 1991, it is an organization of lawyers, academics, journalists, researchers and other activists, focusing on the monitoring of activity of the Council of Justice and Home Affairs (JHA).
JHA is one of the 10 councils forming the Council of the European Union. It consists of the Ministers of Justice and the Ministers of Home Affairs of all the EU Member States. The Ministers of Justice work on judicial cooperation in civil and criminal cases, as well as in cases of fundamental rights violations. The Ministers of Home Affairs are responsible, among others, for immigration, border management and police cooperation.
The activity of JHA is intrinsically linked with fundamental rights. In this context, Statewatch establishes observatories from time to time. Every observatory focuses on a different topic of JHA’s activity. It records all the latest updates, collecting policy proposals, existing legislation, analytics, news from the media, campaigns, etc.
On 12 July, Statewatch announced the establishment of a new observatory. This observatory will record the latest updates on the interoperability of JHA’s databases. The notion of interoperability might seem hard to understand. However, it simply refers to the possibility of sharing data between two or more databases.
Statewatch warns that the interoperability of JHA’s databases will create a collective database, which will include all the existing and future JHA’s databases. Thus, it will be possible to combine biometric data (such as fingerprints) and other personal data, which are contained in JHA’s databases through one sole search.
As underlined by the Director of Statewatch, Mr. Tony Bunyan, “the time to ring the alarm bells is not when Big Brother is in place but when there are the first signs of its construction”.
Homo Digitalis will keep informing you on the latest news on the issue.You can read the press release by Statewatch here.

Three important studies examine the threats to free, impartial and transparent elections
The UK Information Commissioner’s Office (ICO) published today three new studies regarding personal data analysis for the promotion of political campaigns.
The first report is entitled “Democracy Disrupted? Personal information and political influence”. The objective of the study is to shred light on the use of personal data in the context of political campaigns. Moreover, this report includes ten (10) proposals for the legal and transparent use of personal data during political campaigns by political parties of the UK in the future.
The second report is entitled “Investigation into data analytics for political purposes – update”. The objective of the study is to inform the public on the new findings of the Authority in the context of its investigation, initiated on May 2017, regarding the processing of personal data in political campaigns. This investigation was launched subsequently to claims for secret processing of voters’ personal data and use of targeted political advertisements during the referendum on Brexit.
Furthermore, the report includes an analytical reflection on the recent regulatory acts of the UK regarding companies involved (Facebook, Cambridge Analytica, etc.), political parties, data brokers, organizations supporting political campaigns, etc. It is for sure that one of the latest acts of the Authority, which has caught the attention of the press, is the notice to Facebook, with which it informs the company of its intention to issue a fine of 500,000 pounds against it (around 565,000 Euro) for the violation of the Data Protection Act of 1998. It must be underlined that this fine was the maximum, which could be issued according to the then legislation.
The third report was concluded in cooperation with the investigation team DEMOS and is entitled “DEMOS report – The future of political campaigning”. This study analyzes the modern and future trends regarding the way in which various data are used during political campaigns.
Furthermore, the report describes the methods, which are widely known in the online advertising sector, and the way in which these methods are already being used or might be used in the near future for political campaigns. Finally, it mentions the risks and challenges which stem from data analysis for political campaigns.
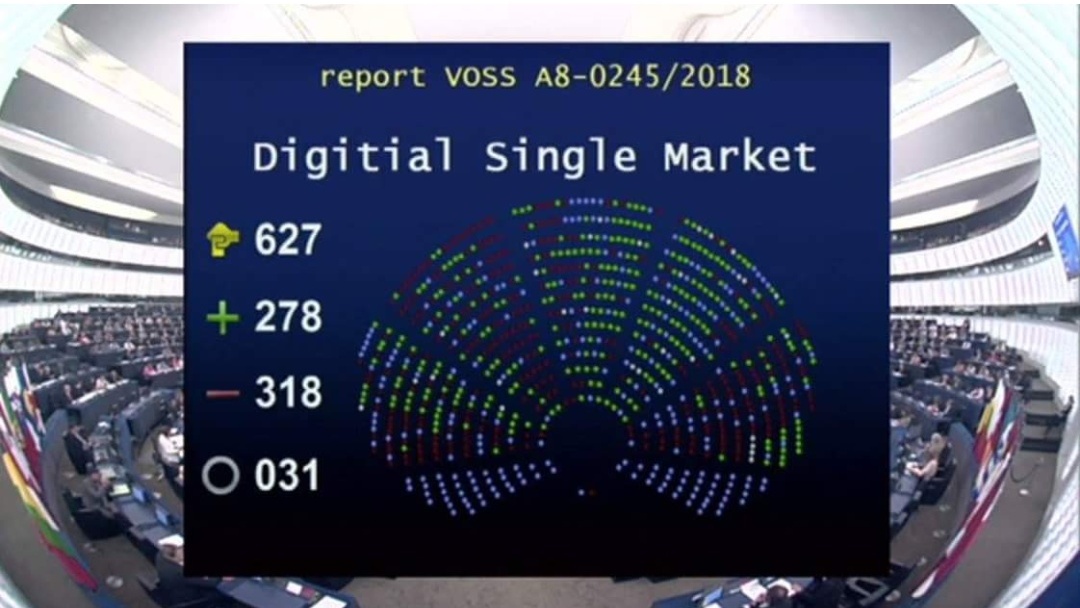
EU: Freedom of online expression was saved!
The European Parliament rejected the Proposal for a Directive on Copyright in the Digital Single Market
5 July 2018 is a fantastic day for freedom of online expression and information.
Today, the European Parliament rejected the Proposal for a Directive on Copyright in the Digital Single Market with 318 against, 278 in favour and 31 abstentions.
As analyzed by Homo Digitalis, the dangers which could stem from this Directive were significant.
Consequently, the negative vote of the Proposal is a tremendous victory for freedom of online expression and information. The Internet is fortunately not going to change!
According to the legislative procedure, the Proposal for the Directive will return to the Legal Affairs Committee of the European Parliament, which will suggest amendments and will introduce the new Proposal to be voted in the plenary of the Parliament in September.
Homo Digitalis will keep informing you on any updates.
Today is a day of joy for all European citizens, who use the Internet.
For us, the joy is double, because part of this result is your accomplishment.
We would like to thank you all for embracing the endeavour of Homo Digitalis for the rejection of the Proposal, through the pressure put on the Greek Members of the Parliament through emails.
Let us not forget the words of the famous writer Helen Keller: “Alone we can do so little. Together we can do so much.”
We will all together keep fighting for our digital rights.
Thank you.

FRA published today the summary of his second report on surveillance by the intelligence services in Greek
The European Union Agency for Fundamental Rights (FRA) published its second report on the protection of fundamental rights in the context of surveillance by national intelligence services in October 2017. The title of the report in Greek is «Παρακολούθηση από τις υπηρεσίες πληροφοριών: εγγυήσεις και μέσα έννομης προστασίας των θεμελιωδών δικαιωμάτων στην Ευρωπαϊκή Ένωση – Τόμος ΙΙ».
For those who are not familiar with its work, FRA was established with the objective of offering independent and well-documented assistance and experts’ advice regarding fundamental rights in the institutions of the EU Member States. It is an independent EU institution, funded by the EU budget.
Considering the growing threats of terrorism, the cyber-attacks and the sophisticated transboundary criminal networks, the scope of the intelligence services has become more emergent, complex and international and the services may interfere gravely with fundamental rights.
The report of October 2017 is the second report published by FRA, subsequently to the request by the European Parliament for a thorough examination of the consequences of surveillance on fundamental rights. It is a continuation of the first report by FRA, published in 2015. This first report examined the legal frameworks on surveillance in the 28 EU Member States and analyzed them through the perspective of fundamental rights. In this way, the first report by FRA presented a comparative analysis of the legal framework on surveillance in the whole of the EU. The Greek summary of the first report is available here.
The second report is an updated version of the 2015 legal analysis, which also includes long interviews with various experts of certain EU Member States. It also includes 16 FRA opinions, which are based on the main findings of the report.Today, the Greek version of the summary of the second report was published on FRA’s website and is available here. It is worth noting that the Greek version of the summary is one of the first available translations in official EU languages.

Freedom of online expression and freedom of information need you!
You use the Internet on a daily basis to communicate, to get informed and have fun. But Internet as you know it might cease to exist, if you do not take immediate action.
What happened?
On June 20, 2018 the Legal Affairs Committee of the European Parliament voted in favour of the Proposal for the Directive on Copyright in the Digital Single Market.
The proposed Directive aims to harmonize the legal provisions in the Member States regarding copyrights, taking particularly into account the digital and cross-border uses of the protected content. In simple words, what the european legislator aspires to achieve is that all EU Member States are on the same page regarding copyrights in the contemporary digital single market. Everything seems fine up to here.
Nonetheless, the provisions of the proposed Directive and especially Article 13 are not safe from blunders and could jeopardize freedom of online expression and freedom of information.
Article 13 requires that Internet platforms use filters for any information uploaded by the users on the platform, in order to avoid copyright infringements.
What does this mean?
Content-recognition technologies will filter the posts of the Internet users to ascertain whether there has been a copyright violation in the content of the posts under question. Subsequently, based on the said filtering, the posts will be approved or prohibited. The risks from such a practice for freedom of online expression and information are obvious.
1. The Internet platforms will have excessive power
Under the new scheme platforms will have to filter the content, which they host, without any complaint regarding a copyright violation. Until now, legislation provided that content which violates copyright would get banned from the platform according to a procedure. This procedure commenced subsequently to a complaint filed by the alleged copyright owner. Now, any post will be subject to this filtering.
2. The available technology is not able to recognize posts which are made in the context of parody, criticism or reference for research and commentary
Although technology evolves rapidly, the available filtering mechanisms are not able to recognize the difference between legal and illegal content use, which is subject to copyrights, and which is used in research, commentary, even for criticism or parody (i.e. reference to artistic excerpts for commentary, reproduction of speeches for informing the public for current affairs, generation of parodies of a film -such as memes- or parodies of songs.
Therefore, the creativity of Internet users and freedom of online expression and information will be inevitably restricted. Additionally, the said filtering mechanisms will have to be supported by a whole army of employees of the Internet platform in question. These employees will proceed to a second phase of monitoring of all the posts for which the filtering mechanisms will have concluded that they infringe copyrights.
This is definitely a costly and time-consuming procedure and the extra cost for the extra employees might fall on the Internet user through a rise on the prices for Internet services or the introduction of annual or monthly fees in the various Internet platforms.
What can I do to prevent this?
On July 5 the European Parliament’s plenary will vote on the proposed Directive. Send today and email to the Greek Members of the European Parliament (MEPs) and call them to vote against the proposed Directive on Copyright in the Digital Single Market.
A full list with the contact information of all the Greek MEPs can be found here.
Remember that every email counts. We must unite our voices and request all together from the Greek MEPs to vote against the proposed Directive. The preservation of freedom of online expression and information concerns us all and is a vital prerequisite for the proper functioning of democracy.
If you want to save time, you can use the following template. However, we suggest that you personalize your message as much as possible and express also your own concerns.
“ Subject: Vote against the proposed Directive on Copyright in the Digital Single Market
Dear Ms/Mr (Name),
I am sending this message because on July 5, the European Parliament plenary will vote on the proposed Directive on Copyright in the Digital Single Market.
This act will drastically change the form of the Internet, as we know it, for the worse. It will restrict significantly the right to freedom of online expression and information for all Greek and European Internet users.
More specifically;
Creativity and freedom of speech will be significantly damaged, since algorithms are not always able to recognize the difference between legal and illegal use of content, which is subject to copyrights, and which is used in research, commentary, even for criticism or parody. If the use of this content is regulated by automated systems, which take decisions the letter and not the spirit of law, creativity and freedom of online speech, will be inevitably restricted.
There are no appropriate technical means to implement Article 13. There is no recognition technology, which can monitor successfully all the forms of content which are included in the proposed Directive (text, audio, video, images and software).
Therefore, it is absurd to expect from the courts of the 27 Member-States to constantly judge on which would be the most appropriate technical means for the implementation of the proposed Directive on a case by case basis.
The Internet service providers should not become responsible for the implementation of the copyright legislation, as prescribed by Article 13. In order to achieve their compliance and avoid fines and sanctions, the companies will prefer to become overprotective in regards to copyright, thus restricting freedom of expression.
Providing the companies with the right to delete content for copyright violations will give them excessive power, since there is no provision for the protection of Internet users against such deletions -even if their content is legal.
Taking into account all the above, I call you to vote against the proposed Directive. In this way, the text of the proposal will become subject to review, in order for the requisite balance between copyright protection and protection of freedom of online expression and information to be found.
With best regards,
(Name) “

Homo Digitalis sends an e-mail to the Greek members of the European Parliament
On the 20th of June 2018 the Legal Affairs Committee of the European Parliament voted in favour of the adoption of the Proposal for a Directive on Copyright in the digital single market.
The provisions of this proposed Directive, and more specifically the Article 13 that it includes, could be proven hazardous. The aforementioned legislation will change the Internet as we know it, only for the worse, setting serious limitations to freedom of expression and information of Greek people as well as all the internet users inside the European Union.
Before the voting process of this proposed directive, Homo Digitalis had contacted Mr. Chrysogonos, the only Greek representative in the Legal Affairs Committee, suggesting that he should examine in detail the Article 13 of the Directive. Mr. Chrysogonos proposed its amendment during the voting session. Unfortunately, his proposal was denied and the text was adopted from the Legal Affairs Committee. Read more about this here.
On the 5th of July the plenary of the European Parliament will be called to vote on this proposed Directive. If the voting goes through and in favour of this Directive, it will soon become a reality.
Thus, the last chance of reviewing this text, in order to ensure the required balance between the protection of copyrights and freedom of expression and information on the internet, is now.
Homo Digitalis noticed via e-mail all the Greek members of the EU Parliament to vote against this directive. See the e-mail in Greek here.
European citizens must act now and request from the Members of the European Parliament of their countries to vote against this proposed Directive on the 5th of July and protect the freedom of expression and information. Only if we unite our forces we will be able to send a loud and clear message.
Every e-mail to the Members of the Parliament is of utmost importance. Take action!

Social Media
By Emmanouil Mandrakis*
Following the Cambridge Analytica scandal, most social media users, particularly Facebook users, are concerned for the protection of their personal data. Notably, many decided to delete their profiles, either driven by fear or by a need for reaction. A considerable amount of users seem to be indifferent for the violation of their privacy or are not aware of what is happening.
In any case, social media have proven to be useful when it comes to networking and communication. For their users to be able to enjoy these services, without facing the pertinent dangers, they must always get informed. On the other hand, social media and their access in private life must be regulated and monitored.
What happened with the Cambridge Analytica scandal
The Cambridge Analytica scandal came to light when it was disclosed that the personal data of millions of Facebook users were used for political propaganda by the social media company. It is estimated that between 2014 and today (2018), Facebook has gathered personal information by 87 millions users. It has been claimed that this information has been used on a fee for influencing the public opinion in political issues. The users did not know if and how their data were used, while most of them never granted their consent. (Kevin Roose, 2018)
This came out by a Cambridge Analytica employee, who denounced the abuse of the data. The case has been brought to justice. At this point, arises the issue of whether the law has made provision for protecting the users and preventing corporations from violating the Internet users’ privacy. Moreover, the social media users must get informed and learn which conduct might lead them to confronting similar dangers.
Facebook as an entity offered the means for the development of applications for entertainment, briefing and various others objectives, which had access to personal data, in order to be more efficient. Applications such as quizzes requested access to data, which were not actually necessary for the quiz, such as personal data of the users’ friends. In this way, these applications gained access to data of people, who never consented, just because their friends were “careless”.
Can someone get protected?
Social media users must always get informed on how they can get protected. They must be cautious regarding the information they share, particularly when they share sensitive data or even their “digital self”. To begin with, they must be aware that if they decide to share information publicly, this information will be available to everyone.
This includes corporations, which might use this data for some objective, if not for profit. For instance, for most users, the profile photo is public and clearly depicts their face. This gives the opportunity to everyone to create a huge database with name, surname and biometric characteristics for face-recognition applications. The “Likes” made by the users in pages and posts provide sufficient information for someone that has access to them to know the users’ preferences and desires.
Apart from the obvious use for marketing purposes, it must not be underestimated that the social circle of a person might criticize it based on its “likes”, something that leaves considerable ground for stereotype-making. In the following table are illustrated the steps, that anyone can follow to protect this information.
Furthermore, social media users can control with who they share other sensitive information such as posts and location. Notably, the latter is used by insurance companies in order to avoid compensations for burglaries. (Pleasance, 2015) Therefore, users must post responsibly, particularly when they choose their post to be public.
The commodities of social media
Social media have undoubtedly earned their role in everyday life. They have brought communication and networking to a new dimension, in which a person can keep in touch with another from a long distance or remain in contact with its old schoolmates much more easily than in the past. As far as corporations are concerned, it has made product promotion easier and much more targeted.
This is not necessarily negative; we should bear in mind that the marketing cost is paid by the consumer in any case. Social media constitute a source of information but also misinformation. One must always crosscheck his sources. Social media are a commodity which is taken for granted and is offered for free, with the only price paid being the users’ personal data.
Consequently, users must always check what they pay each time for the services they enjoy and decide if it is worth it. They must be hesitant when an application requests access to irrelevant information. It is normal for a weather application to ask for the user’s location, but not for access to photos or “likes”.
* Emmanouil Mandrakis is an Electrical and Computers Engineer, specializing in Nanotechnology. He works in CSEM (Swiss Center for Electronics and Microtechnology) in Switzerland. He is interested in current affairs and credible information. He works on new technologies issues.